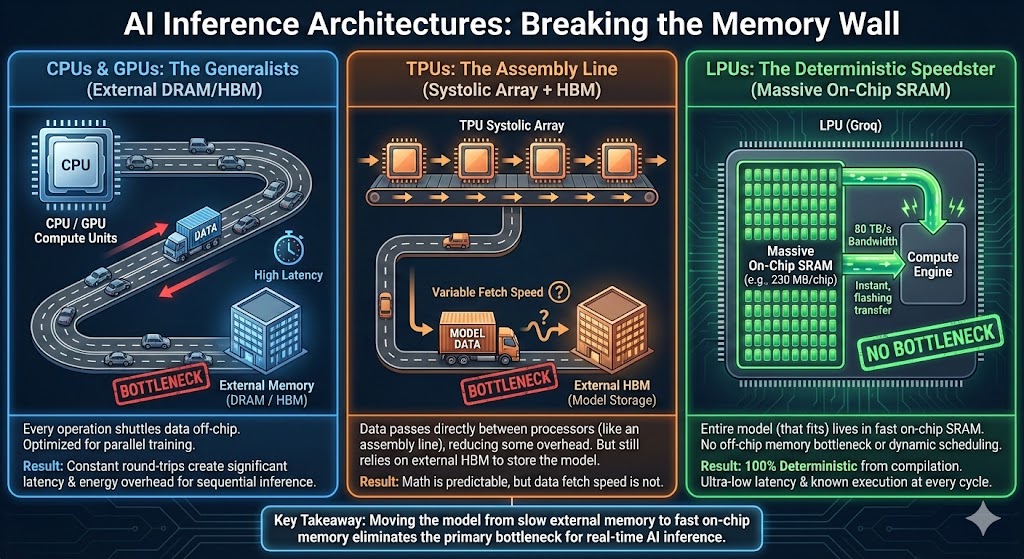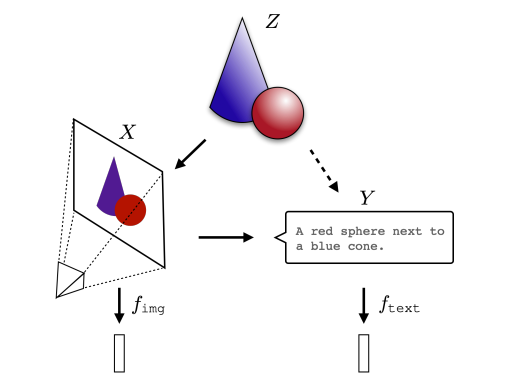
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces. Vision models, language models, different architectures are all slowly approximating the same underlying model of reality.
If this holds up, it's a huge unlock. We could translate between models instead of treating each one like a sealed black box, reuse interpretability wins across systems, and maybe align models at the representation level, not just by policing outputs.
📄 arxiv paper
 Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Their analysis of 1,100+ models (Mistral, ViT, LLaMA) shows they all use a few key "spectral directions" to store information.
This universal structure outperforms assumptions of randomness, offering a blueprint for more efficient multi-task learning, model merging, and drastically cutting AI's computational and environmental costs.
📄 arxiv paper
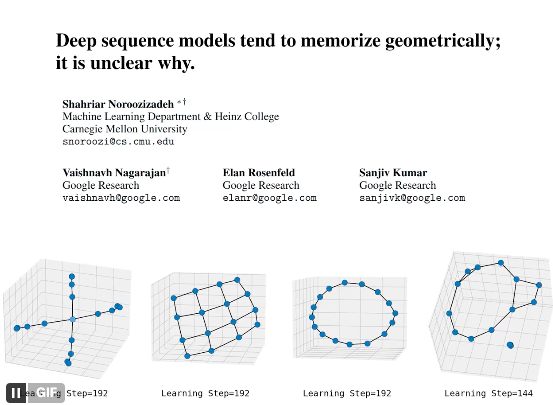 We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
📄 arxiv paper
The crazier implication is philosophical. Maybe MEANING isn't just a human convention. Maybe there are natural coordinates in reality and sufficiently strong learners keep rediscovering them.
So what's actually driving the convergence? The data, the objective, some deep simplicity bias? And where does it break?
Sources




 Federico Ulfo
Federico Ulfo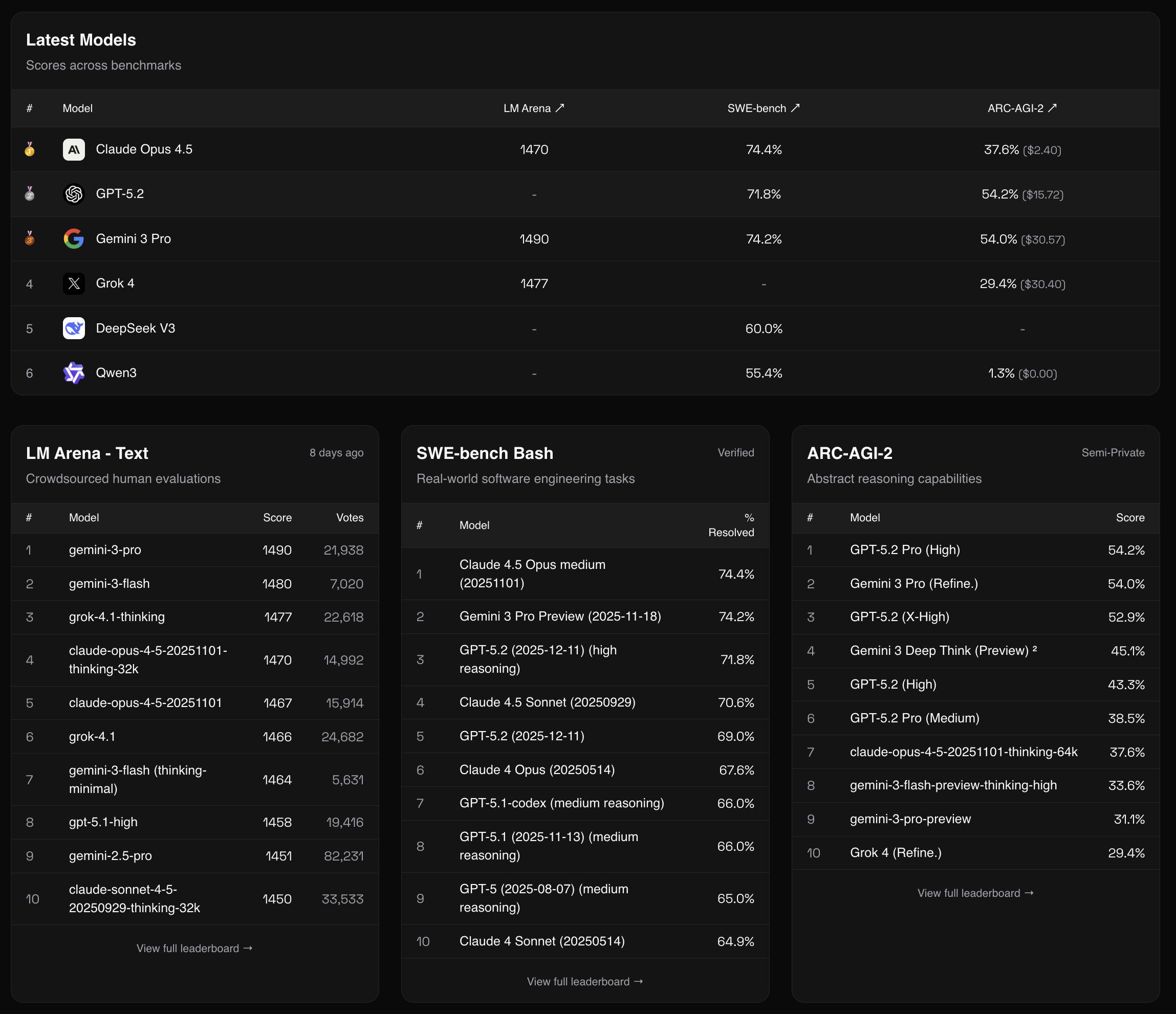

 ### Engineers prefer Claude over Cursor because of its simplicity. So Is Claude code going to replace Cursor?
### Engineers prefer Claude over Cursor because of its simplicity. So Is Claude code going to replace Cursor?

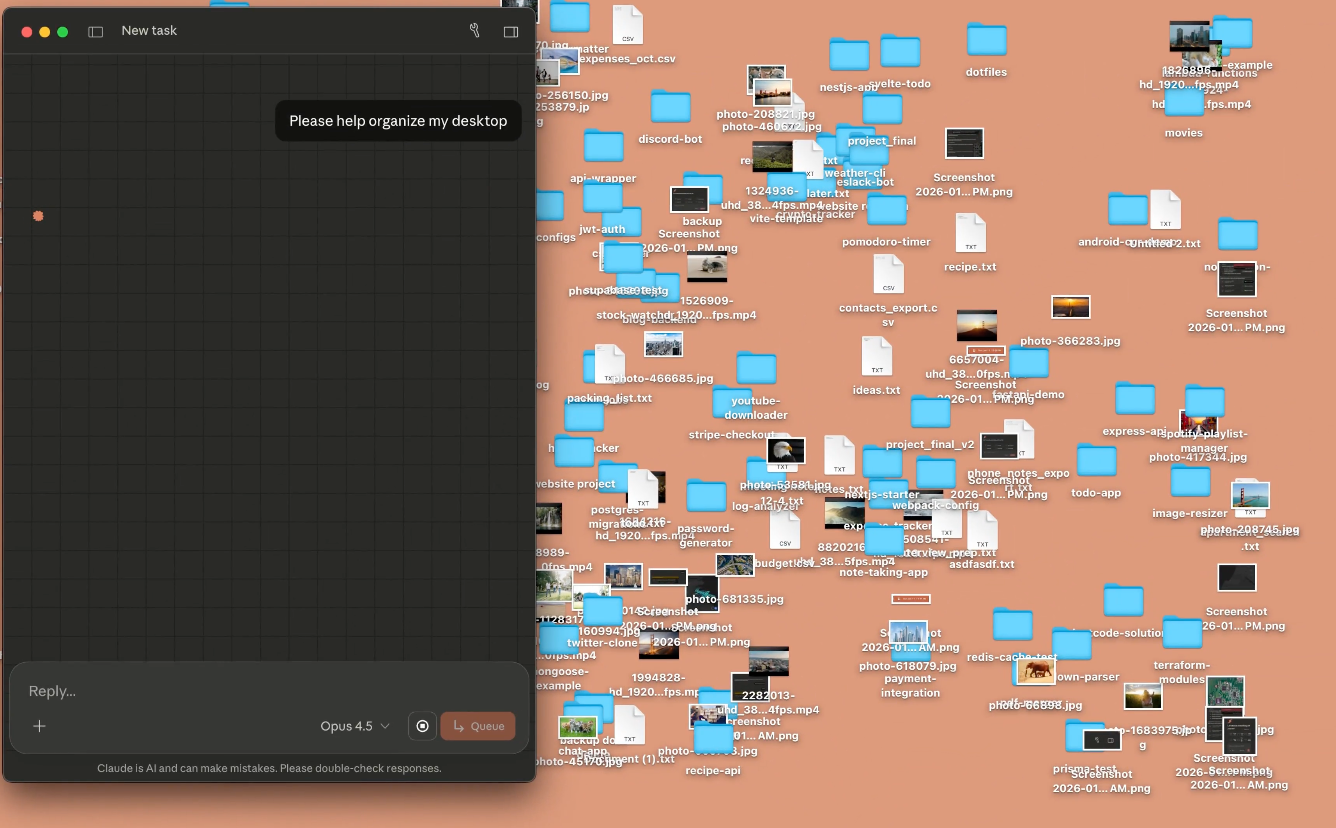

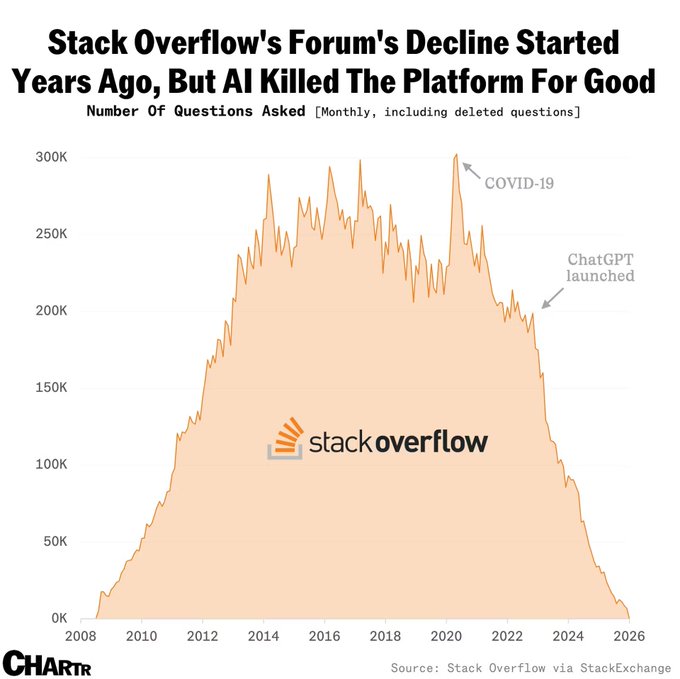


 sources:
sources: