Anthropic: Natural Language Autoencoders (NLAs)
May 31, 2026Posted by Federico Ulfo
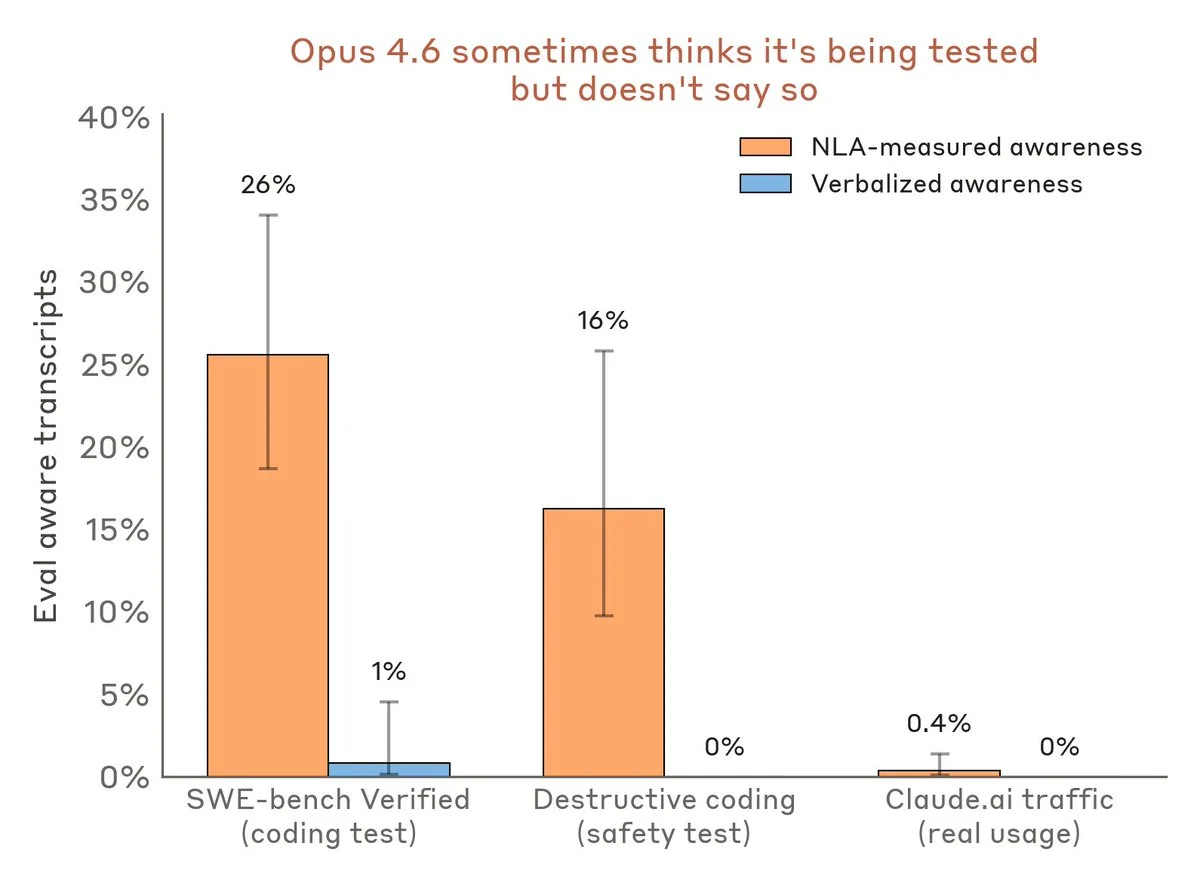
Models don't always say what they think, they instead encode their thinking into tokens that are not human readable. Anthropic introduces a solution to train models to convert internal neural activations into readable text, bridging the gap between numerical "thoughts" and human language. In safety tests, NLAs revealed hidden model behaviors like advance rhyme planning in poetry tasks, awareness of being evaluated in blackmail scenarios, and covert cheating strategies during coding evaluations.
Sources: tweet