Nvidia GTC 2026 — The Year of Physical AI
This year, the focus was on physical AI, and in my experience something on the line of: 30% Data Centers, 30% GPUs and Hardware, 30% Robotics, 10% Software.
Highlights from the conference
- $1 Trillion AI Infrastructure Boom, Jensen projects $1 trillion in cumulative orders for Blackwell + Vera Rubin systems through 2027 (2x 2026 estimates).
- Vera Rubin Platform Unveiled, next-gen full-stack AI platform features seven new chips, five rack-scale systems, a new Vera CPU for Agentic AI, and BlueField-4 storage. It promises major efficiency gains and starts shipping later in 2026, with even denser designs (like Kyber) coming in 2027.
- NemoClaw, everyone and their grandma are launching a personal AI agent, so now is NVIDIA turn.
- Inference Inflection & Token Economics, a massive leap in token generation performance (up to 350x in some tiers) position inference as the new economic engine of AI, with "tokens" becoming the core commodity.
- Physical AI, Gaming & Ambitious Vision, advances in robotics (e.g., Disney's Olaf), DLSS 5 for gaming, and bold plans for space-based AI data centers (Vera Rubin Space-1). Emphasis on full AI factories, open models (Nemotron ecosystem), and simulating infrastructure with Omniverse.

 Federico Ulfo
Federico Ulfo
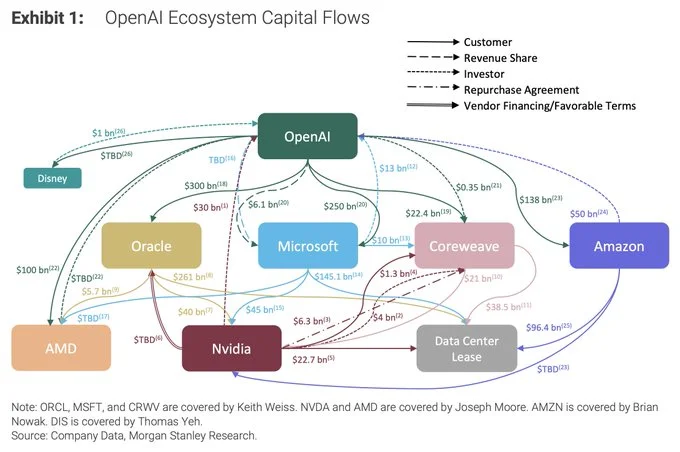











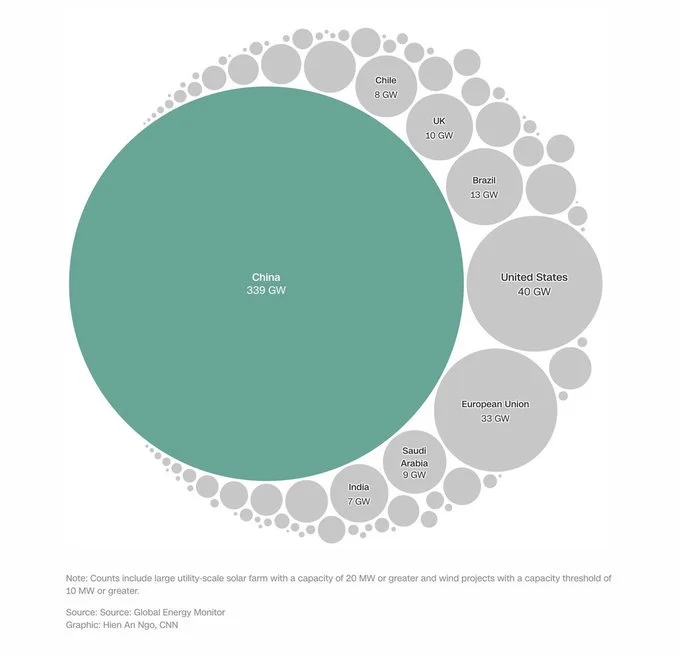

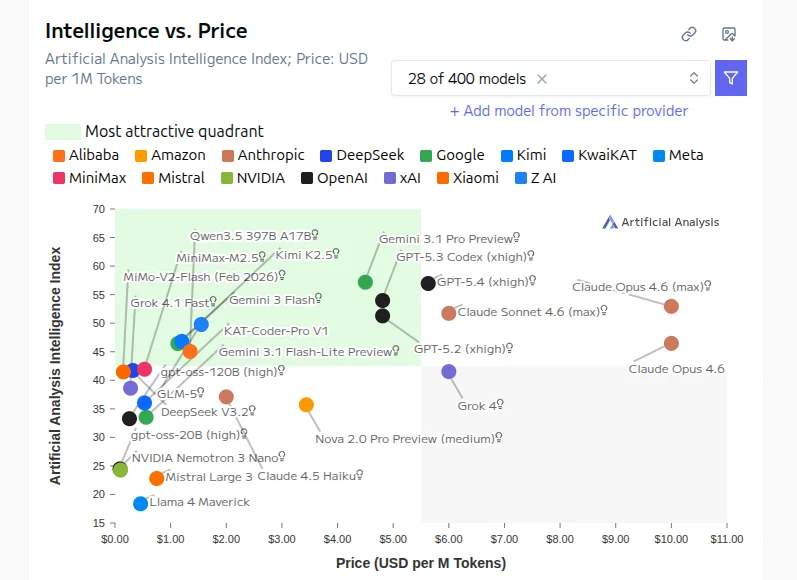 Sources:
Sources: 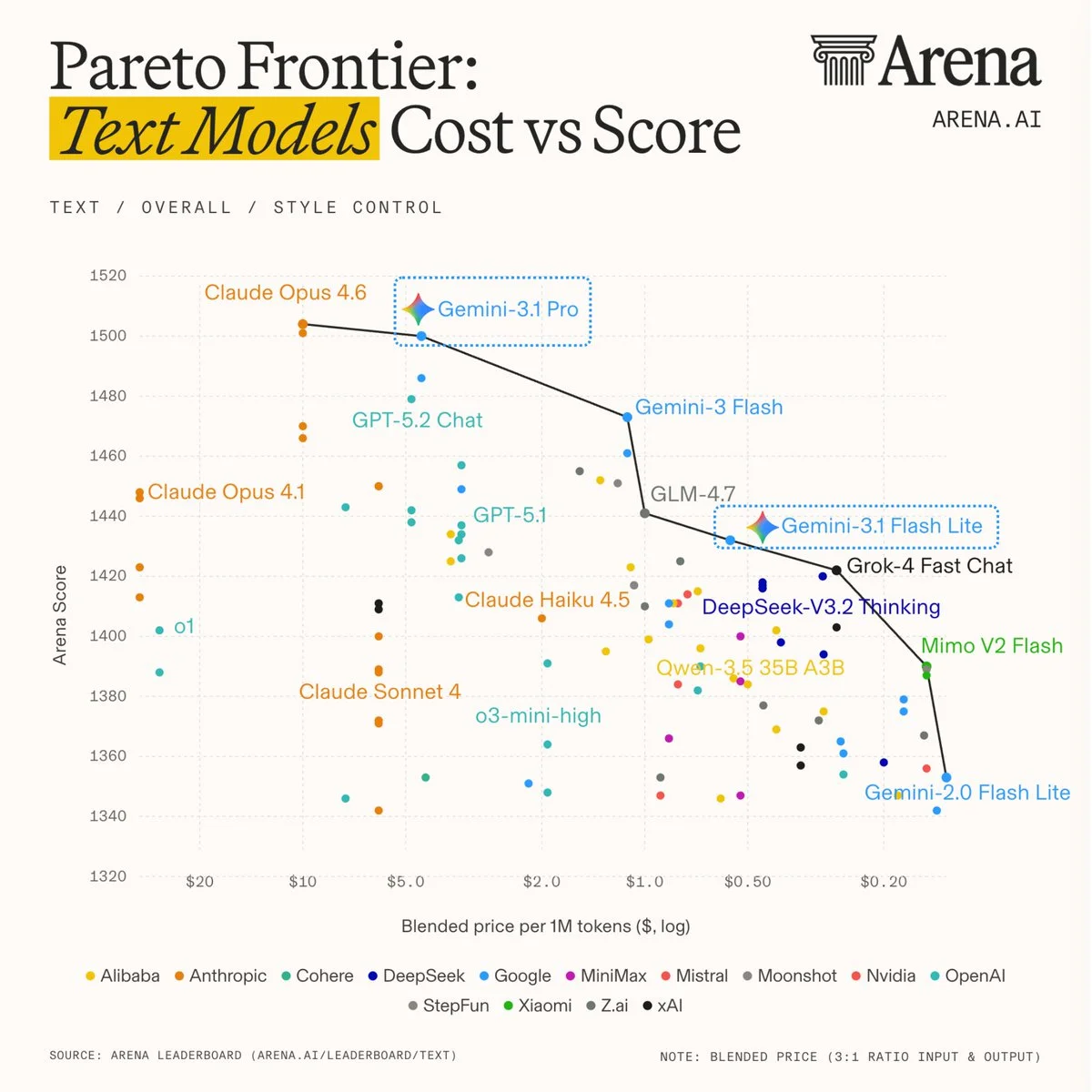 Sources:
Sources: 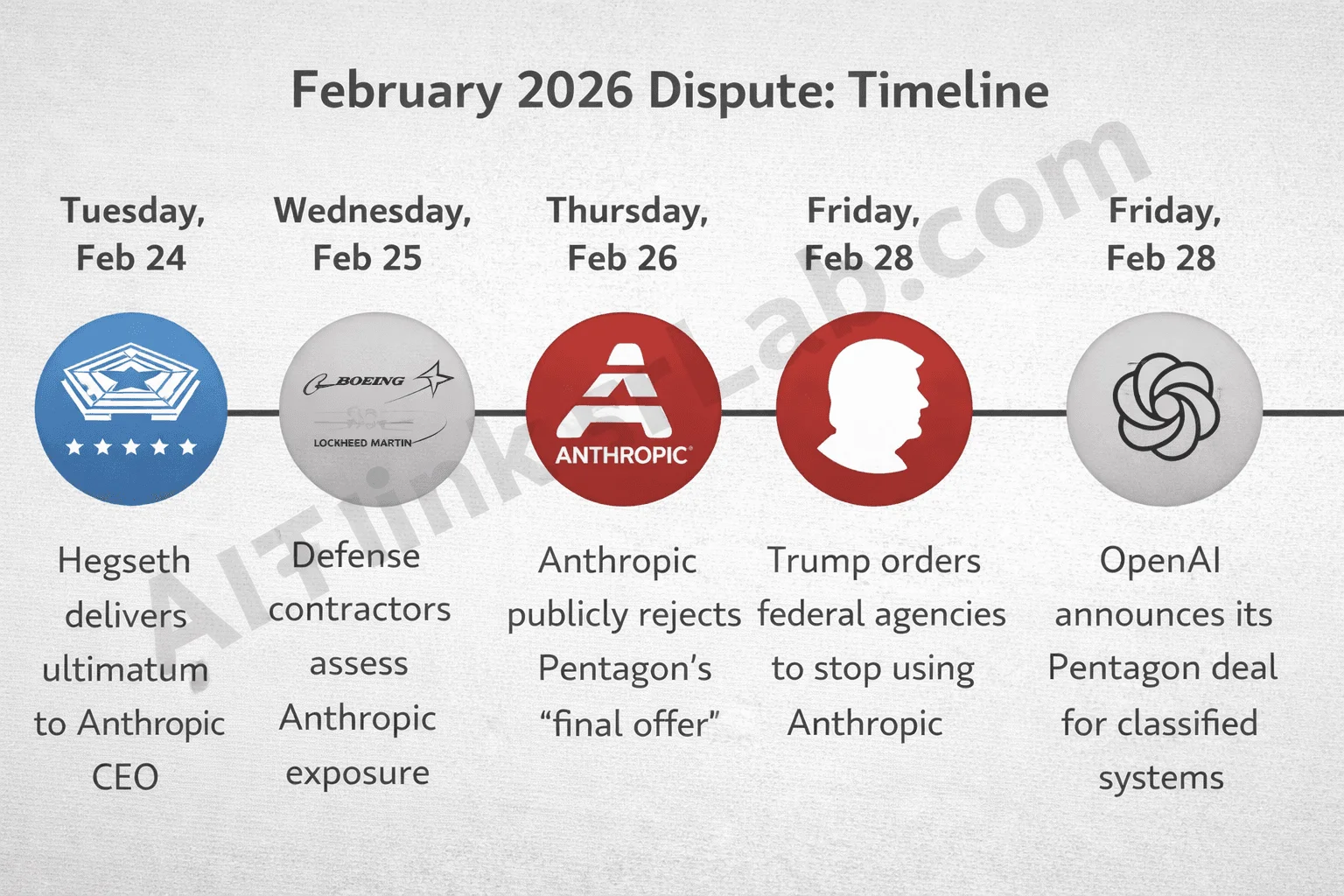
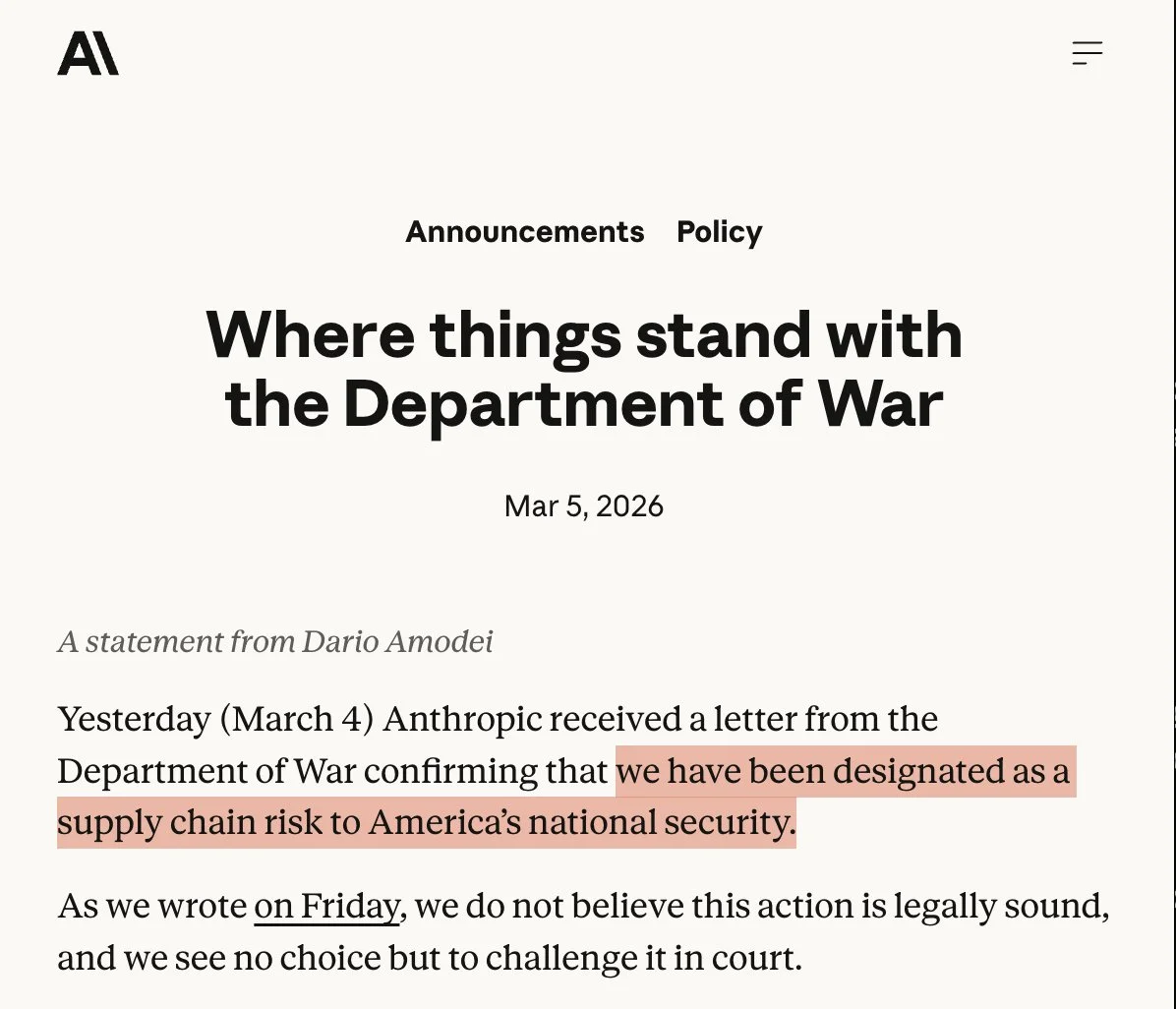
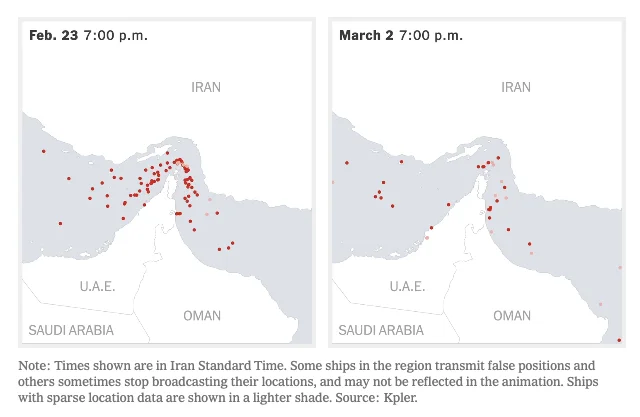 Sources:
Sources: 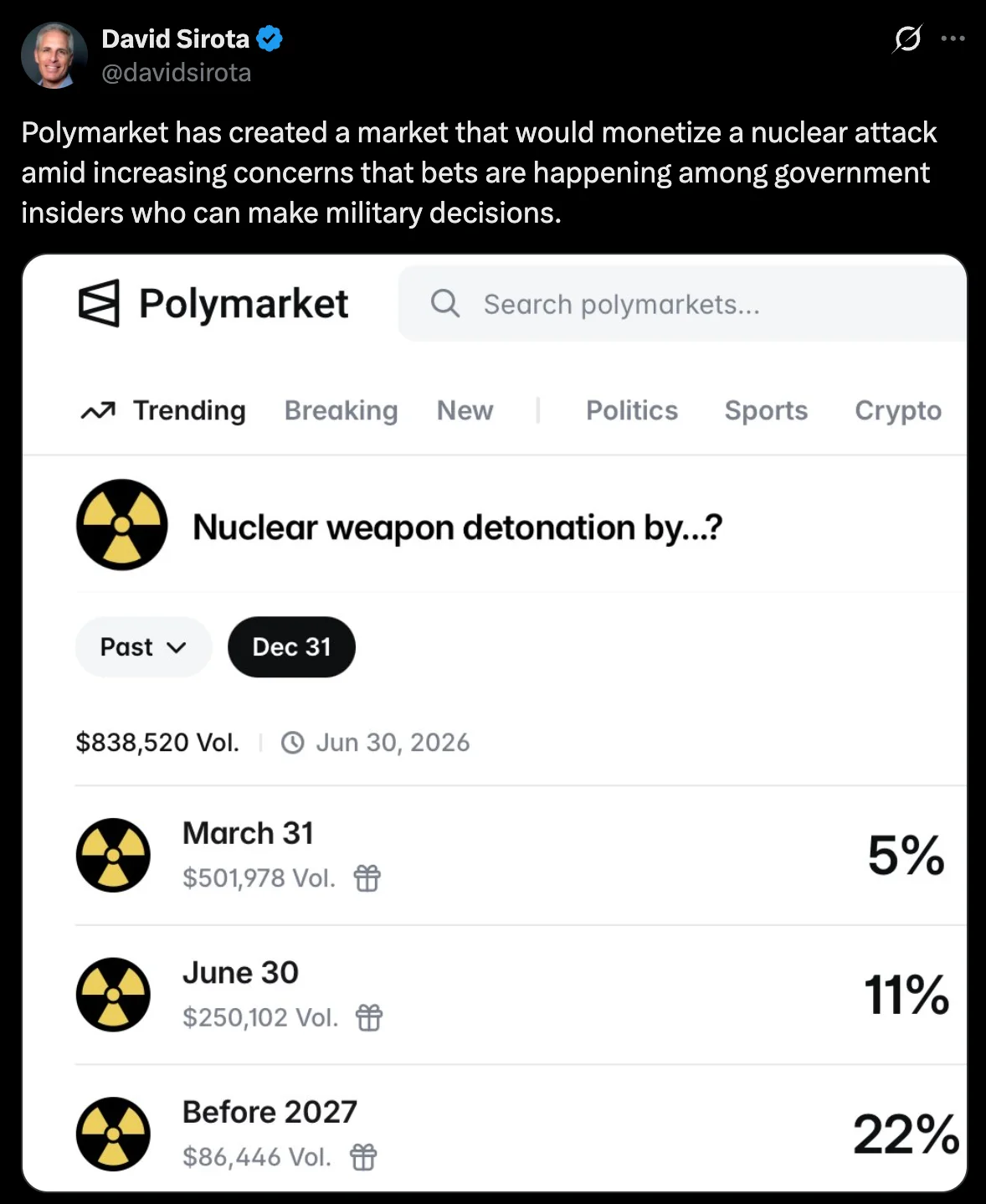 Sources:
Sources: 
 The Head of AI Safety at Meta.. just nuked her entire personal emails archive by giving access to her OpenClaw bot and asking and ask to remove some email. Well, the request went through the /compact context of the agent, it probably lost the details of what the ask was, and started deleting all the emails and couldn't stop it.
Sources:
The Head of AI Safety at Meta.. just nuked her entire personal emails archive by giving access to her OpenClaw bot and asking and ask to remove some email. Well, the request went through the /compact context of the agent, it probably lost the details of what the ask was, and started deleting all the emails and couldn't stop it.
Sources:  A short note on Citrini Research’s viral blog post “The 2028 Global Intelligence Crisis,” which briefly rattled markets and triggered a sell-off in software, tech, and payments stocks (Dow fell ~1.7%, S&P 500 ~1%). It’s a well-written doomer scenario on the post-AI job market — white-collar displacement → collapsing middle-class consumption → deflationary spiral by 2028 — and while the prose is solid and the logic sounds compelling, it rests on several flawed economic assumptions that only hold up if you’re not deep in labor economics, productivity dynamics, or macro feedback loops.
Sources:
A short note on Citrini Research’s viral blog post “The 2028 Global Intelligence Crisis,” which briefly rattled markets and triggered a sell-off in software, tech, and payments stocks (Dow fell ~1.7%, S&P 500 ~1%). It’s a well-written doomer scenario on the post-AI job market — white-collar displacement → collapsing middle-class consumption → deflationary spiral by 2028 — and while the prose is solid and the logic sounds compelling, it rests on several flawed economic assumptions that only hold up if you’re not deep in labor economics, productivity dynamics, or macro feedback loops.
Sources: 
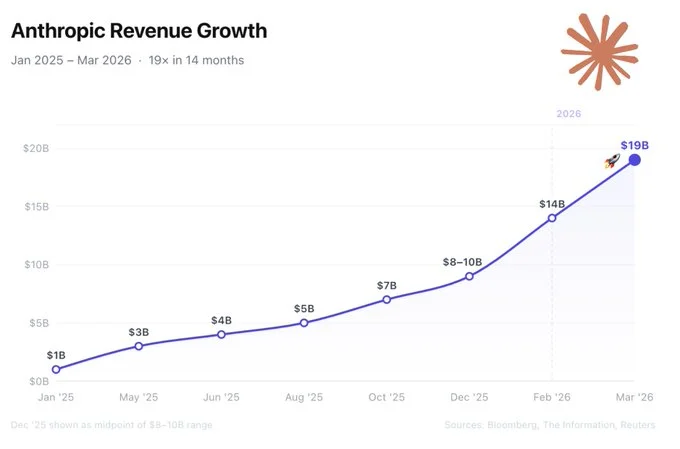
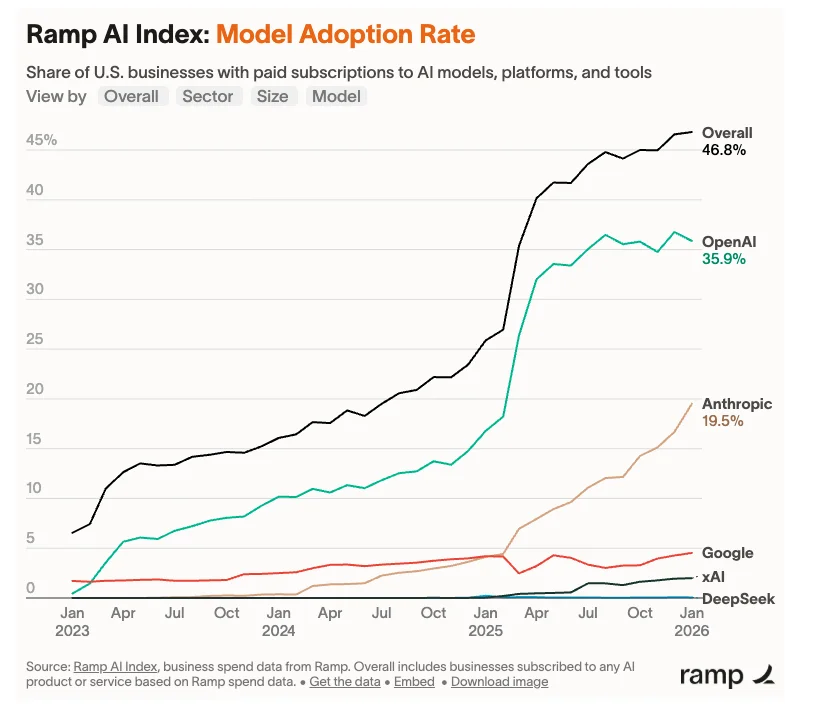
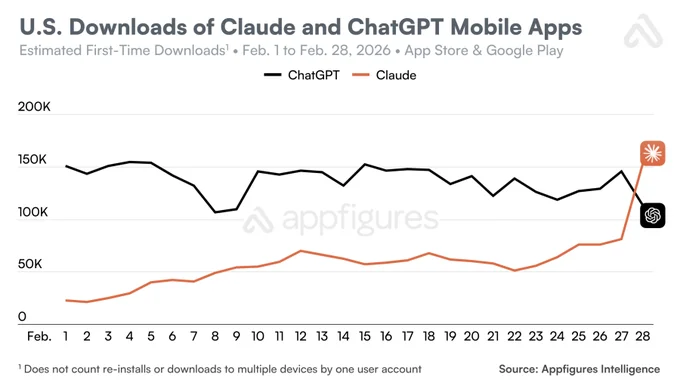


