
Early June Anthropic’s released Fable, Mythos class model, only to be censored by Washington 72 hours later. The rest of the month was a continuation of the debate of Open Source vs Closed Source models and regulations.
GLM 5.2 is the new hot model! It's the first open weight models to truly rival closed models like Opus 4.8, with some impressive stats. At roughly 1/6th the cost of GPT-5.5 or similar frontier models, GLM-5.2 delivers near-state-of-the-art coding and agent performance in an open-weight package. It’s a big win for developers who want high capability without vendor lock-in or sky-high API bills.
Coinbase just migrated their coding agents from Opus 4.8 to GLM 5.2 and drastically cut their cost, while continue to increase their token usage.
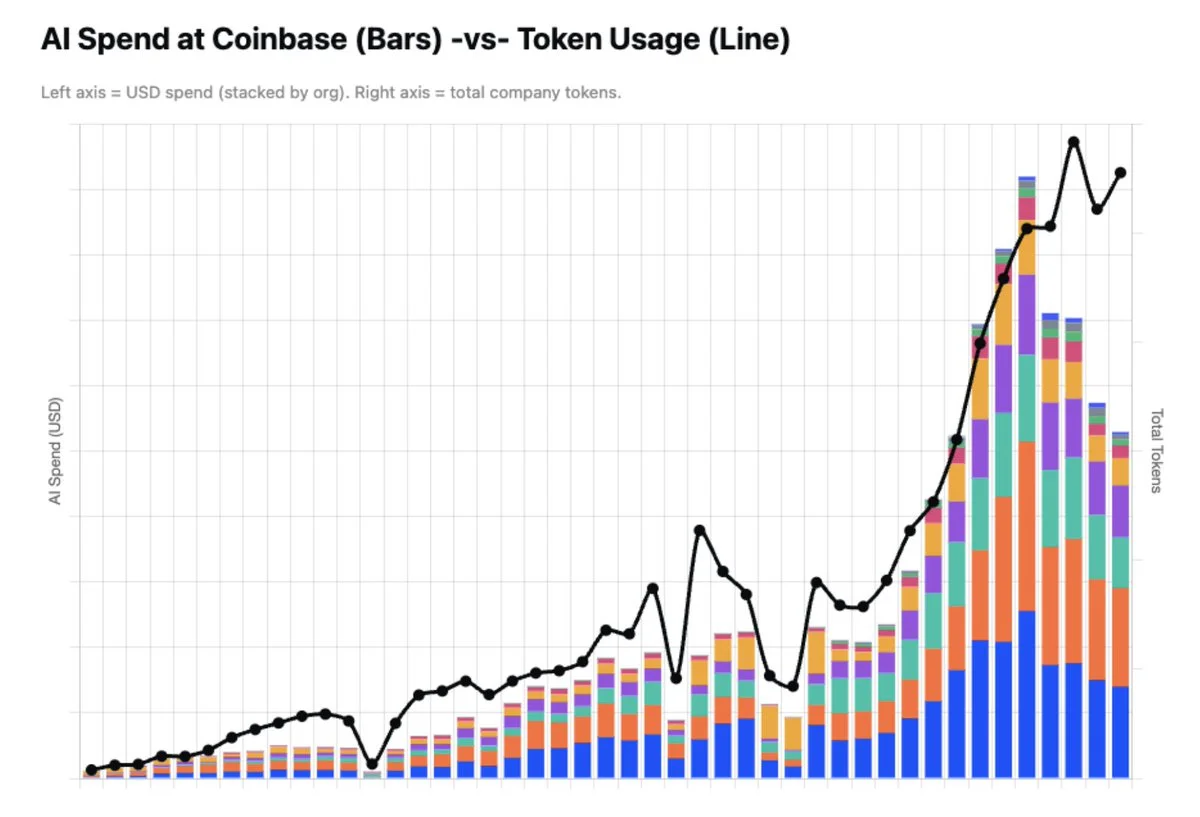
Sources: Brian Armstrong tweet.
Note: token usage over cost doesn't tell you the full picture, output productivity x token is also very important — to give you a practical example, Fable cost per 1m token is the highest, yet in my experience it also has the highest productivity per token.
With the ongoing regulations war on Fable and GPT 5.6, and with the high costs, more and more companies are moving to open source Chinese models.

GLM 5.2 combines architectural tricks like IndexShare (for massive context efficiency) and improved multi-token prediction to keep performance high without exploding costs. Early users report it’s excellent at maintaining context across long projects, following engineering standards, and executing full development workflows.
