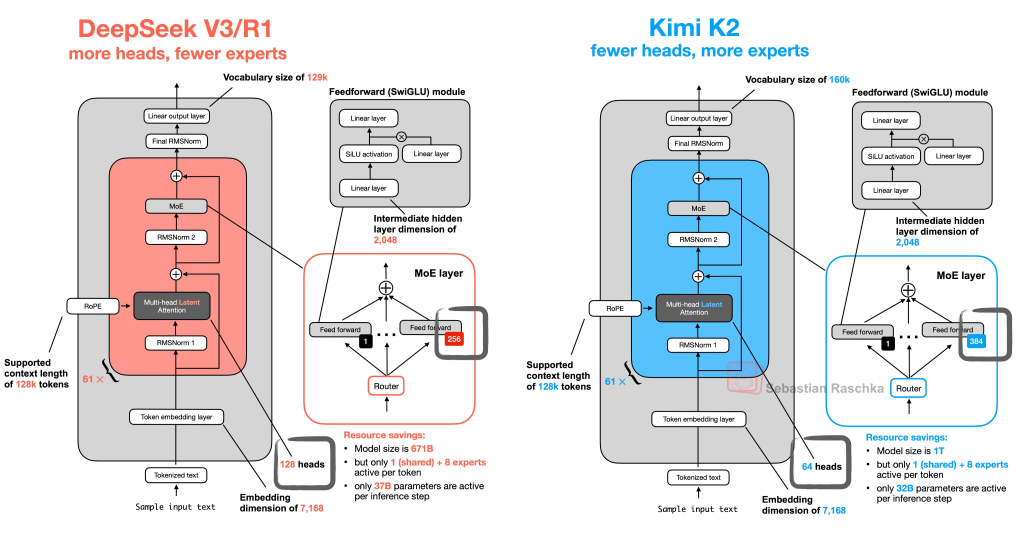
Kimi 2 is a new open source model from Moonshot, that uses a similar architecture of DeepSeek V3, with fewer heads, and more experts.
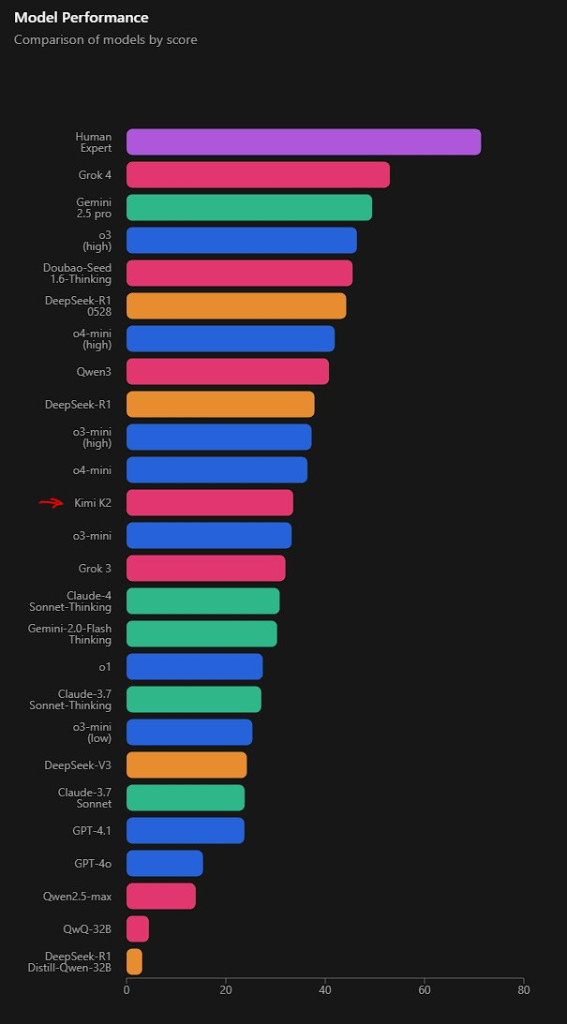
It's really cheap and fast, taking SOTA position on several benchmarks.
https://x.com/sam\_paech/status/1944276326598553853
Muon was one of the key to Kimi K2's success!
They replaced AdamW with a custom optimizer and then patched stability hiccups with MuonClip. Loss curve smooth across 15.5T training tokens. It keeps the model calm while it learns.
Muon keeps training stable because it treats every weight matrix as a single object and updates it with an orthogonalized step.

What is AdamW
Adam (short for Adaptive Moment Estimation) is a popular gradient-based optimization algorithm used to train deep learning model. It combines the advantages of two others optimizers: AdaGrad and RMSProp.
Adam Adapts the learning rate for each parameter by maintaining two moving averages:
- First moment (mean) - like momentum
- Second moment (variance) - scales updates based on recent gradient magnitudes.
The key differences with AdamW
AdamW, the usual optimizer, adjusts each parameter independently with first‑ and second‑moment statistics.
That per‑element rule is simple but it ignores how rows and columns of a weight matrix interact, it carries two momentum buffers, and its update size depends on the running variance of each element.
Muon, by contrast, looks at the whole matrix at once, keeps just one momentum, aligns the step with the spectral norm constraint, and then shares the same learning rate schedule that was tuned for AdamW.
The result is a more uniform, numerically safe update that trains in fewer floating‑point operations while matching or beating AdamW on every reported benchmark.
paper: arxiv.org/abs/2502.16982.
Comparison of Muon AdamW and Adam
Feature
Muon
AdamW
Adam
Update Type
Orthogonalized momentum on 2D weights
Adaptive (momentum + RMS)
Same as AdamW but mixes in weight decay
Weight Decay
Decoupled (via matrix-level updates)
Decoupled (explicit)
Coupled (less effective)
Adaptive LR
❌ (fixed LR + semi-orthogonal updates)
✅ Yes
✅ Yes
Optimizes
Only 2D weight matrices (e.g. linear)
All parameters
All parameters
Speed vs AdamW
Up to 2× faster on LLM pretraining
Baseline
Similar to AdamW
Generalization
Strong (from better conditioning)
Good
Slightly worse
Stability
High in large-scale training
High
Medium
Used In
Moonlight, MoE LLMs
GPT, BERT, T5, most transformers
Legacy use, some fine-tuning
Open Source
Yes (Muon)
Yes
Yes
More info here: https://x.com/rohanpaul_ai/status/1944079810386436505.
Fun fact, CEO @Kimi_Moonshot was the first author of XLNet and TransformerXL https://x.com/NielsRogge/status/1944035897231528112.

 Federico Ulfo
Federico Ulfo