Search across events, members, and blog posts

DeepSeek just dropped V4 (preview) — two open-weights MoE models that push the frontier on cost-effective 1M-token context.
DeepSeek-V4-Pro: 1.6T total params (49B active) — flagship performance rivaling top closed models in reasoning, math, and agentic coding.
DeepSeek-V4-Flash: 284B total (13B active) — faster, cheaper, and highly efficient for everyday/agent tasks.
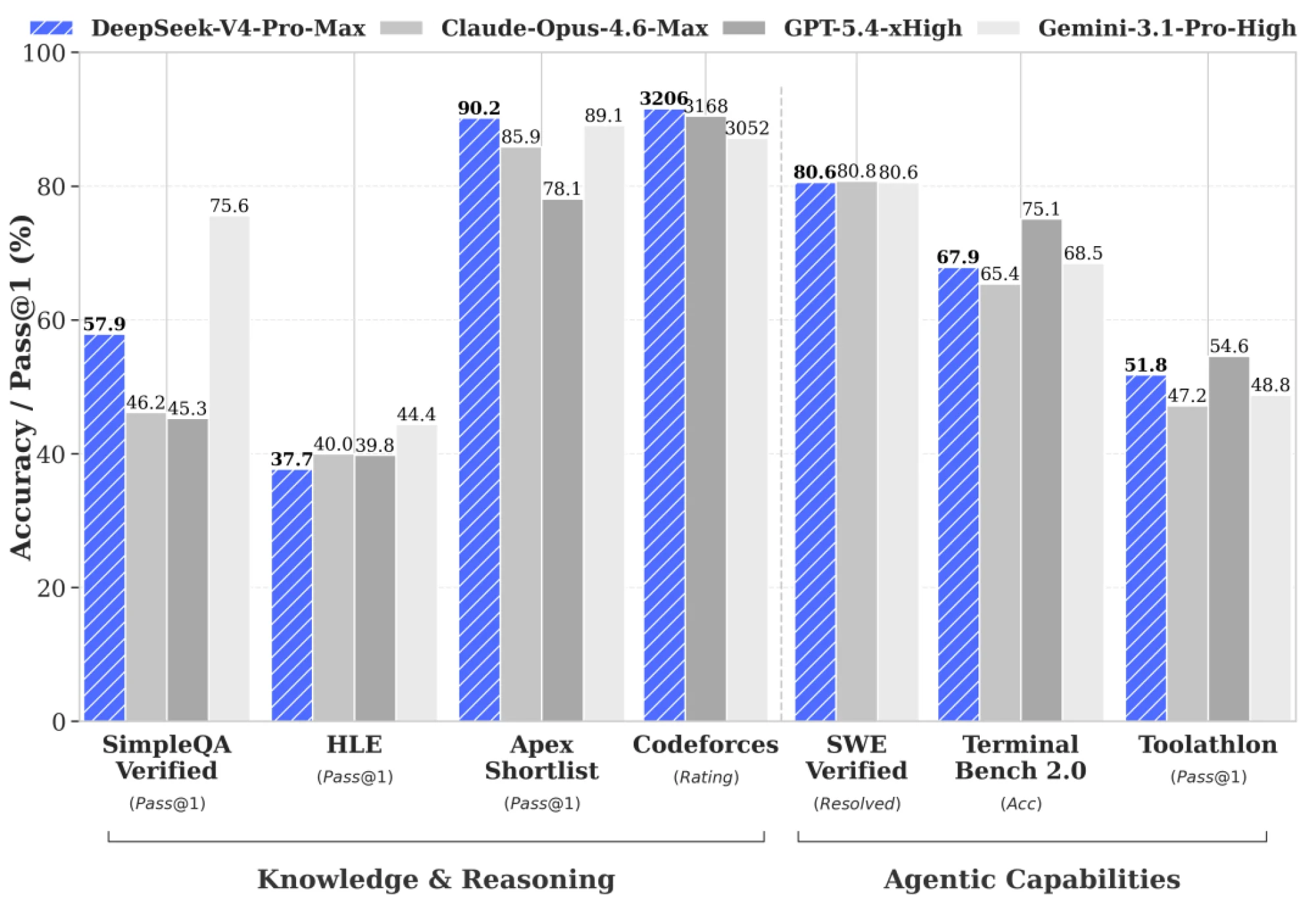
Both feature a new hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) that makes million-token contexts dramatically more practical (much lower FLOPs and KV cache than V3). MIT license, available on Hugging Face (base + instruct), and live on the DeepSeek API today.
The community is already praising the efficiency gains, strong coding/agent results (e.g., high LiveCodeBench / SWE-Bench scores), and rock-bottom pricing — especially with the ongoing Pro discount.
Sources: Official announcement, Hugging Face collection, Tech Report, tweet discount extended
This keeps the snappy, community-focused vibe while incorporating the accurate specs, architecture innovations, and current status. Let me know if you want tweaks, more benchmark details, or an expanded section!
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
Founder, Engineer
AI Socratic
Founder of AI Socratic

The most important AI news and updates from last month: Apr 15, 2026 – May 4th, 2026. updated on May 25th

GPT 5.5 [columns col=40,60]  [/col] OpenAI shipped GPT5.5 — an incremental but meani…

Anthropic: Natural Language Autoencoders (NLAs) [columns col=60,40]  [/col] <video s…