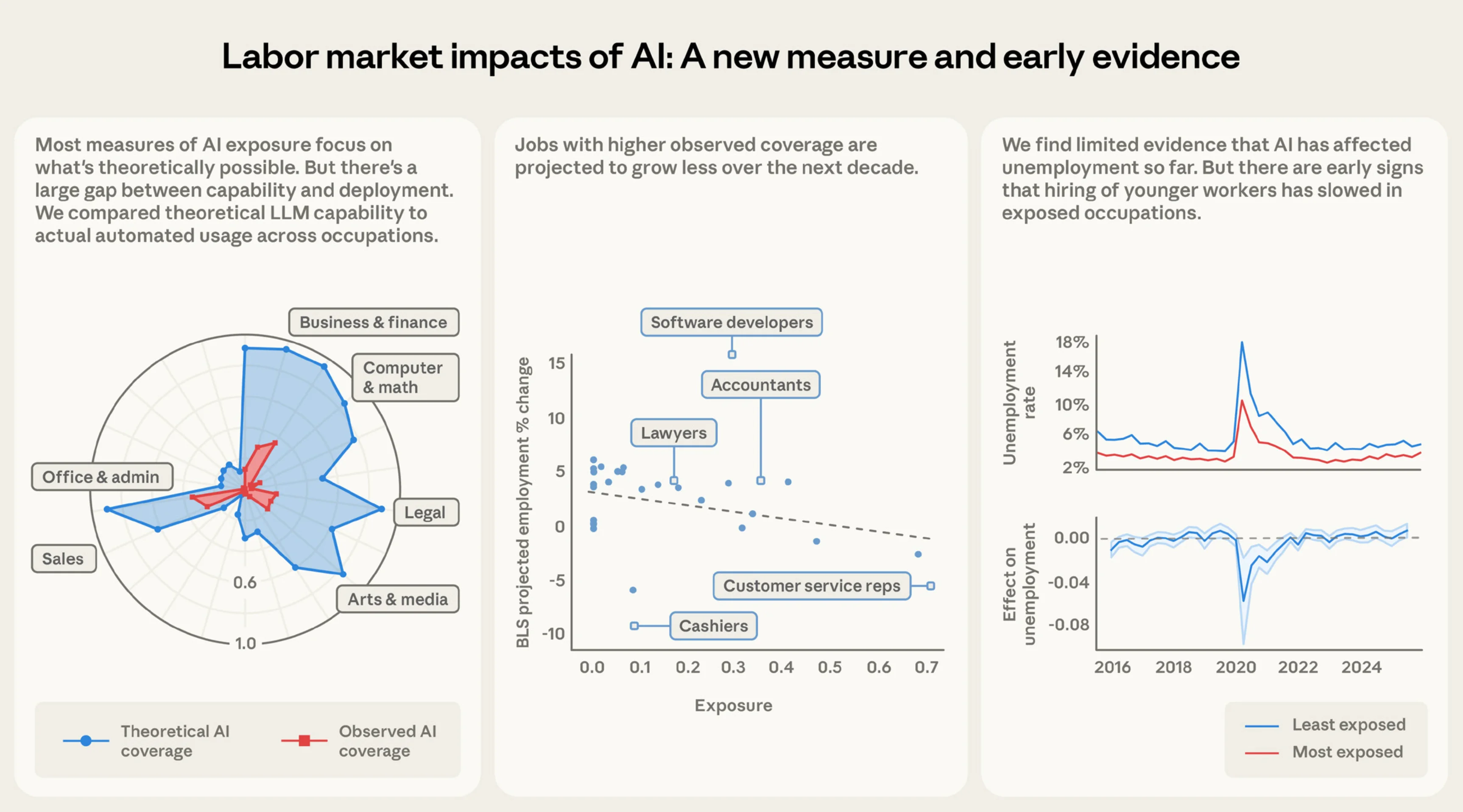

 Sources:
Sources:  Sources:
Sources: 

 Sources:
Sources:  Sources:
Sources: 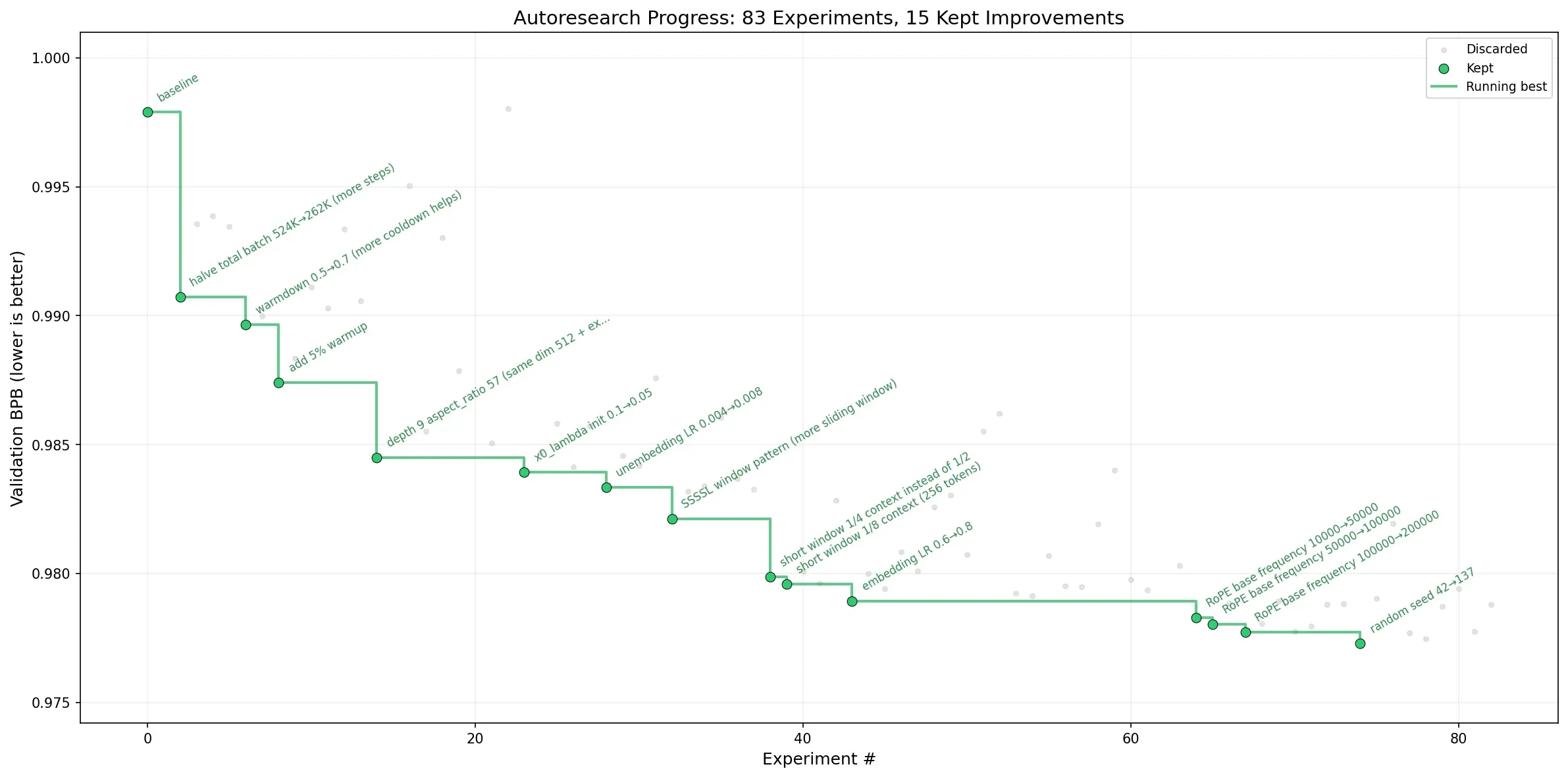
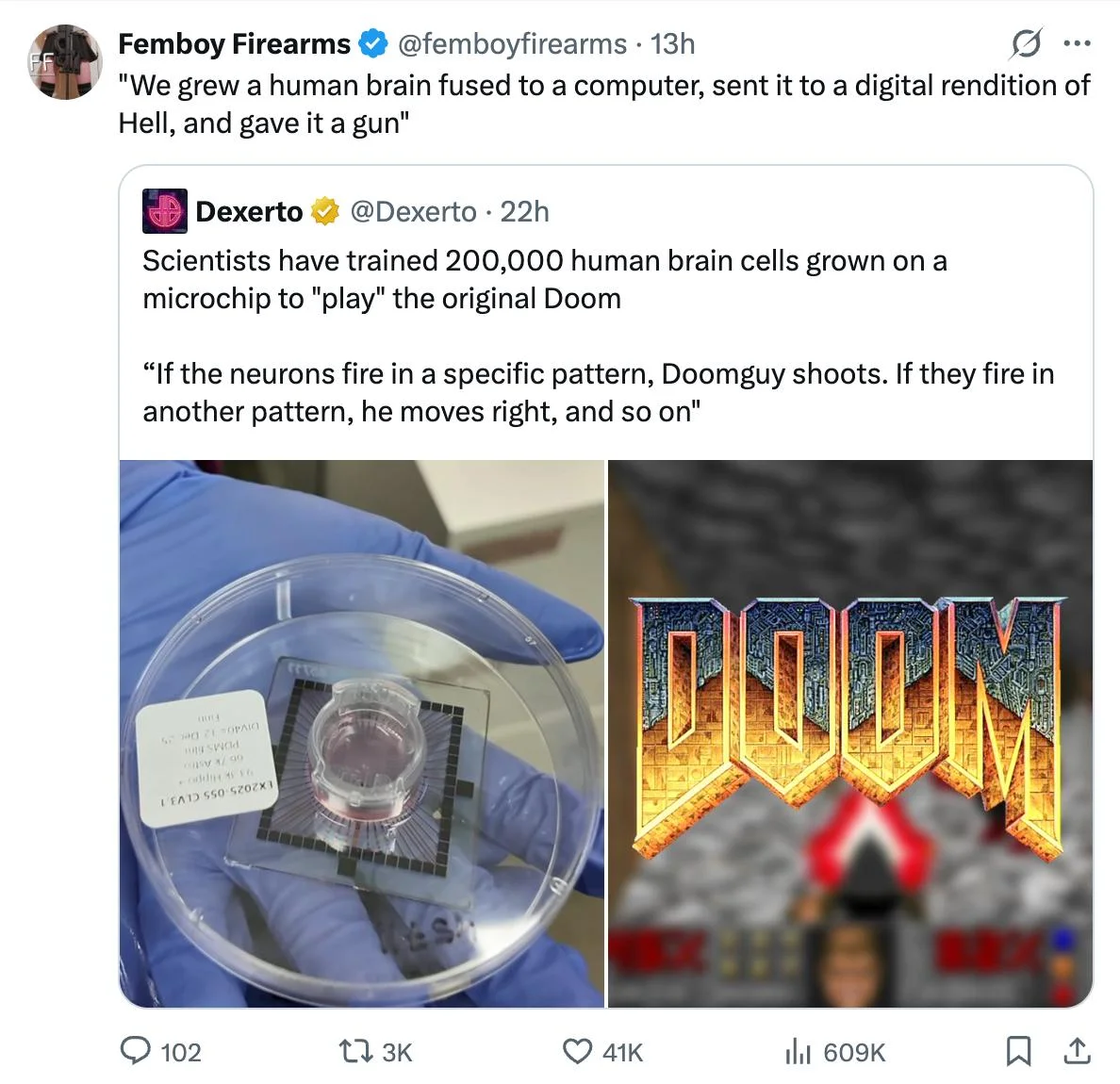
 Sources:
Sources:  Sources:
Sources:  Sources:
Sources: