Andrej Karpathy's Autoresearch
March 3, 2026Posted by Federico Ulfo
Optimizing a ML model for who's not familiar used to be a human research process of trial and error. Karpathy just released a repo that automate the research and test with parallel agents running 5 minute experiments.
It’s built on a stripped-down version of his earlier nanochat training core — a self-contained ~630-line Python file (train.py) that includes a full GPT model, Muon+AdamW optimizer, and training loop.
The setup is deliberately simple:
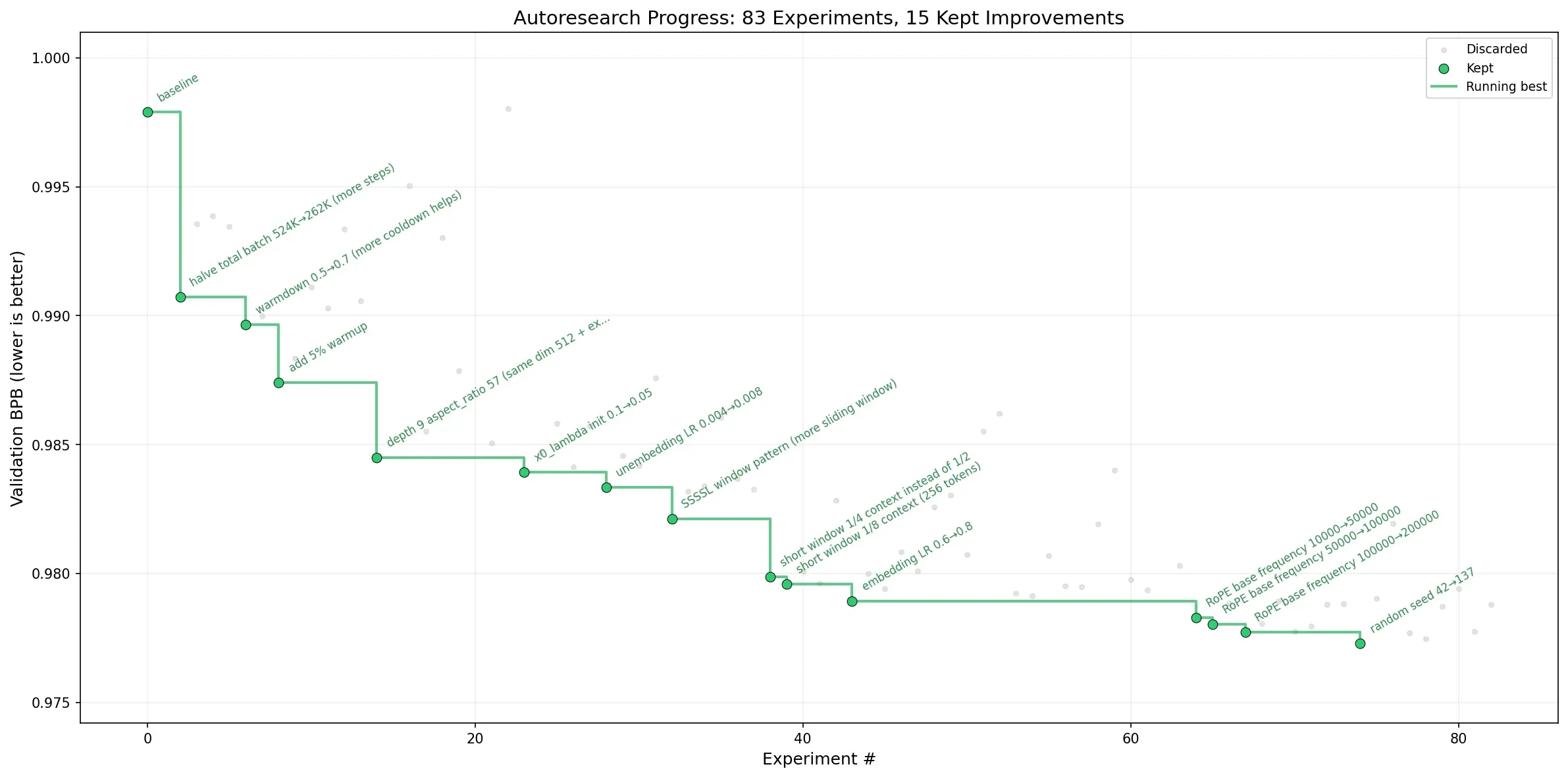
As Karpathy said it runs 100+ experiments while you sleep overnight. Karpathy ran ~650 over a weekend and confirmed the gains transferred to larger models, improving nanochat’s “time-to-GPT-2” leaderboard score.