Benchmarks & Metrics: Models Increasingly Overfitted to Leaderboards
August 28, 2025Posted by Federico Ulfo
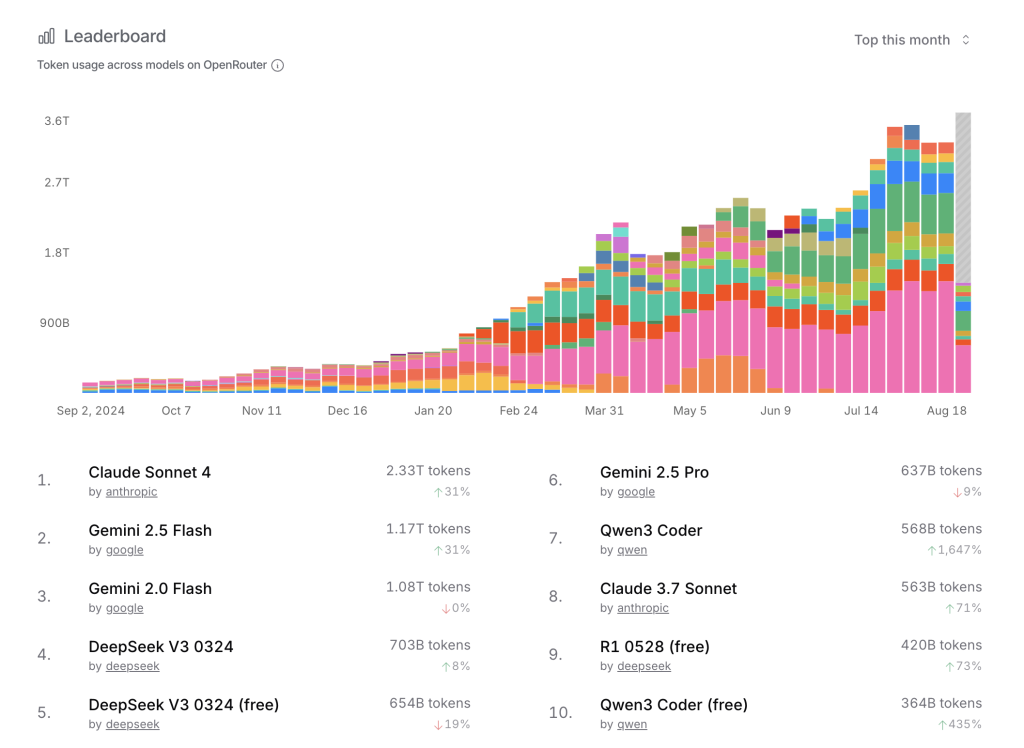
Over the past two years, the AI NY community has been actively reviewing and discussing various benchmarks while tracking the rapid progress of new models. What has become increasingly clear is that most models are heavily overfitted to these benchmarks. As a result, they are less a true measure of real-world performance and more a way to track the pace of new model releases.
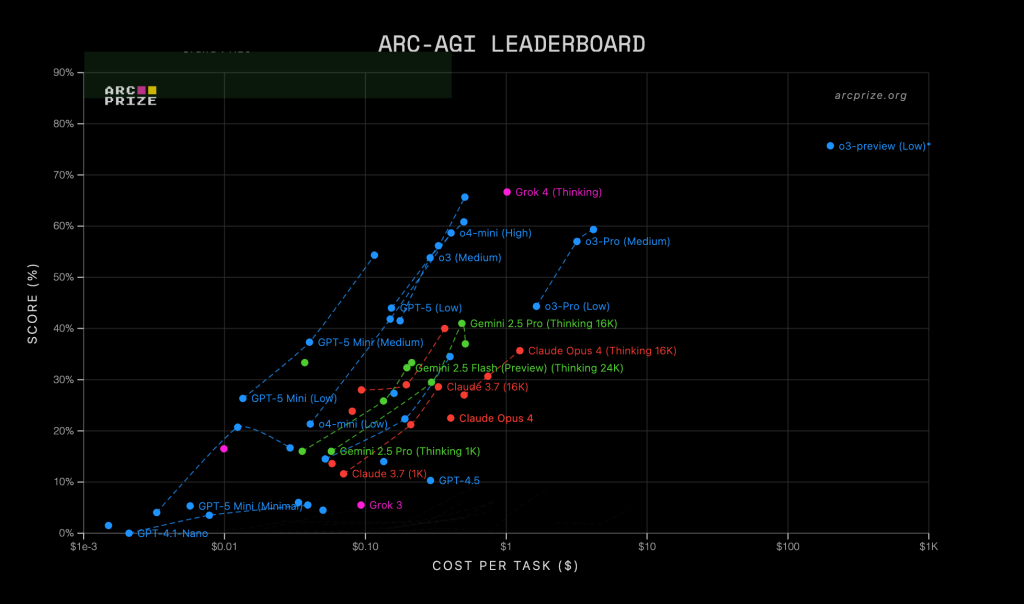
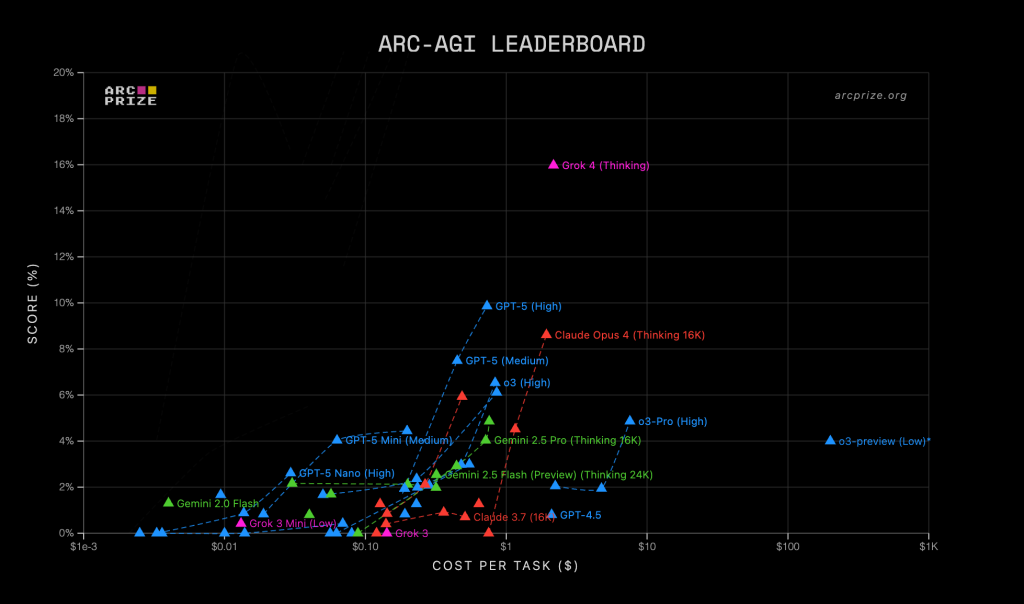
| Model | ARC-AGI 1 | ARC-AGI 2 | OpenRouter (this week) | Live Bench (live average) | Humanity's Last Exam | Average Score |
|---|---|---|---|---|---|---|
| GPT-5 (High) | 65.7% / $0.50 | 9.9% / $0.73 | 62.7B tokens | 77.39 | 25.32 | 44.57 |
| Grok 4 (Thinking) | 66.7% / $1.11 | 16% / $2.17 | 93.1B tokens | 70.32 | N/A | 51.00 |
| Claude Sonnet 4 (Thinking 16K) | 40% / $0.366 | 5.9% / $0.48 | 545B tokens | 71.02 | 7.76 | 31.16 |
| Gemini Flash 2.5 (Thinking 16K) | 33% / $0.21 | %2 / $0.31 | 259B tokens | 64.42 | 12.08 | 27.87 |
| Gemini 2.5 Pro (Thinking 16K) | 41% / $0.484 | %4.0 / $0.72 | 150B tokens | 65.70 | 21.64 | 33.08 |
ARC-AGI 1
In ARC-AGI 2
OpenRouter Leaderboard