Anthropic shares how they built Claude's new multi-agent Research feature, an architecture where a lead Claude agent spawns and coordinates subagents to explore complex queries in parallel. They use this orchestrator-worker architecture:
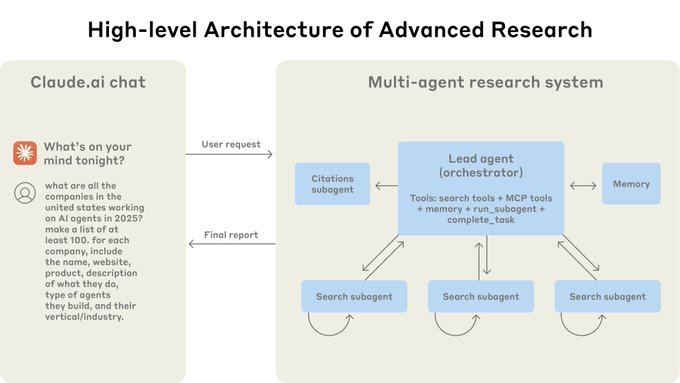
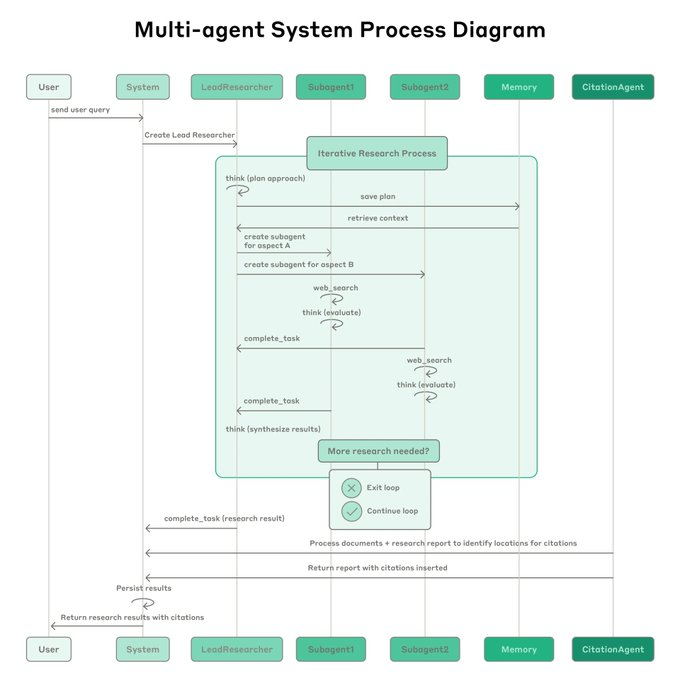
Traditional approaches using Retrieval Augmented Generation (RAG) use static retrieval. That is, they fetch some set of chunks that are most similar to an input query and use these chunks to generate a response. Anthropic Advanced Research architecture uses a multi-step search that dynamically finds relevant information in parallel, adapts to new findings, and analyzes results to formulate high-quality answers.
Token-efficient Scaling Performance gains correlate strongly with token usage and parallel tool calls. By distributing work across multiple agents and context windows, Claude’s system scales reasoning capacity efficiently. However, this comes with a 15× token cost over standard chats, making it suitable for high-value queries only.
- Think like your agents.
- Teach the orchestrator how to delegate.
- Scale effort to query complexity.
- Tools design and selection are critical. MCP servers gives tools access on steroids.
- Let agents improve themselves. The agents can diagnose when something fails, and fix it by rewriting the MCP description. This process saved 40% times.
- Start wide, narrow down.
- Guide the thinking process.
- Parallel tool calling transforms speed and performance. Parallelism can cut up to 90% of the total time.
Flexible Evaluation + Production Reliability Anthropic uses LLM-as-judge scoring with rubrics for factuality, citation, and efficiency, alongside human testing to catch subtle failures. For reliability, they built resumable stateful agents with checkpointing, rainbow deployments, and full observability of agent decision traces, crucial for debugging non-deterministic, long-running agents.
Blog: https://anthropic.com/engineering/built-multi-agent-research-system
Tweet: https://x.com/omarsar0/status/1933941545675206936.

https://x.com/swyx/status/1933981734456230190
AI coding tooling & coding agents being packaged into products, and even worse, cloud products, is the wrong path. Command Line is the way!
Tutorial on how to use it: https://x.com/rasmickyy/status/1931078993022730248

 Federico Ulfo
Federico Ulfo