This is one of the best blog posts of 2025 by the OpenAI researcher Shunyu Yao. A playbook for what will matter most in AI research and the startup ecosystem, and how to prepare.
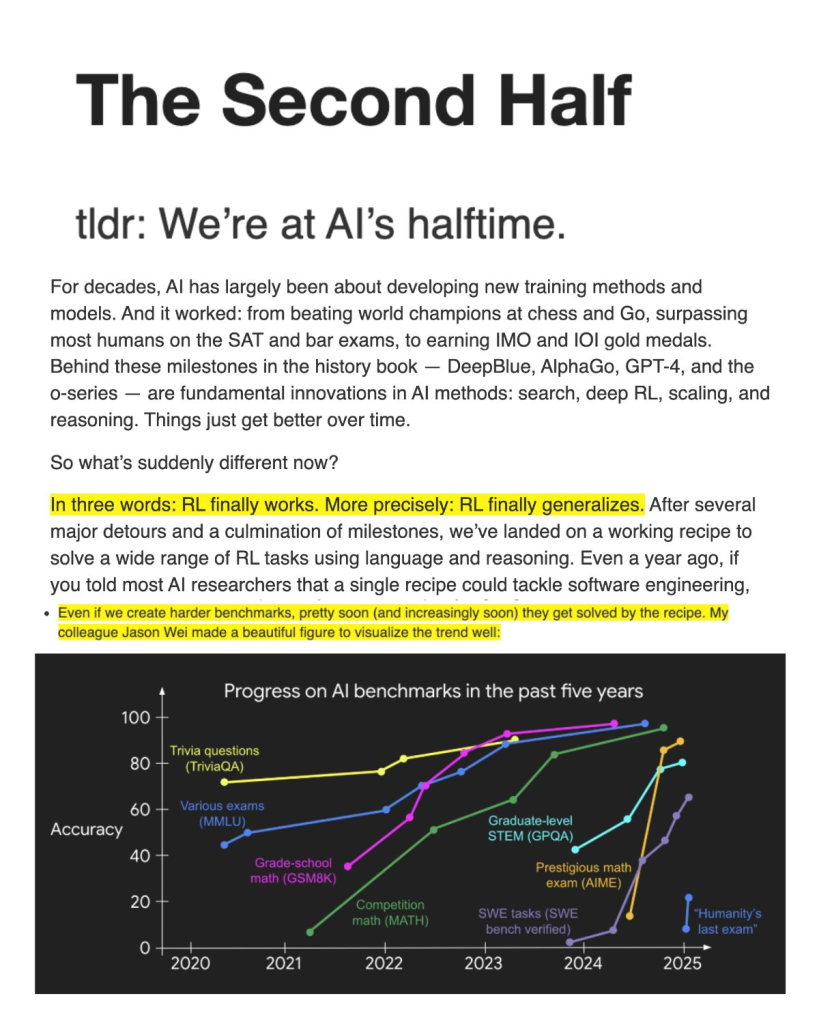
In the first half the focus was on developing new training methods and models. In the second half the focus shift from solving problems to defining problems, and write the correct eval for it.
Reinforcement learning (RL) key components
In RL there 3 main components:
-
Algorithm, the learning rule or optimization method that updates the agent's policy. This is the machinery of RL: from early methods like REINFORCE and Q-learning, to more advanced ones like actor-critic, PPO, or TRPO. Algorithms define how the agent learns from experience.
-
Environment, the world in which the agent operates. It provides the state, feedback, and reward signals. In research, environments range from toy grids and Atari games to robotics simulators and large-scale language interaction settings. The environment defines what the agent is learning about.
-
And priors, the knowledge the agent brings before any RL begins. Priors can come from pre-training on vast datasets.
For decades, RL researchers obsessed over algorithms—REINFORCE, DQN, TD-learning, actor-critic, PPO, TRPO. Sutton and Barto's classical textbook is almost entirely about algorithms, with little attention to environments or priors.
That mindset carried into mainstream AI. The first half of the modern AI era was dominated by new training methods and model architectures: AlexNet, the transformer, GPT-3. Then the progress stack on algorithms and models beating benchmarks. But the game changed when RL finally generalized.
The working recipe now looks like this: massive language pre-training (priors) + scale + reasoning-as-action inside a RL loop.
It turned out the most important part of RL might not be the algorithm or the environment, but the priors, which can be obtained in a way totally unrelated from RL.
So now the frontier shifts from solving problems to defining the right problems, evaluation takes center stage, and the core benchmark is no longer a leaderboard score but the "utility problem." In fact traditional benchmarks don't translate well to real-world tasks.
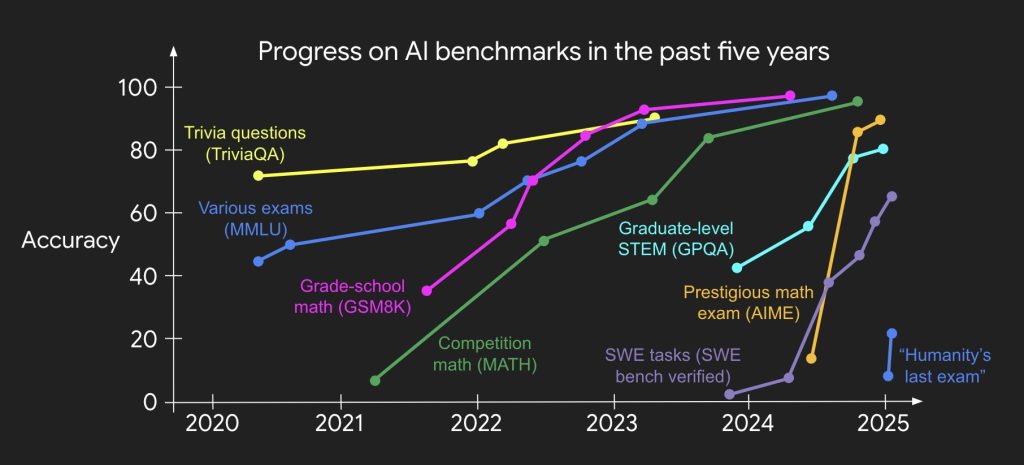
This is a great blog post that requires a few reading before really syncing in.
https://x.com/ShunyuYao12/status/1911671943457345675
https://x.com/Hesamation/status/1960717949771092429
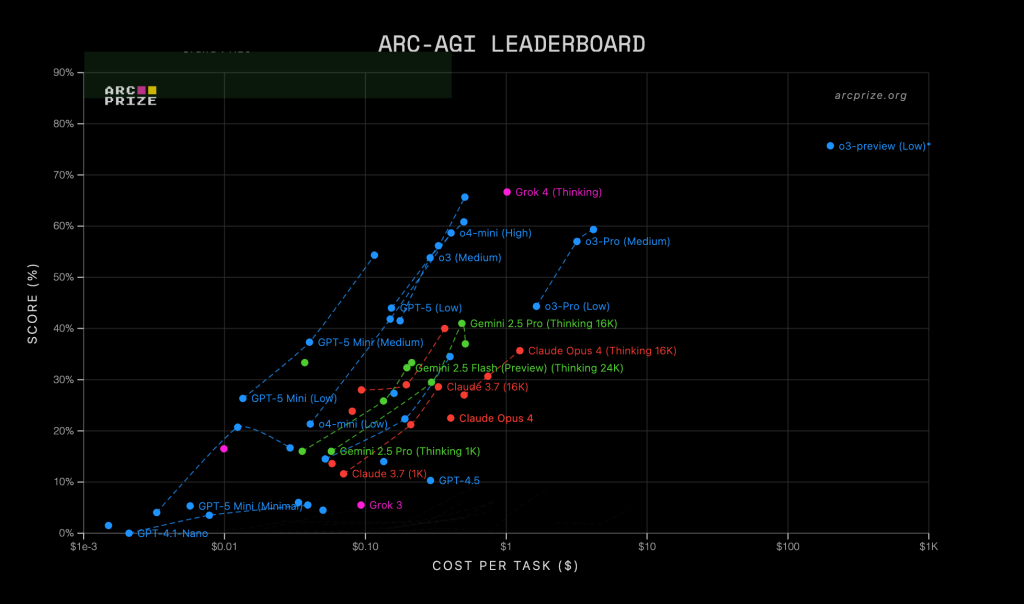
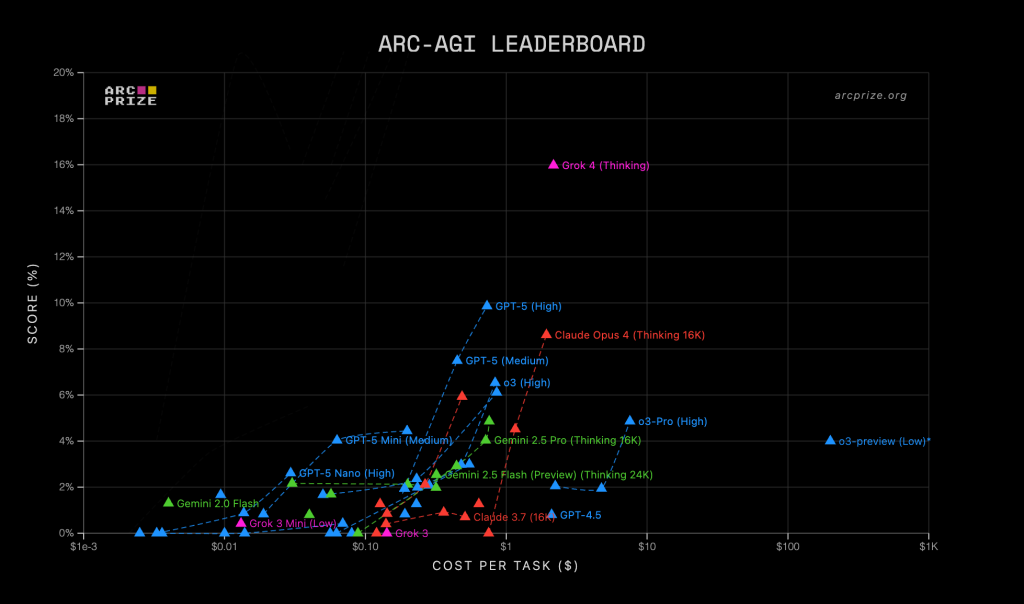
 Federico Ulfo
Federico Ulfo