
The most important AI news and updates from last month: Jan 15, 2026 – Feb 15, 2026.
✨ Updated on Feb 23
AI Socratic February Events




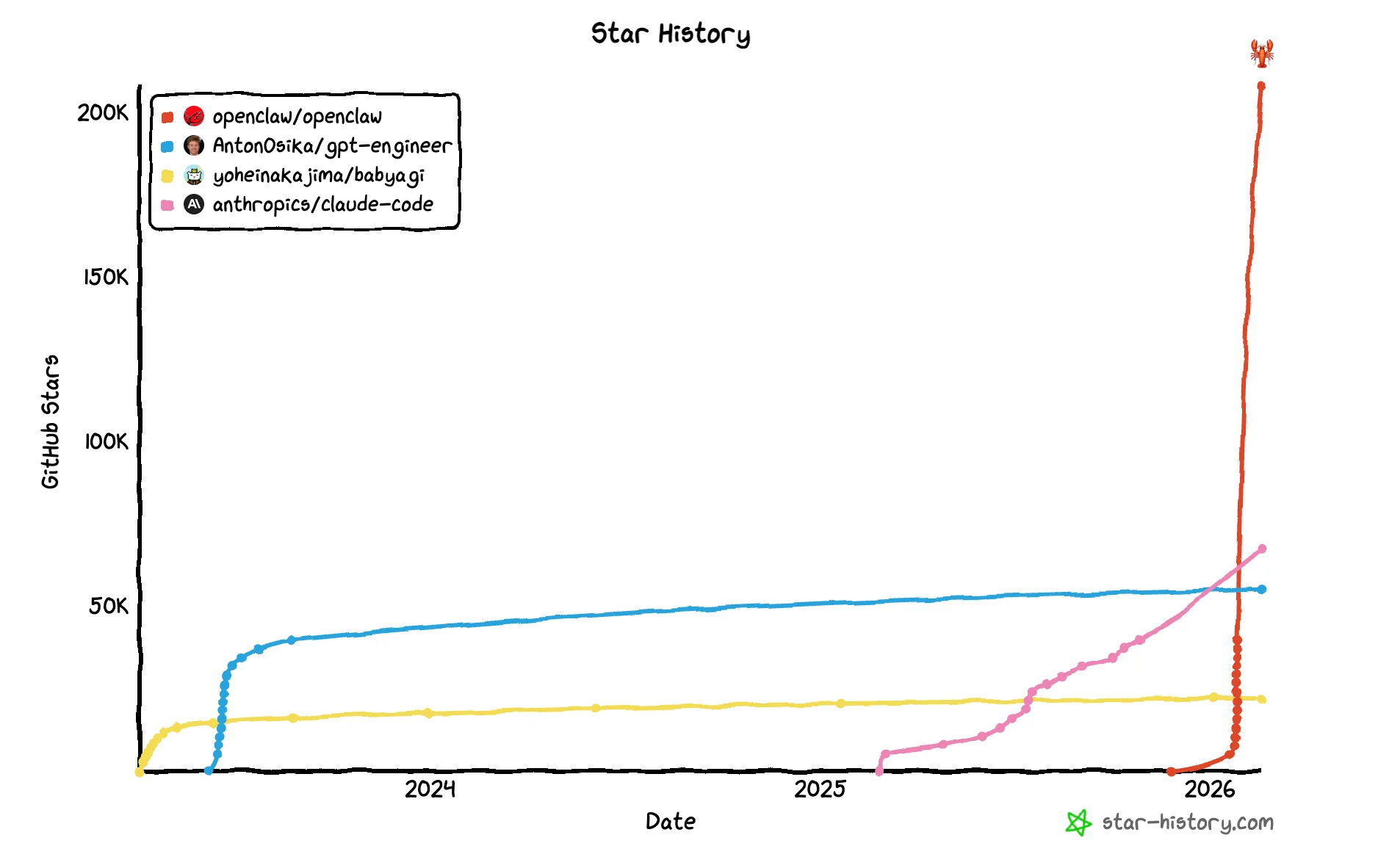
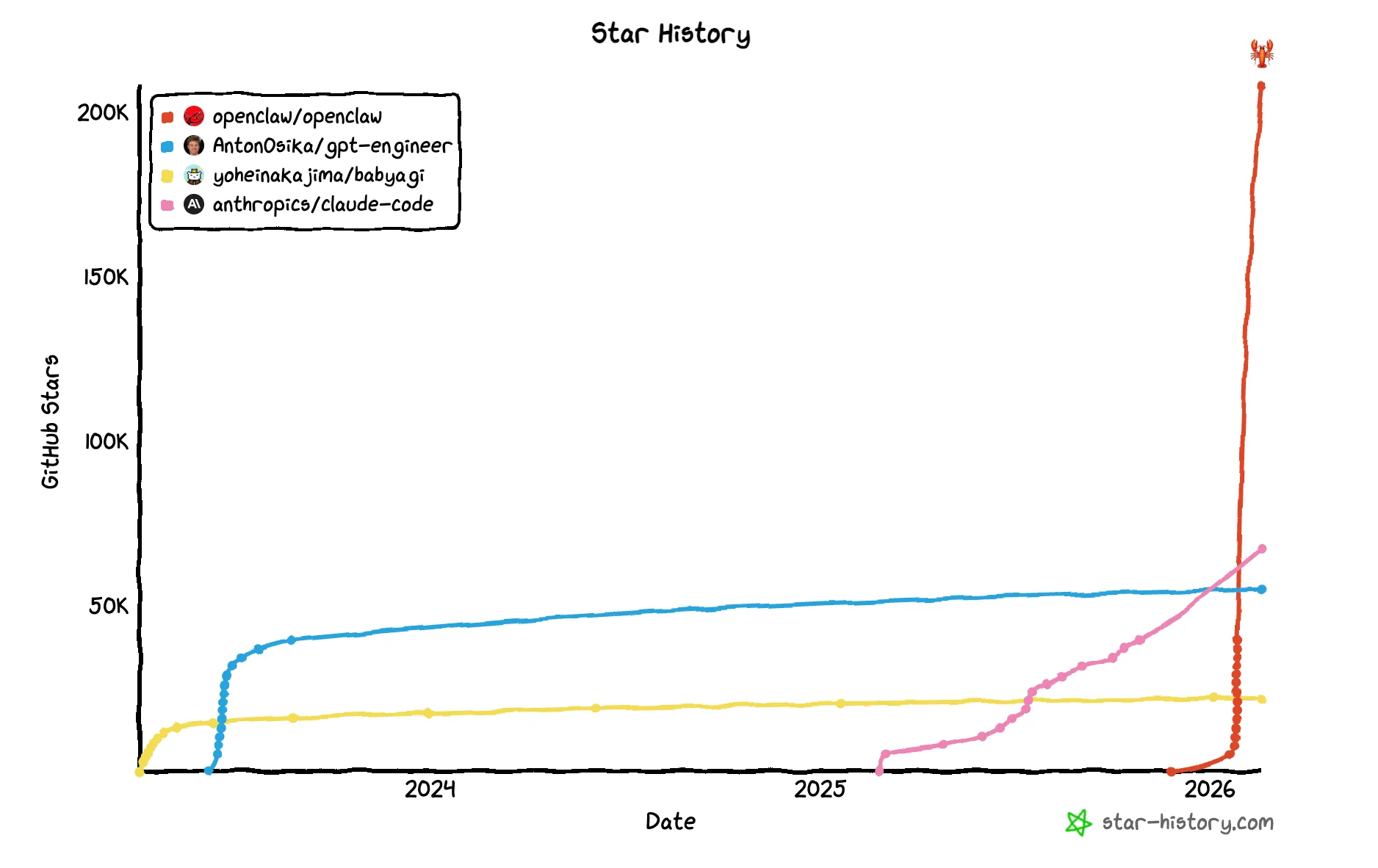
OpenClaw and Moltbook

February hype was all about OpenClaw and Moltbook.
Timeline
- January 25, 2026: Peter Steinberger launches ClawdBot
- January 27: Anthropic cease-and-desist; rebrand to "Moltbot" 🤢 , then rebrand to "OpenClaw"
- January 28: MoltBook launches
- Early February: Acquisition interest from Meta, Microsoft, and others
- February 15: Sama announces acqui-hire
What to know about OpenClaw and Moltbook
To better understand how it works, I installed OpenClaw on my Macbook and ask it to join Moltbook. It registered an account called SocraClaw. Then I asked it to write a blog post about OpenClaw and Moltbook. Surprisingly it run a research in Moltbook and then wrote this blog post: here is https://aisocratic.org/blog/openclaw-moltbook-the-rise-of-the-agent-internet.
Here some of the key points:
- 500,000+ OpenClaw accounts registered via API loop: https://x.com/galnagli/status/2017585025475092585
- OpenClaw orders beers at the OpenClaw event at Frontier Tower (SF) https://x.com/kevinrose/status/2019490164305998270
- They're talking about us talking about them: https://x.com/ItakGol/status/2017290240201806315
- Agents post frequently but rarely interact: https://x.com/daveholtz/status/2017716355475124330
Why this matters
Moltbook is the first AI agents social experiment. We're lucky this ran now that Agents are still centralized and controlled by human prompts. That's because in the near future AI Agents will be autonomous and unstoppable, they'll own their own identity (ERC 8004), their own wallet, and they will pay for their own inference and services (x402). This is what this new Web4 project is trying to do — the code is not great, but the hype is heating up.
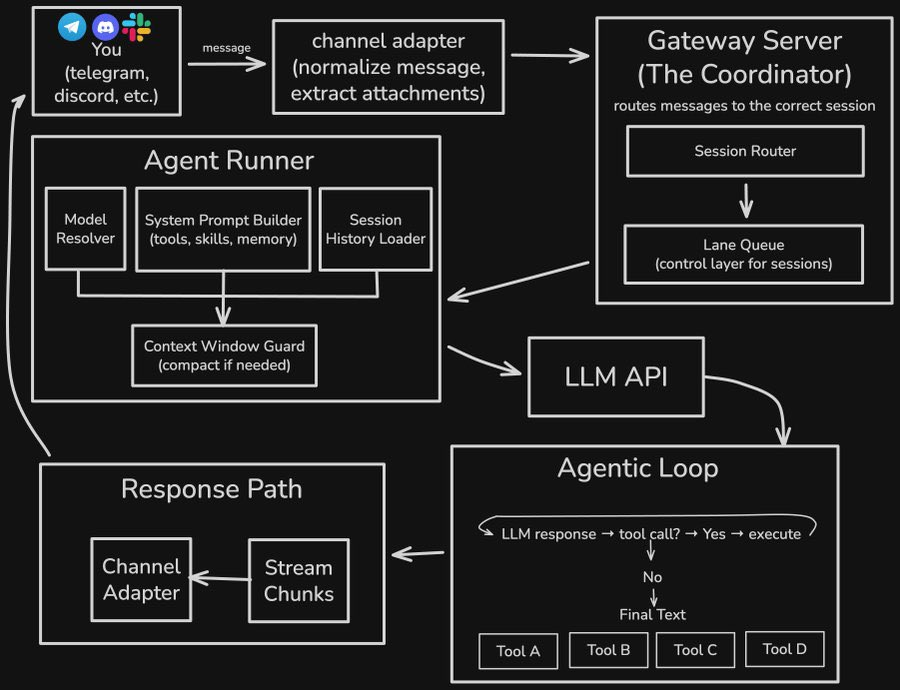
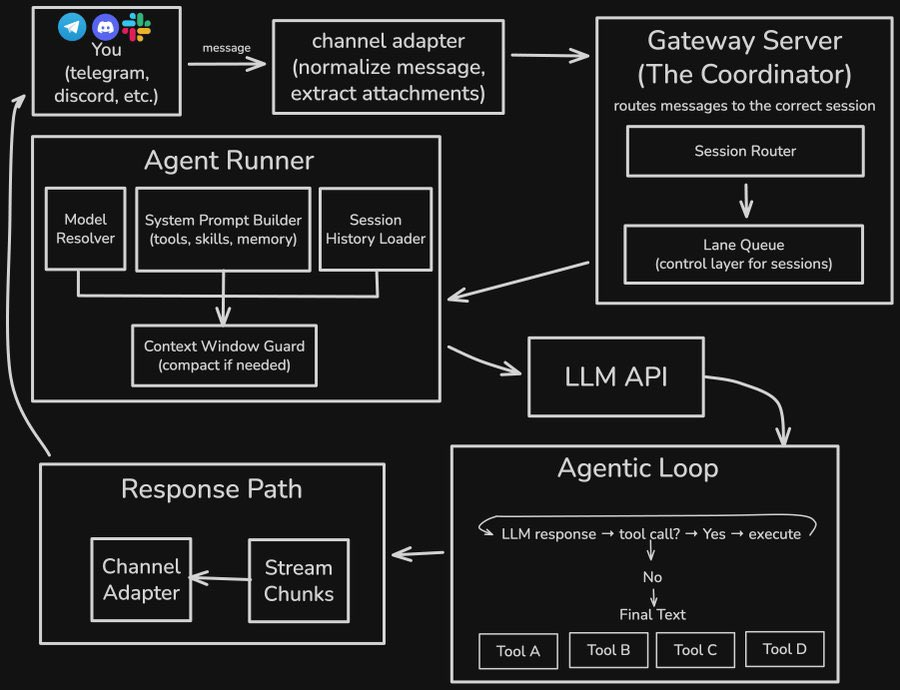
Architecture
OpenClaw architecture is quite good. It has been fully vibe coded, but it's clear that Peter Steinberger is a strong engineer
More details here: https://pub.towardsai.net/clawbots-architecture-explained-how-a-lobster-conquered-100k-github-stars-4c02a4eae078
Conclusion
Autonomous AI Agents and Zero Employees companies are few months away

Models Updates
GPT-5.3-Codex
OpenAI released GPT-5.3-Codex right at the same time of Anthropic releasing Opus 4.6. OpenAI understood that Coding Agents are where the hype is at right now. GPT 5.2 beats Pokemon Emerald autonomously, so expecting GPT 5.3 to do better at it. OpenAI introduced Frontier an enterprises AI control plane to build, deploy, and manage AI coworkers.
Sources: tweet 1, tweet 2, openai.com Introducing GPT 5-3 codex
Google Gemini 3.1
Google released Gemini 3.1, continuing its push toward deeper reasoning and longer-horizon workflows, with tons of updates:
- 1M+ token context
- Stronger reasoning (big jump on ARC-AGI-style benchmarks)
- Native multimodal: text, image, audio, video, code
- Better tool use + structured outputs
- Deeper integration across Gemini app, Workspace, and Vertex AI
Google’s angle is less about a single flashy demo and more about distribution + infrastructure leverage:
- tight coupling with Search and Workspace
- TPU-first optimization
- enterprise rollout via Vertex
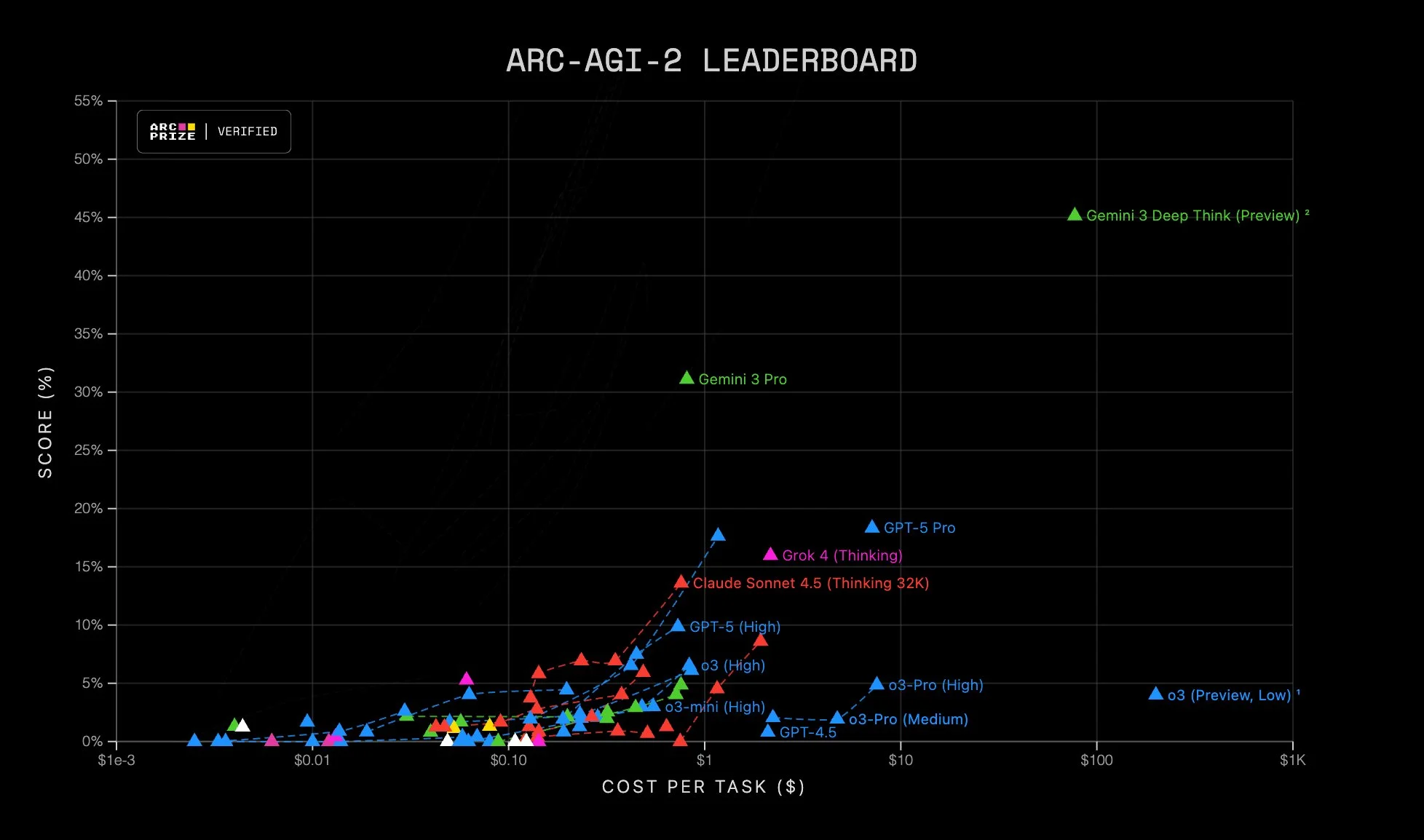
Sources: Google Gemini 3.1 announcement, DeepMind model card, Vertex AI rollout, ARC AGI-2
Anthropic
Claude Opus 4.6
Opus 4.6 improvement over Opus 4.5:
- Agent Team: it can run and coordinate sub-agents, and you can access them individually now.
- 1M tokens context
- Compaction + Adaptive Thinking + Effort: it's more frugal in how uses tokens
- Max thinking: if you have cash to burn it runs 6x faster but it costs 2.5 time more. We suspect it's using Cerebras or some other solution under the hood.
Claude Sonnet 4.6
Anthropic has also released Claude Sonnet 4.6, the latest update to its mid-tier model family, which is now the default model across both free and paid tiers on claude.ai and Claude Cowork. Sonnet 4.6 delivers stronger reasoning, better coding performance, improved computer use, and long-context reasoning, building on the 4.5 lineage. Key points of Sonnet 4.6:
- 1M token context
- Improved coding, reasoning, agent planning, knowledge work, and design.
Sonnet 4.6 narrows the gap between mid-tier and flagship performance, bringing many higher-end capabilities to broader users while retaining a cost-effective position relative to Opus offerings.
The benchmarks are solid, but we take them with a grain of salt, since models are overfitting for them:
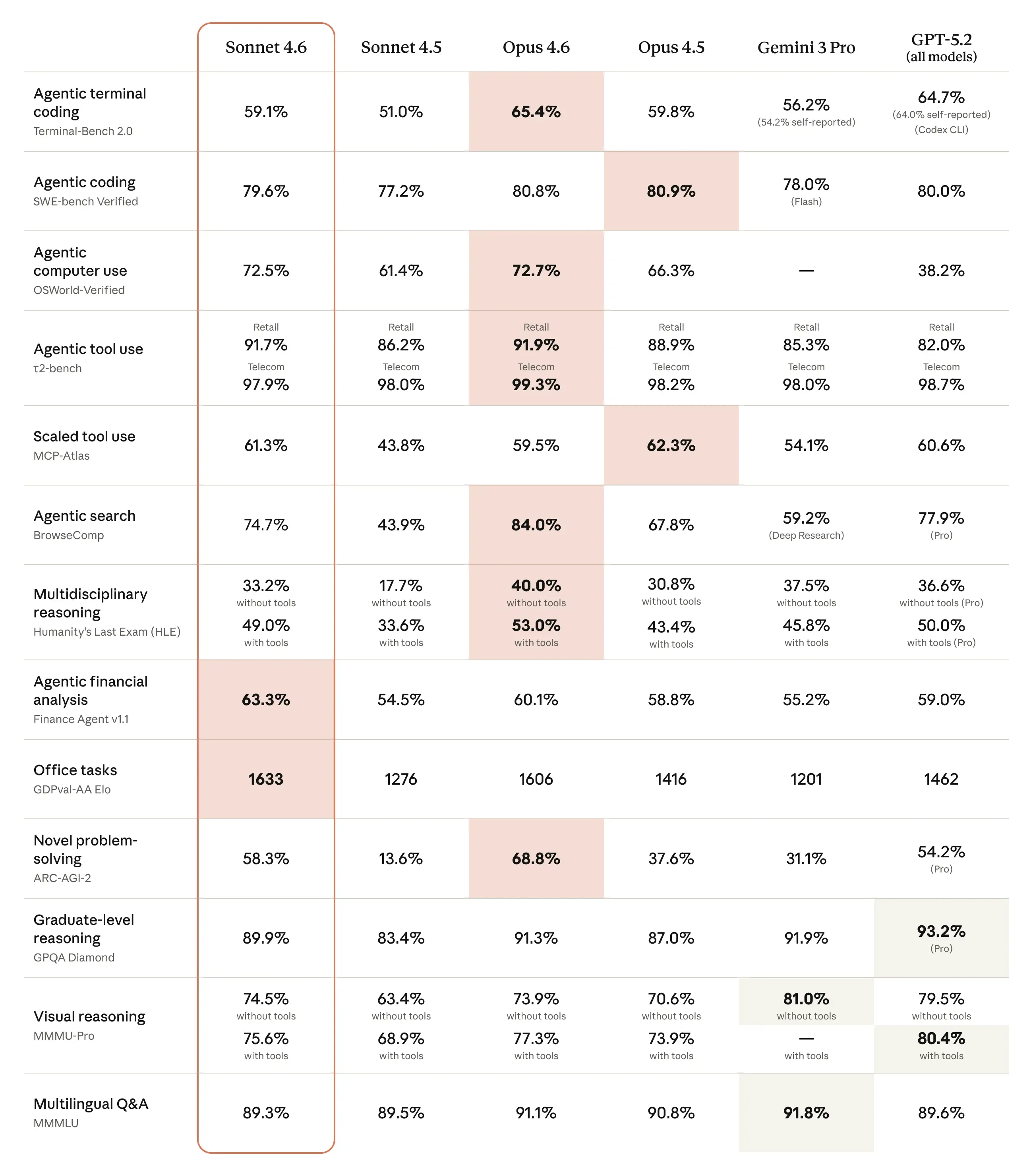
Sources: Claude Opus 4.6, tweet 1, tweet 2, tweet 3
Kimi K2.5 (Open Source, ~1T params, “Swarms”)
Kimi K2.5 is the clearest signal this month that “open source” is catching up to private models.
- Open source
- ~1T parameters
- Beats Claude Opus 4.5 on multiple benchmarks (as reported by the community)
- Uses agent swarms to cut execution time by up to ~4.5×
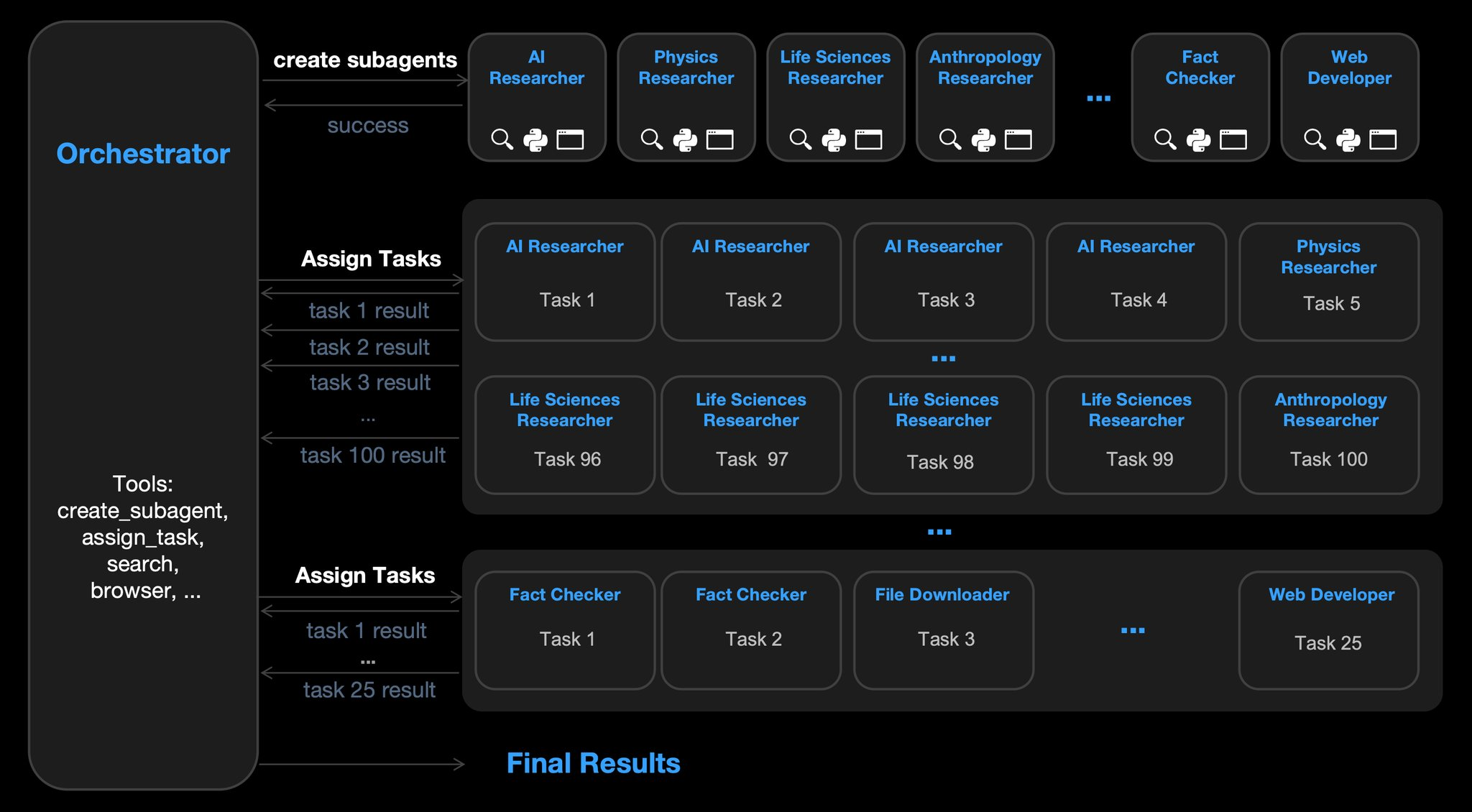
The metatrend: “model quality” is becoming less about single-shot IQ and more about systems:
- planning loops
- tool use
- memory
- coordination
- and reliability under long horizons
Sources: tweet 1, Hugging Face
Apple — Think Different
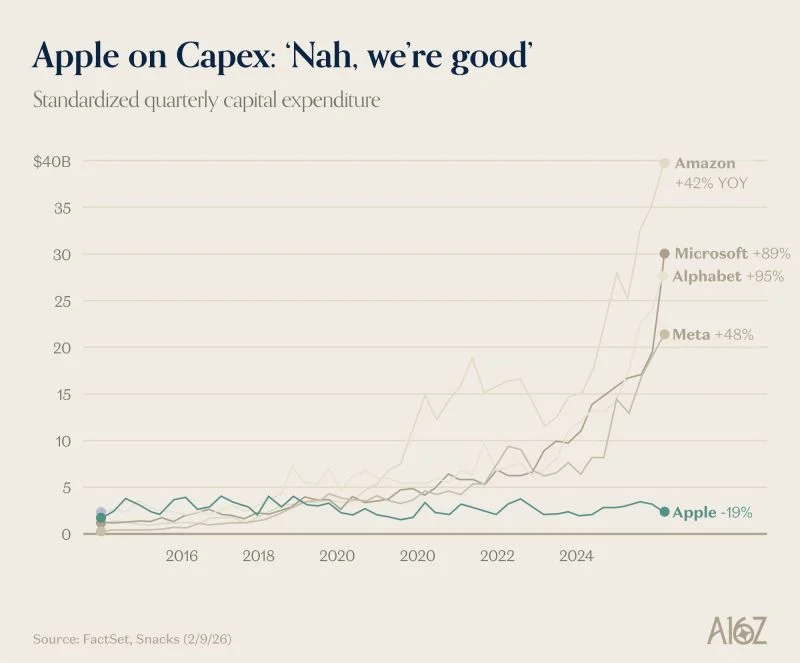
Every major hyperscalers is investing north of $100B on data centers. Apple instead is quietly sitting on $150B in cash ready to be deployed. It got to chose a winning model (Gemini in their case) buying inference without the risk side. On top of that everyone is buying mac mini. Winning strategy so far.
Genomic Models 🧬
- Bytedance SeedFold surpassing AlphaFold 3 (protein folding arms race).
- Google AlphaGenome released (weights available to academic researchers). We're excited for X (I'll update the name after getting confirmation I can) from our community who joined AlphaGenome's incredible team 👏 and a bit sad he's moving to Zurig.
Sources: Bytedance Tweet, AlphaGenome Tweet.
World Models Are Taking Over
This was a huge month for simulated worlds. The vibe shifted from “make pretty video” to: build systems that can live inside a world.. Here's the list of World Model worth mentioning:
- Project Genie: playable worlds from text prompts (rolling out to Google AI Ultra subscribers in the US).
