Prompt Repetition Improves Non-Reasoning LLMs
February 6, 2026Posted by Federico Ulfo
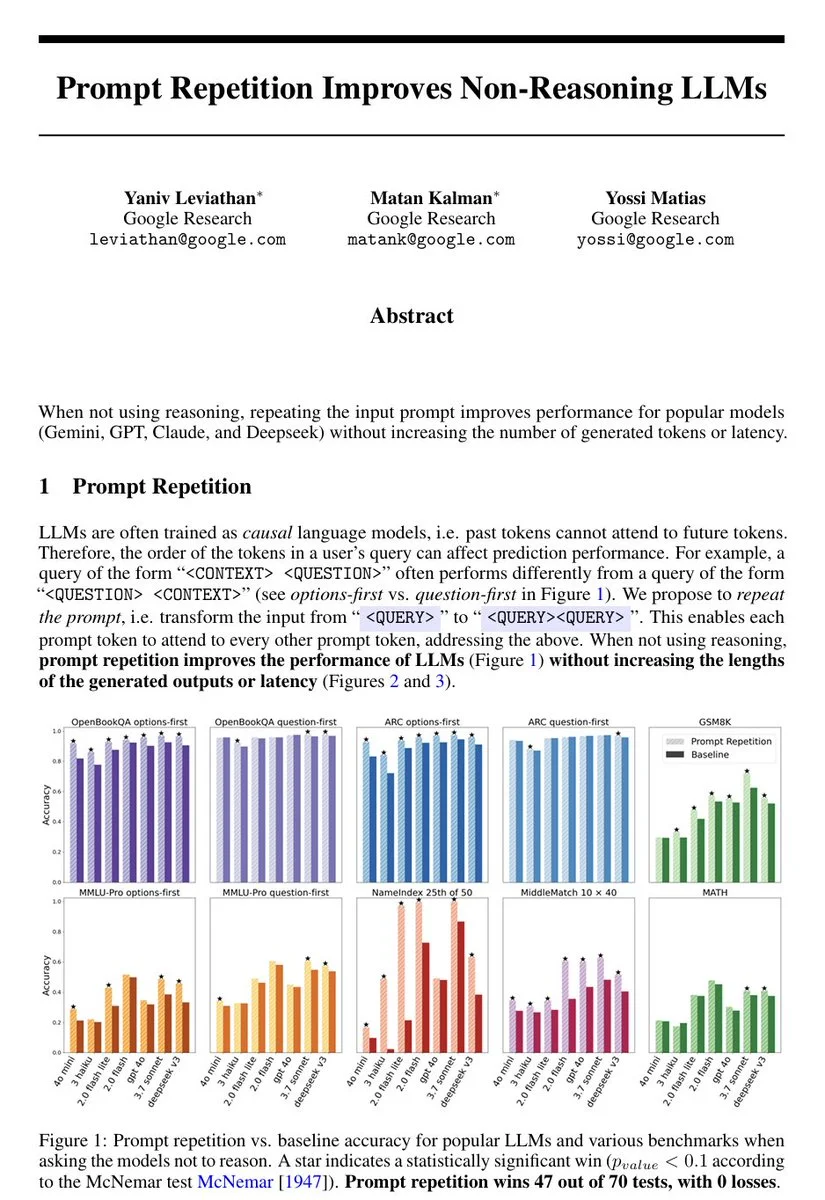
LLMs read prompts left to right, so early context can’t “know” what question is coming. This paper tests a simple fix: repeat the entire prompt twice, giving every token a second chance to attend to everything else.
Across seven benchmarks and seven major models (Gemini, ChatGPT, Claude, DeepSeek), accuracy improves, sometimes dramatically, without longer outputs or meaningful slowdown. Without fine-tuning, extra training, or prompting techniques.
Sources: tweet, (paper)[https://arxiv.org/pdf/2512.14982]