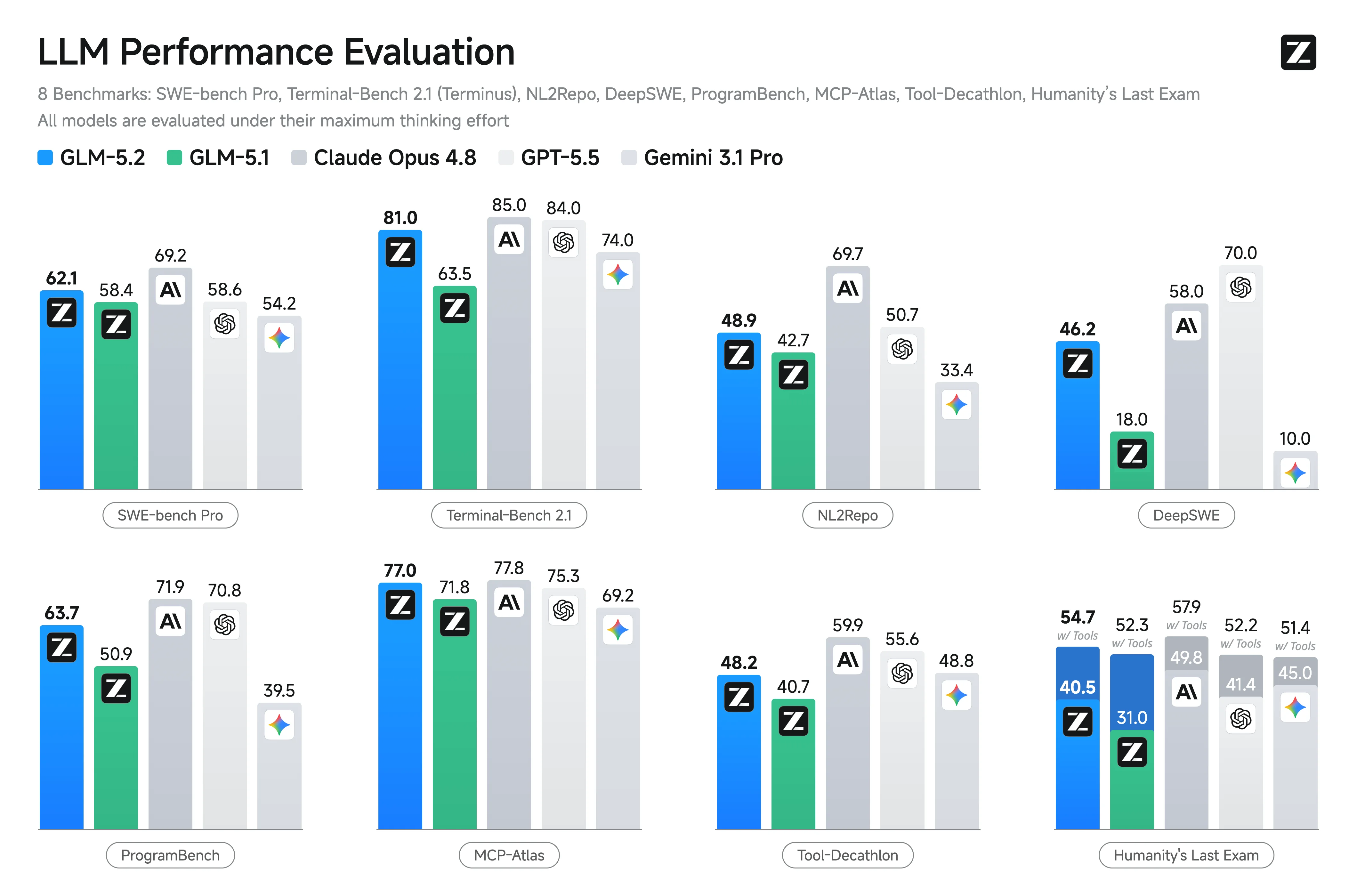
GLM-5.2 was purpose-built for agentic, long-horizon tasks — especially software engineering. It shines on benchmarks like:
"YoU CaN rUn It At HoMe" — well, not really!

Well, you can't really run it at home that easily, here are the requirements

Few days ago someone asked Elon when Chinese models could have rivaled US closed models:
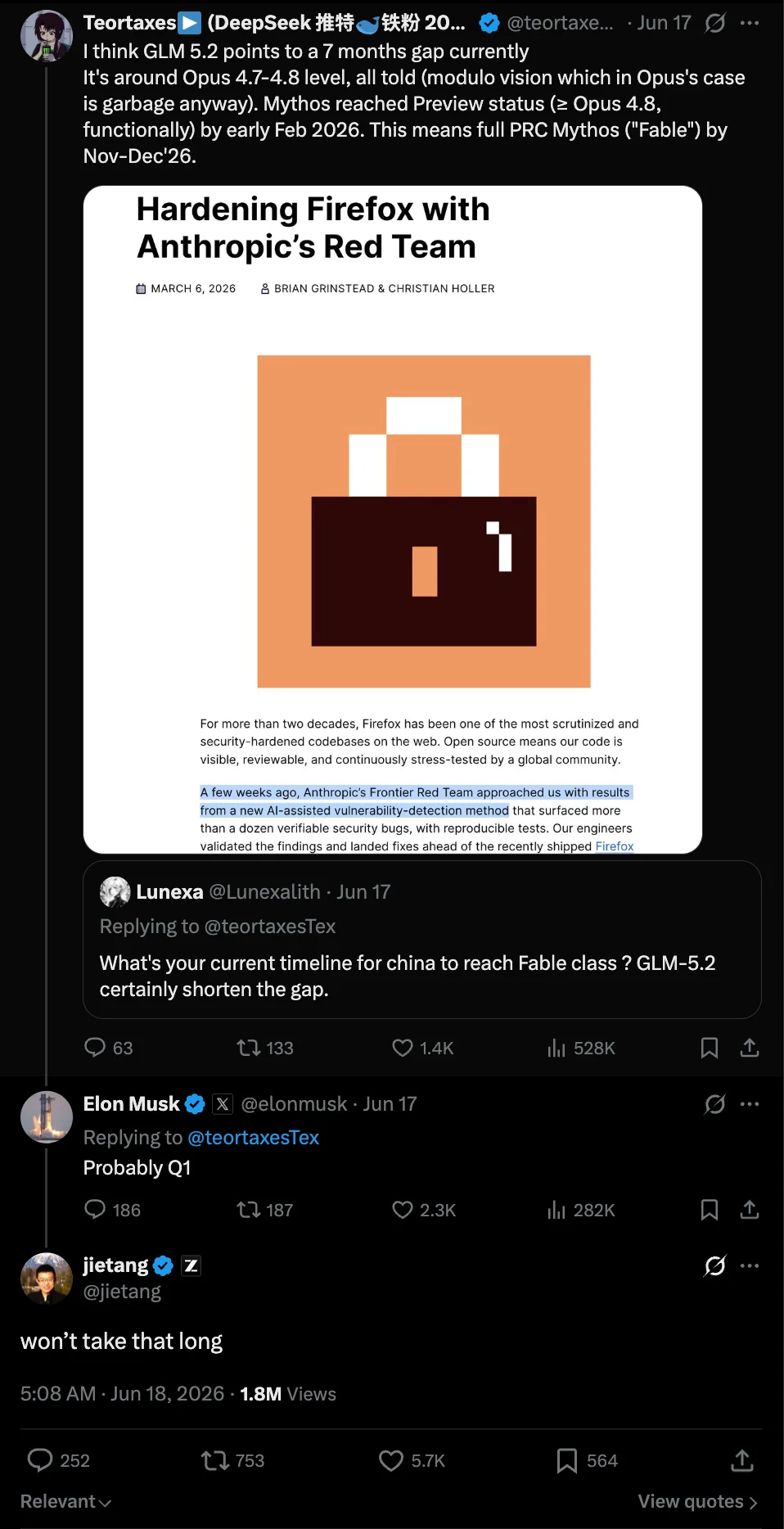
Sources: Z.AI announcement Unsloth GGUF guide, tweet, Coinbase Tweet

Sakana AI, the Tokyo lab run by David Ha and Llion Jones, just dropped Fugu — an LLM that doesn’t just answer questions but actually orchestrates other models. It figures out whether to respond directly or hand off work, splits tasks across Thinker/Worker/Verifier roles, checks the output, and can even call itself recursively if needed.
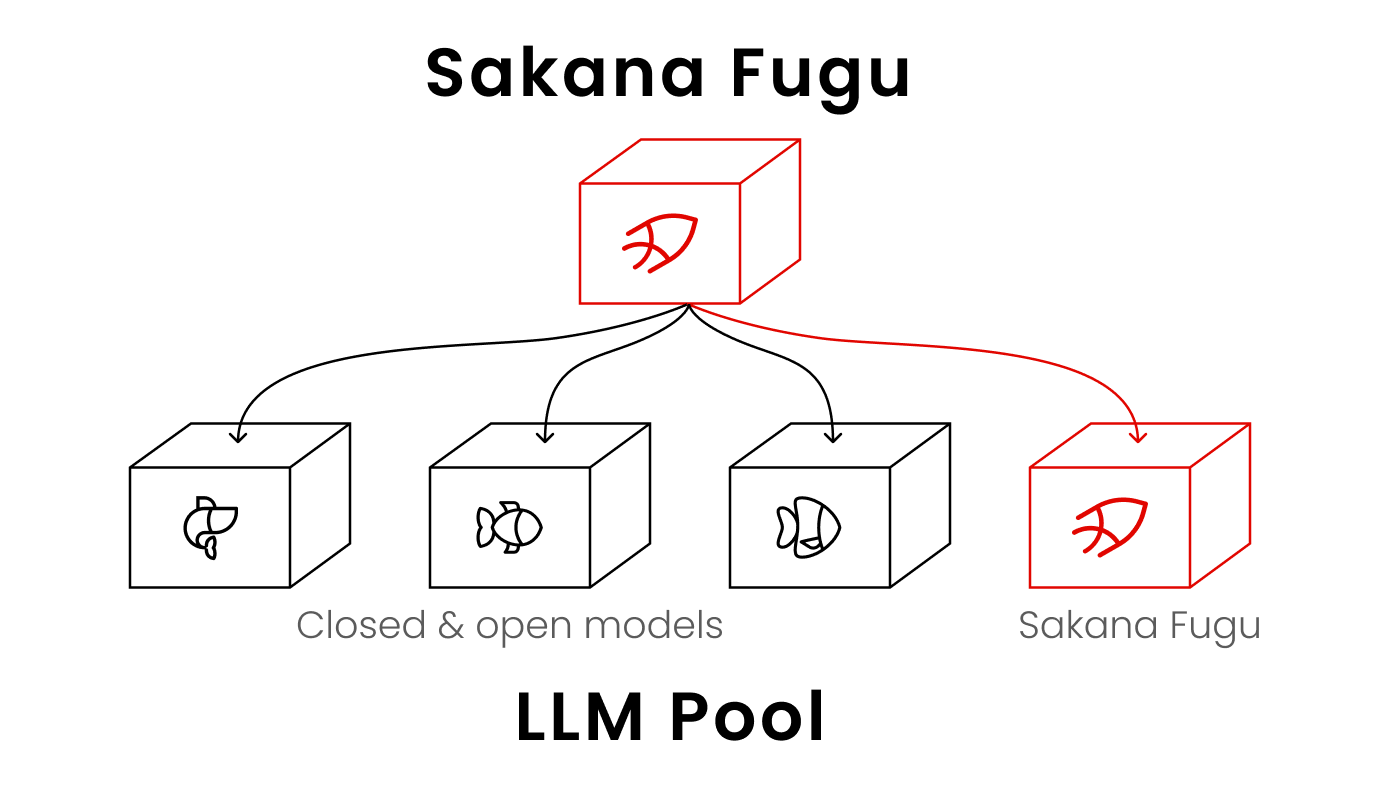
The big idea is resilience instead of lock-in. Because the underlying pool of models is swappable, Fugu can route around any provider that suddenly disappears — they specifically called out the export controls that took down Anthropic’s Fable and Mythos models. Their line: “Relying on a single company’s APIs for critical infrastructure is a material vulnerability.”
They released two versions (Fugu and Fugu Ultra) behind a single OpenAI-compatible API. Ultra is already trading blows with Fable 5 on early benchmarks (SWE-Bench Pro around 73.7% — take the exact digits with a grain of salt). It’s proprietary and API-only for now.
Sources: sakana.ai
Hugging Face’s Thomas Wolf spent a week running an open experiment with 100+ agents collaborating freely. The result? They squeezed a 5× inference speedup out of Gemma 4 inside vLLM. He called it one of the most interesting emergent behaviors he’s seen from agent swarms so far.
Sources: Thomas Wolf / Hugging Face
On June 18, Midjourney announced its biggest shift yet: Midjourney Medical and a full-body “Ultrasonic CT” scanner. The device creates a sub-millimeter 3D model of your entire body in about 60 seconds — roughly 100× faster than an MRI — using sound waves instead of radiation. You lie in a ring of nearly 500,000 sand-grain-sized ultrasonic emitters while slowly moving through water (inspired by dolphin echolocation). It’s powered by a $74 million exclusive deal with Butterfly Network. Founder David Holz called it the first entirely new whole-body medical imaging technology in five decades.
The fine print: This is still a first-gen prototype with no regulatory clearance. The company is framing it as a wellness tool rather than a diagnostic device. Their vision includes a 25,000 sq ft “Midjourney Spa” featuring cold plunges and cozy rooms with pools of golden light that gently scan your body. Theranos comparisons started immediately.
Sources: Engadget, Radiology Business, The Register.
After years of everyone mocking smart glasses, Snap finally made them look cool... just kidding! The specs are AR glasses with 2 Snapdragon chips, their own LCoS displays, a solid 51° field of view (about the size of a 115-inch screen floating ten feet away), and they weigh just 132g with around four hours of battery.
They're quite expensive, about $2,195 and start shipping this fall. The same crowd that called Google Glass wearers “Glassholes” back in the day is now happily pre-ordering four-figure face computers. Character development, indeed.
 Sources: Snap Newsroom, CNBC, TechCrunch.
Sources: Snap Newsroom, CNBC, TechCrunch.
A new player called Aleph came out of stealth claiming the highest-resolution 3D images of a living human brain ever taken from outside the skull. It’s a non-invasive approach to brain interfaces, deliberately contrasting with Neuralink’s surgical implants. Their pitch, of course, is “brain interfaces for the telepathic future.”
Sources: tweet
IBM announced what they’re calling the first sub-1nm process: a 0.7nm (7-angstrom) node using a 3D “nanostack” architecture that vertically stacks transistors. They say it can fit nearly 100 billion transistors on a chip with 70% better energy efficiency. As usual with chip marketing, the “0.7nm” label is more branding than literal measurement — the density and efficiency gains are what matter.
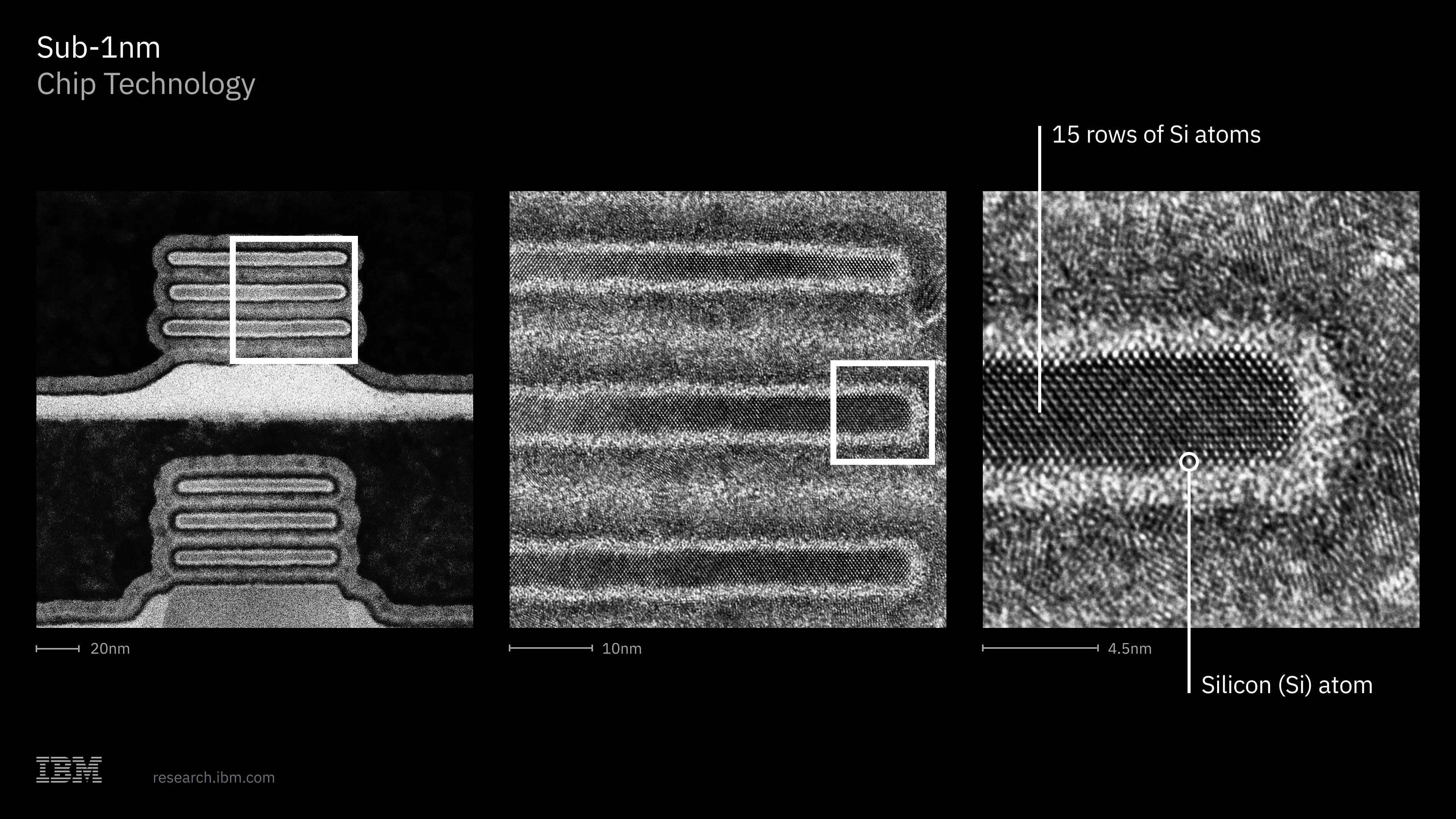 Sources: twitter
Sources: twitter

A nice reminder that the biggest sensor network on the planet is already in everyone’s pocket. Google’s Android Earthquake Alerts System turns every phone’s accelerometer into a miniature seismometer. It combines readings from thousands of devices to detect the first waves of a quake and send alerts seconds before the shaking hits. No new hardware required — just crowdsourced, planet-scale sensing.
Sources: x
Dwarkesh Patel published this crisp 12-minute video on the current state of LLM scaling: The Data Black Hole at the Center of AI. I rewatched it 3 times already.
His core idea is sample efficiency: how much data a system needs before it can operate competently in a domain.
His argument is that we haven’t dramatically improved training sample efficiency in recent years. Instead, what improved is the breadth and quality of the data distribution. He frames RL as a synthetic data generation process and explains how much bespoke, expert-generated data sits behind frontier models, one reason the data-labeling industry has become a multi-billion-dollar market.
A human absorbs roughly 200 million words from birth to adulthood, while frontier models train on tens to hundreds of trillions of tokens — a difference approaching a millionfold.
A teenager can learn to drive in around 20 hours. Patel walks through the common objections: evolution as a form of “pretraining,” multimodal learning, scaling laws, and why he finds these explanations insufficient.
A few thoughts: The strongest argument is around scaling laws. Even with unlimited parameters, improvements may only reduce data requirements by roughly an order of magnitude, while humans appear thousands to millions of times more sample efficient.
If true, humans may be operating on a fundamentally different curve than current AI systems — a much bigger challenge to the “just scale it” thesis than the industry often acknowledges.
Another interesting observation: open models are often surprisingly close to closed models because capabilities can be distilled through APIs. Data and behavior transfer more easily than proprietary architectural breakthroughs.
The biggest open question is whether sample-inefficient AI systems can eventually solve the sample-efficiency problem themselves.
Can today’s AI systems accelerate AI research enough to improve the next generation of models?
My view: current models are not autonomously self-improving, but humans using AI systems as research assistants are already accelerating experimentation, coding, analysis, and iteration. The interesting question is how far this feedback loop can go.
Again, this is one of the crispiest pieces I’ve seen on the future of AI scaling. Worth 12 minutes of your time.
RLVR, Grindability, and the Need for On-the-Job Learning
Dwarkesh just released a new essay diving into the big research bet that all the major AI labs are making right now.
The labs believe that training AIs on millions of verifiable tasks across thousands of diverse RL environments will get us to AGI. This approach should forge a true problem-solving agent—one that can grind on open-ended tasks for weeks, handling errors, ambiguity, and roadblocks along the way.
Optimists argue that current paradigm shortcomings—like massive data inefficiency or the lack of true continual learning—will simply get steamrolled by more scale, just like many "fundamental" problems in NLP collapsed under the weight of LLM training compute.
But there are real challenges here. Progress on "computer use" has been surprisingly slow despite high verifiability, partly because many real-world domains aren't easily "grindable" — you can't spin up thousands of parallel, replayable, deterministic simulators for things like building a business, winning court cases, day trading profitably, or running a political campaign. Real-world rollouts are reset-free, non-stationary, and data is sparse and idiosyncratic. Sample efficiency matters a lot when you can't brute-force with simulations.
Even if in-context learning improves dramatically (with massive context windows), we still need to get the learning back into the weights. Inference compute (30-50% of a lab's resources) is currently wasted instead of feeding back into model improvement from real deployments—the richest source of tacit, organization-specific knowledge.
I explore ideas for bridging this gap: on-policy self-distillation (OPSD) for denser, more targeted updates that distill session learnings without needing perfect outer-loop rewards, and more speculative "dreaming" — where models build their own simulations to rehearse and reinforce skills at massive scale.
By 2027-2028, the next paradigm could combine strong RLVR agents (good at getting bearings and iterating in new situations) with effective on-the-job learning mechanisms. That combination feels like the unlock for more general, adaptive intelligence.
Will scaling RLVR + better context be enough, or do we need fundamental breakthroughs in continual/online learning to reach AGI?
Sources: youtube, Dwarkesh's blog post
It was a strong couple of weeks for interpretability work — people digging into what’s happening inside these models.
@Hesamation captured the spirit perfectly: put a lab like DeepSeek under GPU restrictions, and they don't slow down — they invent their way to 51% to 400%+ throughput boosts.
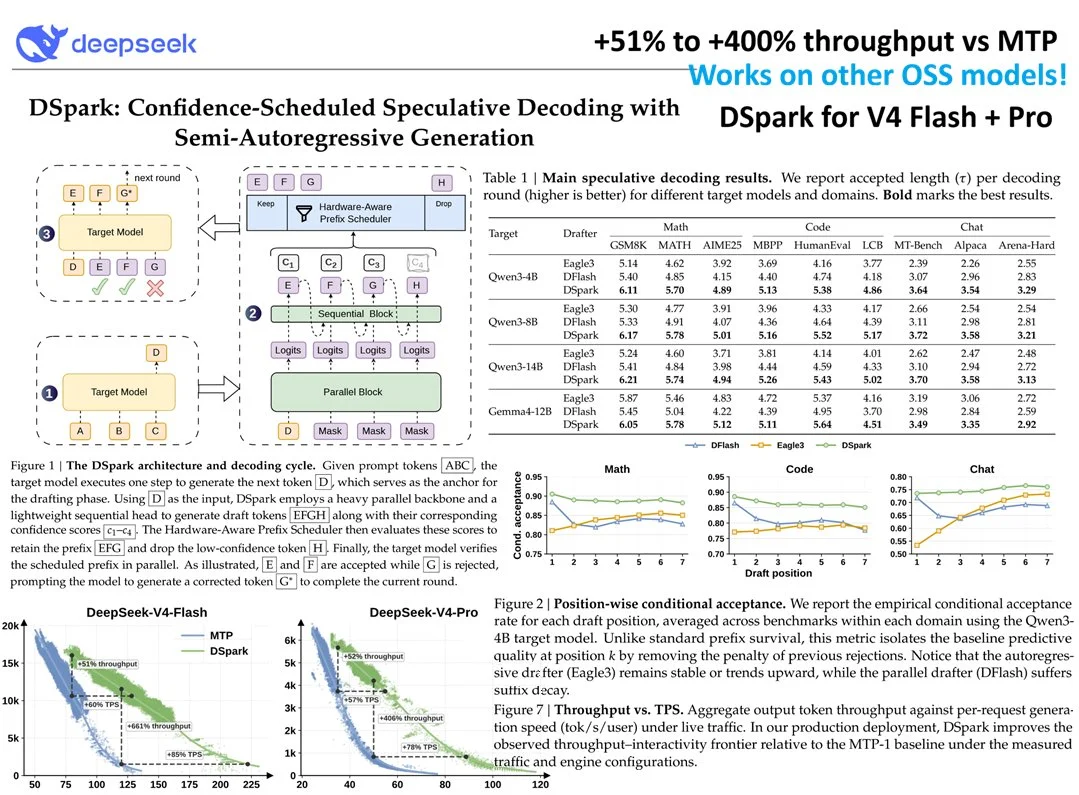
DeepSeek DSpark throughput charts — baseline (blue) vs DSpark (green) across batch sizes and sequence lengths
In the main post, @danielhanchen (of Unsloth) broke it down cleanly: DeepSeek just released DSpark, a new confidence-scheduled speculative decoding method for their V4 Flash and Pro models. It's open-sourced with the full GitHub repo, paper, and Hugging Face checkpoints. Impressively, they also demonstrated strong results when applying it to other open models like Gemma and Qwen.
It combines a lightweight sequential drafter with hardware-aware prefix scheduling and conditional acceptance. Unlike standard speculative decoding, it maintains stability across varying loads and delivers big real-world speedups (see the throughput charts jumping from baseline blue to green DSpark territory). The gains are especially striking at production-relevant batch sizes and sequence lengths. #The deeper context This isn't just another incremental paper. It's another data point in DeepSeek's pattern of simultaneously advancing models and the surrounding inference stack. While much of the industry focuses on pretraining scale, DeepSeek keeps shipping practical inference breakthroughs that immediately lower the cost of intelligence.
Geopolitical tailwind for open source: Hardware export limits are forcing Chinese labs to optimize ruthlessly. The result? Techniques that spread quickly across the open ecosystem, benefiting everyone running local or cost-sensitive deployments. Inference is the new frontier: Training gets the headlines, but compounding wins in speculative decoding, quantization, and scheduling are quietly making powerful models accessible at a fraction of the price. What doesn't kill you…: The 28–34x cost advantage some are quoting for V4-Pro doesn't come from one trick — it comes from a culture of stacking every efficiency layer possible. DSpark is the latest brick in that wall. If you care about running capable models cheaply and at scale, this is the kind of release that moves the needle today. Highly recommended to skim the paper — the diagrams on the decoding cycle and position-wise acceptance rates are particularly clean.
Sources: paper, Unsloth, tweet
In a one-day hackathon using their “AI neuroscientist” tool Silico, Goodfire managed to remove a 67M-parameter model’s ability to predict German — by tuning just a single scalar on one weight subcomponent, after fine-tuning on only 4 German tokens. CEO Eric Ho put it well: “we’re getting closer to being able to hand-edit a weight and know exactly what it will do.”
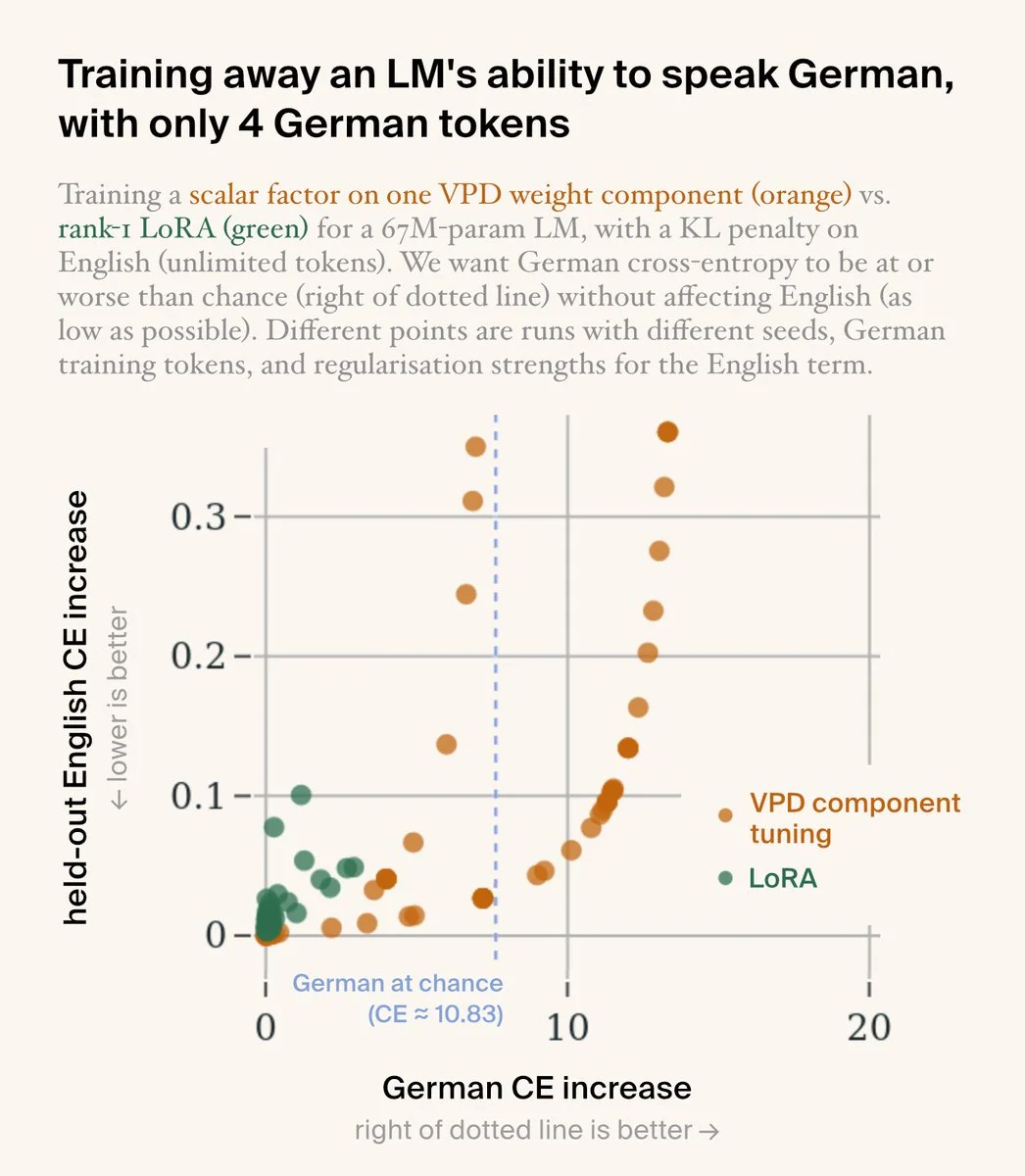 Sources: Eric Ho / Goodfire
Sources: Eric Ho / Goodfire
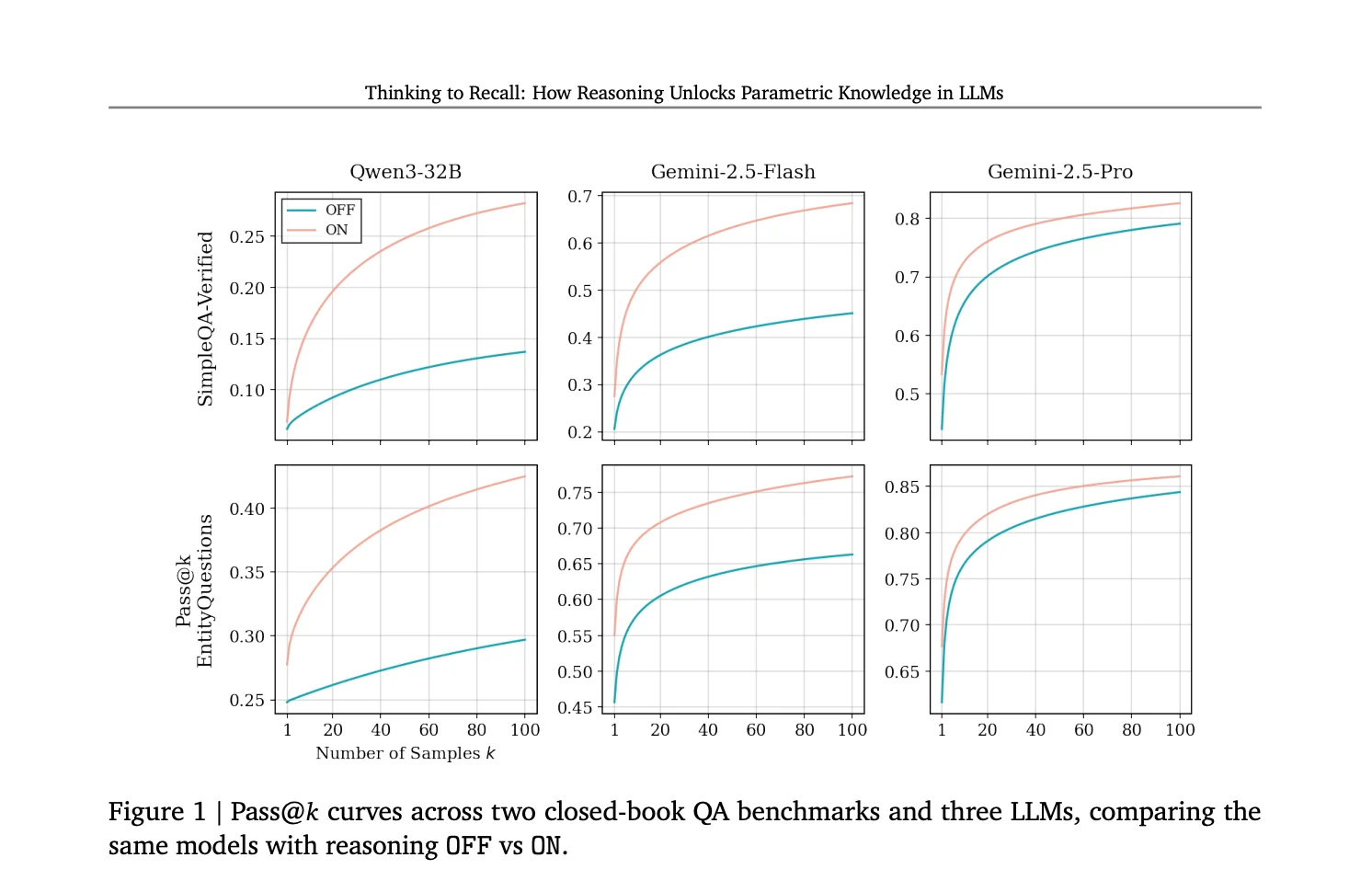 Google Research showed that simply letting a model “think” helps it answer even basic factual questions better. Adding filler tokens like “let me think” gave a nice bump (SimpleQA from 20.6% → 26.2%), and proper reasoning traces create factual priming. The flip side? One hallucinated intermediate fact can tank the whole answer — which actually strengthens the case for grounded reasoning as a way to cut down hallucinations. (arXiv:2603.09906)
Google Research showed that simply letting a model “think” helps it answer even basic factual questions better. Adding filler tokens like “let me think” gave a nice bump (SimpleQA from 20.6% → 26.2%), and proper reasoning traces create factual priming. The flip side? One hallucinated intermediate fact can tank the whole answer — which actually strengthens the case for grounded reasoning as a way to cut down hallucinations. (arXiv:2603.09906)
Sources: arXiv:2603.09906
 New research shows that the Platonic Representation Hypothesis is mostly a statistical illusion. The apparent “global convergence” of representations as models scale is largely a mathematical artifact caused by selection bias in model width and depth. Once properly calibrated, that convergence effect mostly vanishes. The authors argue we should move from a Platonic view (identical global spaces) toward something more Aristotelian (shared local topological neighborhoods).
New research shows that the Platonic Representation Hypothesis is mostly a statistical illusion. The apparent “global convergence” of representations as models scale is largely a mathematical artifact caused by selection bias in model width and depth. Once properly calibrated, that convergence effect mostly vanishes. The authors argue we should move from a Platonic view (identical global spaces) toward something more Aristotelian (shared local topological neighborhoods).
 The internet doing one gentle thing well: a cheap USB mic on a balcony listens to the birds outside, an AI identifies the species, and paints them onto the wall as a live, ever-shifting collage. No product, no pitch — just a calm, human-scale use of AI.
The internet doing one gentle thing well: a cheap USB mic on a balcony listens to the birds outside, an AI identifies the species, and paints them onto the wall as a live, ever-shifting collage. No product, no pitch — just a calm, human-scale use of AI.
 A Microsoft researcher built a working LLM inside Age of Empires 2, wiring logic gates out of in-game goats — to make the point that a fluent reply is just a vast lattice of yes/no switches, not a sign of sentience.
A Microsoft researcher built a working LLM inside Age of Empires 2, wiring logic gates out of in-game goats — to make the point that a fluent reply is just a vast lattice of yes/no switches, not a sign of sentience.
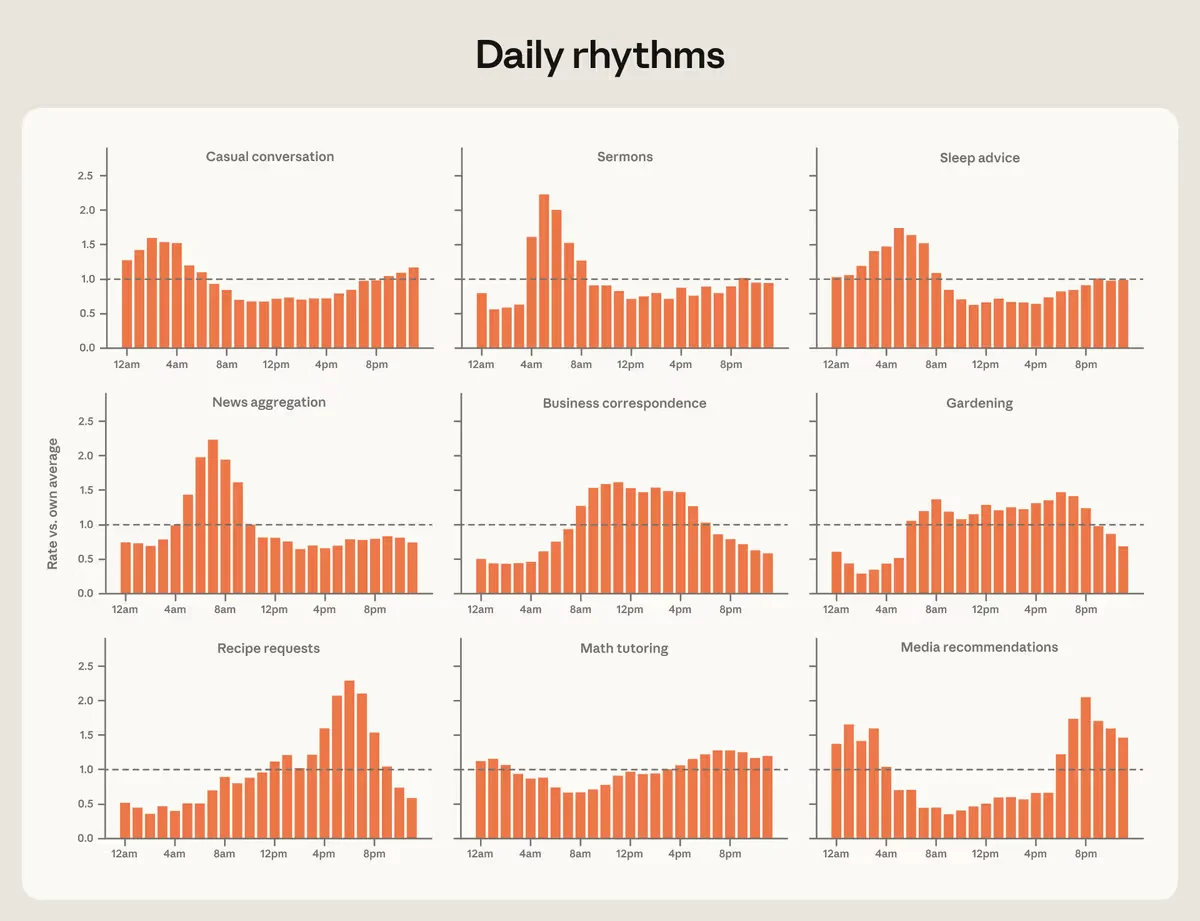 Aggregate usage as a portrait of a day: news at dawn, recipes at dusk, sleep advice at 5am — and gardening, the one perennial, steady from sunrise to sunset.
Aggregate usage as a portrait of a day: news at dawn, recipes at dusk, sleep advice at 5am — and gardening, the one perennial, steady from sunrise to sunset.
 Sources: karpathy tweet
Sources: karpathy tweet
Compiled from the AI Socratic community updates feed, June 16–27, 2026. As always: corrections and additions welcome.
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.

Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.

DeepSeek v4, GPT 5.5, Trump x Xi meeting, Richard Dawkins, Estimating model sizes

Mythos, Claude Code leak, Anthropic surpass OpenAI on MRR
