Model Wars: GPT-5.2 vs Opus 4.5 vs Gemini 3 vs Grok 4.1
The "Model Wars" have intensified with major releases from all top providers, focusing heavily on reasoning and efficiency.
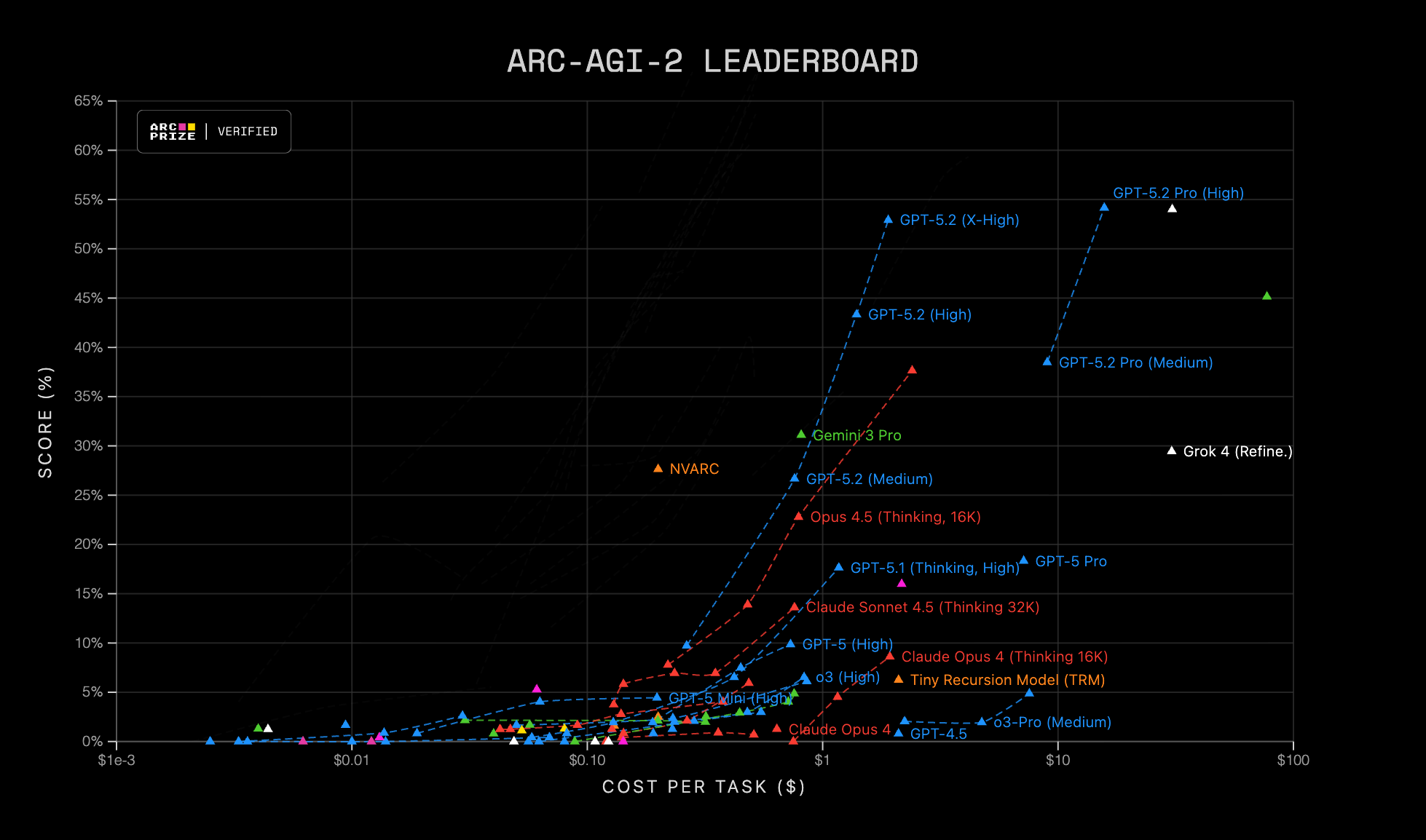
GPT-5.2: OpenAI’s latest step is less “bigger model” and more “better worker”. Instant / Thinking / Pro variants tuned for deep, multi-step knowledge work (coding, long-context synthesis, and tool-heavy agent workflows like spreadsheets and presentations). On ARC-AGI-2 (Verified), GPT-5.2 Thinking posts 52.9% and Pro reaches 54.2%, positioning as OpenAI’s flagship for coding + agentic tasks. Even at higher per-token pricing, it’s pitched as cheaper-per-quality due to improved token efficiency (note: GPT 5.1 already signaled massive efficiency gains, since it was reaching o3 performance at 150x lower cost).
Grok 4.1:
Gemini 3.0: Google released Gemini 3 (Pro and Flash), is a massive leap over ChatGPT 5.1 in reasoning, speed, and video. It reportedly "one-shotted" an entire website build, leading some to declare front-end development "dead".
Claude Opus 4.5: Anthropic's new flagship model is a significant breakthrough. It outperforms predecessors while being cheaper than Sonnet 4.5. Notably, it embeds reasoning directly into files when traces are disabled and is marketed as the best model for coding and agentic computer use. All engineers agree on this being the best coding model.
 Federico Ulfo
Federico Ulfo