DeepSeek mHC: Manifold-Constrained Hyper-Connections
DeepSeek 🐋 > mHC: Manifold-Constrained Hyper-Connections
This is a new banger paper from DeepSeek!
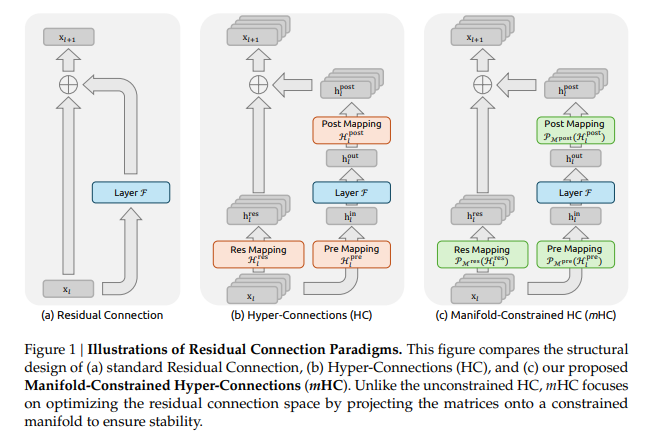
Traditional residual connections (e.g., in ResNets and Transformers) add the layer output to the input, preserving an "identity mapping" that enables stable training in very deep networks. Hyper-Connections (HC), a more recent idea, expand this by widening the residual stream (multiple parallel streams instead of one) and using learned mixing matrices for richer information flow and better expressivity. However, unconstrained HC breaks the identity property, leading to severe training instability (exploding/vanishing gradients) and high memory overhead, limiting scalability.Core Innovation: mHCmHC fixes HC by projecting the mixing matrices onto a specific mathematical manifold — the Birkhoff polytope (doubly stochastic matrices, where rows/columns sum to 1). This is achieved efficiently using the Sinkhorn-Knopp algorithm (an iterative normalization from 1967, ~20 iterations suffice).Key benefits:
- Restores bounded signal propagation (gain stays ~1-1.6 across layers, vs. exploding to 3000+ in plain HC).
- Enables stable widening of the residual stream (e.g., 4-8x wider) for better performance.
- Promotes controlled information mixing across depths, improving representation learning.
Efficiency OptimizationsDeepSeek added heavy infrastructure tweaks (kernel fusion, recomputation, communication overlapping) to keep overhead low (~6-7% extra training time).ResultsExperiments on models up to 27B parameters show:
- Better downstream performance (e.g., on reasoning benchmarks like GSM8K) than standard residuals or unstable HC.
- Superior scalability, with hints from "in-house large-scale experiments" suggesting it's production-ready (likely for DeepSeek's next models, e.g., V4).
In essence, mHC makes a theoretically superior but previously impractical idea (wider, diversified residuals) viable at scale, potentially unlocking new ways to improve LLMs beyond just more parameters or data. It's seen as a fundamental advance in topological architecture design, with community excitement around implementations and combinations (e.g., with value residuals). The original X thread you linked is a fan announcement hyping it as a "huge model smell" breakthrough.
Sources:
 Federico Ulfo
Federico Ulfo
 Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.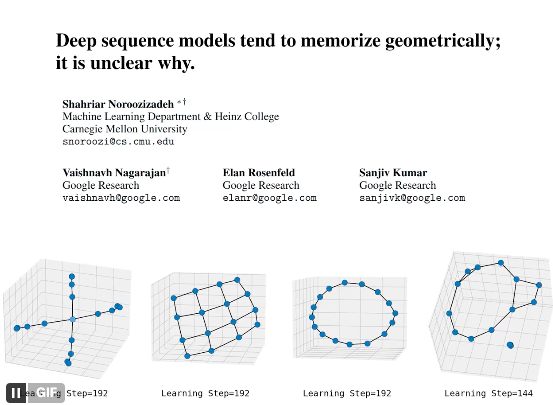 We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."