Anthropic Reduces Claude Rate Limits During Peak Hours
Rate Limits Reduced 😢

"To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before."
Sources: tweet
 Federico Ulfo
Federico Ulfo


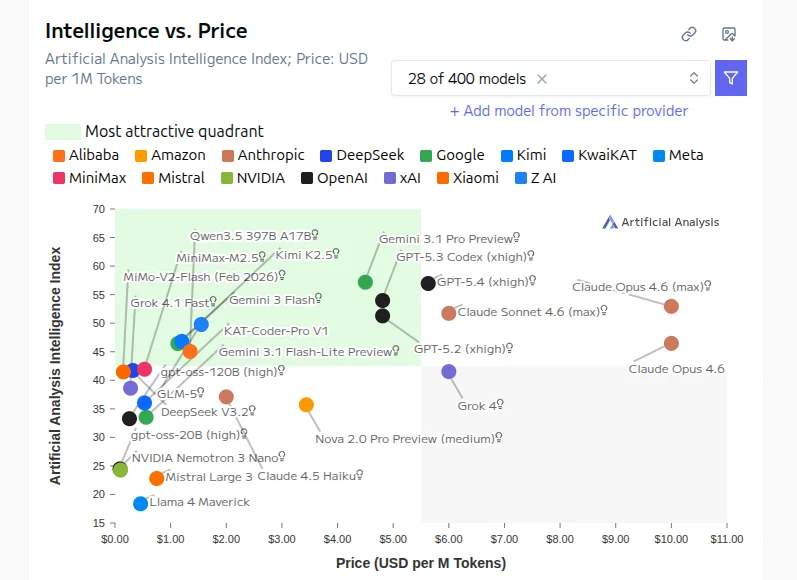 Sources:
Sources: 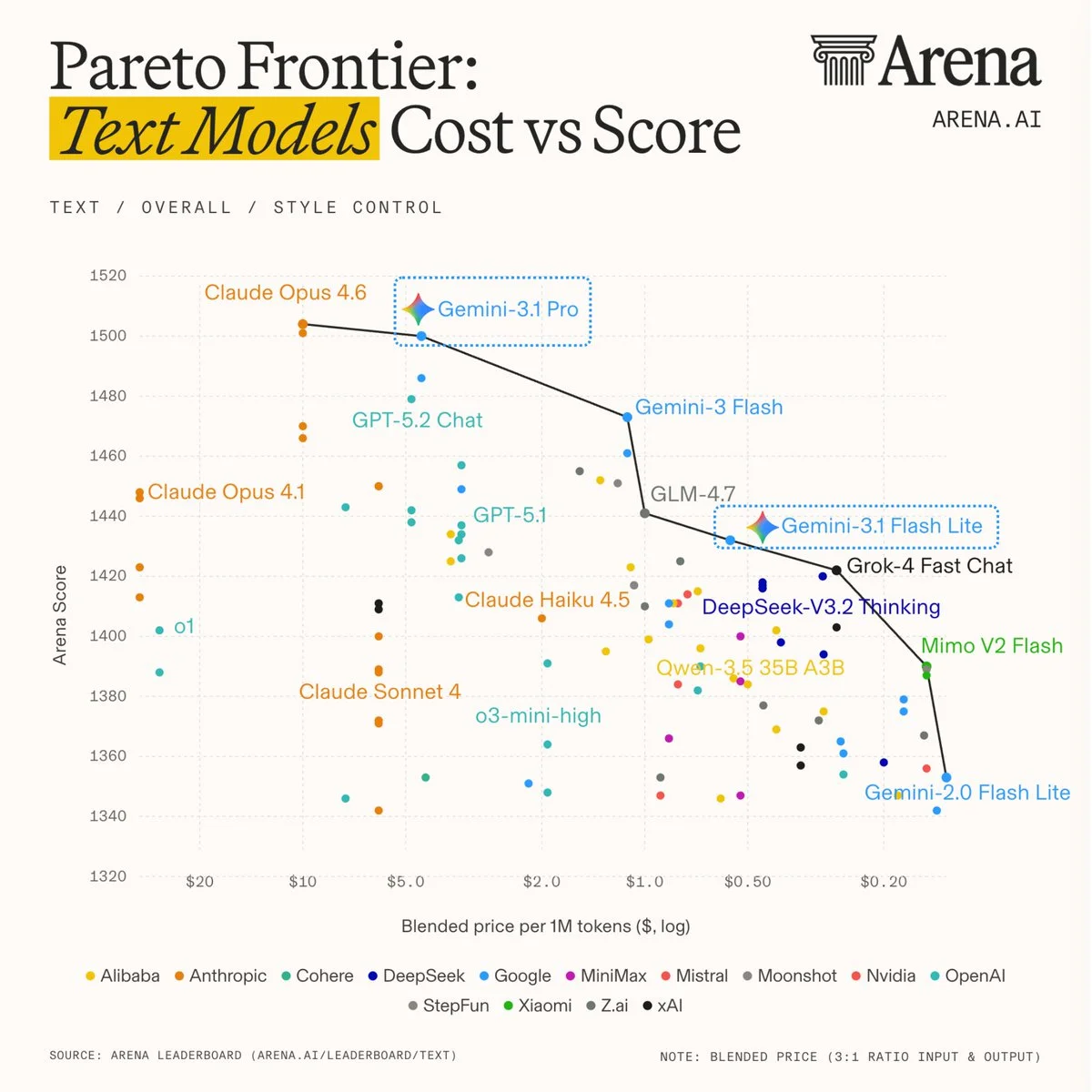 Sources:
Sources: