DeepSeek V4
May 31, 2026Posted by Federico Ulfo
DeepSeek just dropped V4 (preview) — two open-weights MoE models that push the frontier on cost-effective 1M-token context.
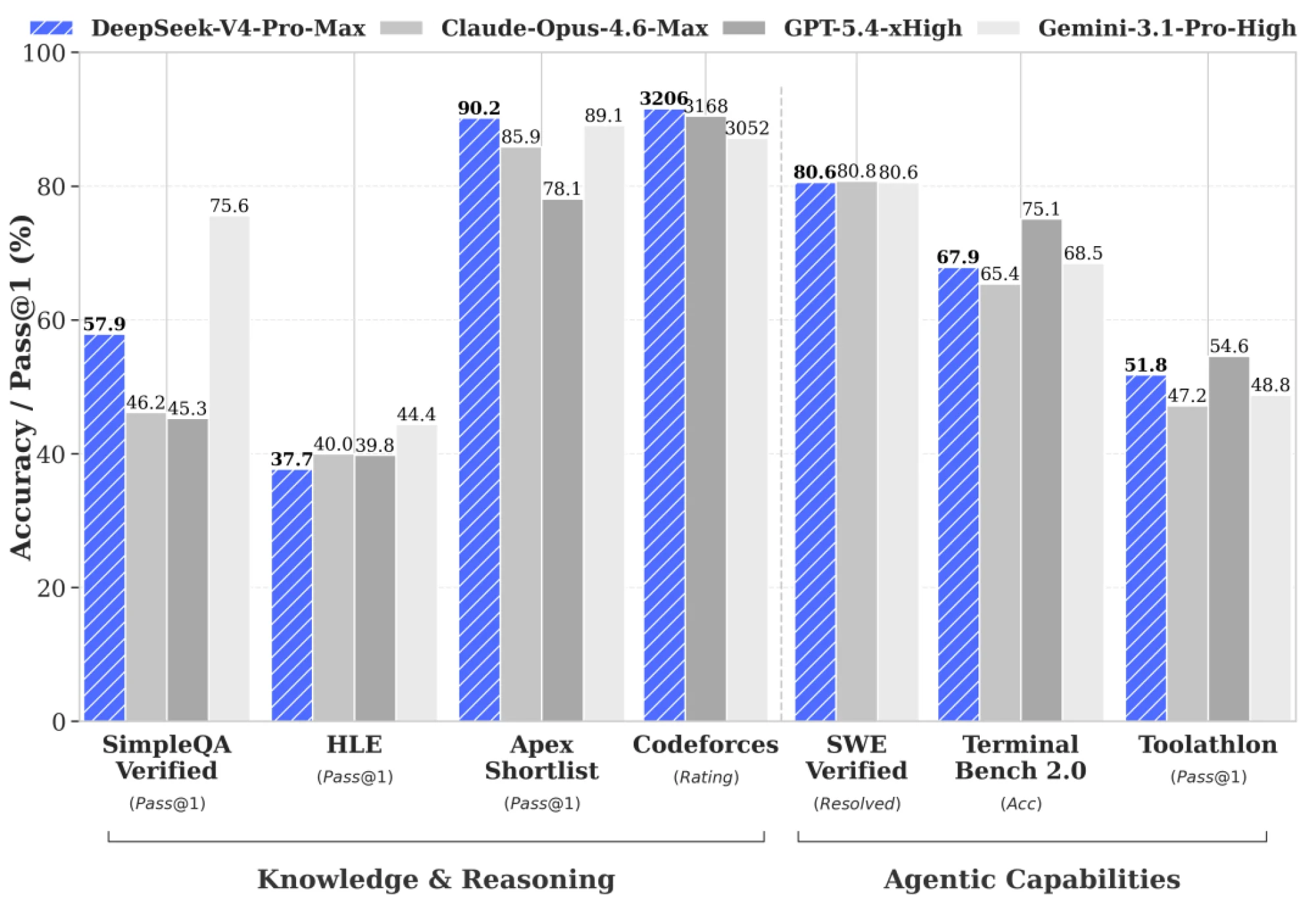
DeepSeek-V4-Pro: 1.6T total params (49B active) — flagship performance rivaling top closed models in reasoning, math, and agentic coding. DeepSeek-V4-Flash: 284B total (13B active) — faster, cheaper, and highly efficient for everyday/agent tasks.
Both feature a new hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) that makes million-token contexts dramatically more practical (much lower FLOPs and KV cache than V3). MIT license, available on Hugging Face (base + instruct), and live on the DeepSeek API today.
The community is already praising the efficiency gains, strong coding/agent results (e.g., high LiveCodeBench / SWE-Bench scores), and rock-bottom pricing — especially with the ongoing Pro discount.
Sources: Official announcement, Hugging Face collection, Tech Report, tweet discount extended