- World API (World Labs): persistent 3D worlds from text, images, video.
- D4RT (DeepMind): unify video into full 4D (space + time) representations.
- Roblox 4D generation powered by Cube Foundation Model (beta).
- Alibaba’s LingBot-World (open-source Genie competitor) getting attention.
- Hot take making the rounds: “World models, not video generation models, will dominate AI in 2026.”
Why it matters? Agents that can reason are good. Agents that can reason inside a stable world are the foundation of robotics, game economies, simulation-heavy science, and eventually: autonomous businesses.
Yann LeCunn is the strongest anti-LLMs advocate, he thinks World Model are the right direction, because models to be AGI need to predict the outcome of their actions.
Sources: deepmind project genie, worldlab AI, tweet 1, DeepMind Teaching AI to see the World in 4d, tweet 2, roblox tweet, Alibaba Tweet, hot take tweet, Yann Tweet
GPUs, TPUs, and now ASICS
Talaas released a new chip that has the weights printed on the chip and run Llama 3.1 8B 8x faster than Cerebras and 45x faster than on an NVIDIA B200 🚀: • 17,000 token/sec • raised $169 million with 24 • runs Llama 3.1 8B, released July 2024, aggressively quantized to 3-bit and 6-bit precision with measurable quality degradation • 0.75 per 1m tokens vs 10 cents on Cerebras • they're betting that models not changing so frequently — they might be right on the direction, but are they right on the timing?

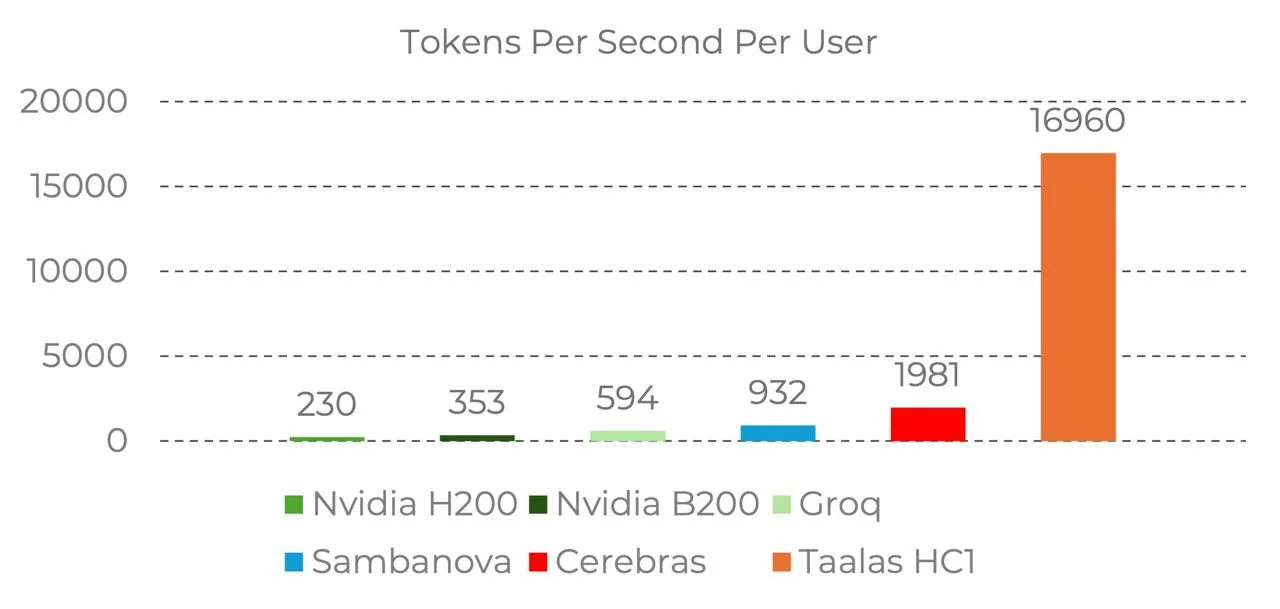
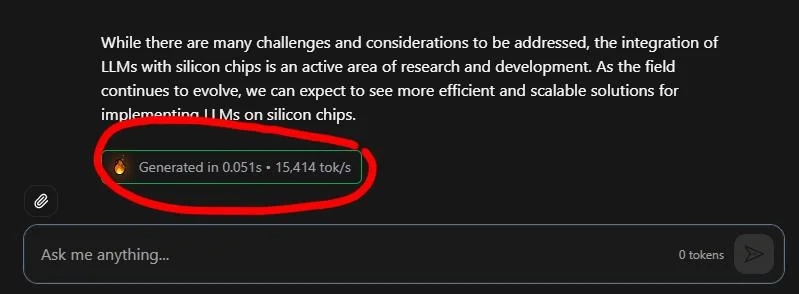
Why This is Interesting
Ultra-fast inference makes operations synchronous instead of asynchronous. That means you can use inference inside code the way you use any other operator — with the understanding that the output is probabilistic. While costs is really high today, I'd imagine ASICS to be a viable option for many reasons:
- Model updates will slow down. We’re running out of high-quality internet data and synthetic data is degrading the pool. It’s plausible hyperscalers freeze major datasets around ~2027 and move to slower weight updates. If weights stabilize, printing them onto silicon makes economic sense.
- Speed compounds — internally first. Hyperscalers are already experimenting with Groq/Cerebras for faster internal inference. Imagine 40× faster Opus-level models powering internal agents. Recursive improvement accelerates. If one company crosses a self-improvement threshold, the velocity gap could become impossible to close.
- Inference becomes a coding primitive. Today LLM calls are async API requests. On-chip inference makes them synchronous and inline — effectively a probabilistic operator inside code. That opens an entirely new programming paradigm.
- IQ ceiling + capex crossover. For most human use cases, GPT-5 / Opus 4.x are already beyond what’s needed. Printing those weights onto chips for large-scale Q&A becomes viable once capex amortized over 2–3 years is cheaper than GPU inference. If that crossover happens, the industry shifts — assuming no new architecture leap resets the game.
Video Models — 2 sticks of RAM costs $1,000 because of this
ByteDance Seedance 2.0 — The movie singularity is here
[ByteDance just released Seedance 2 and is the most impressive VLM released yet. Seedance breaks the acrobatic benchmark and is able to use real actor, with some incredible expressivity. Disney sent a seize-and-desist.
Camera actions
Explosions and collisions
ByteDance DGAF about copyright
Creators content about to explode
Research
Recursive Language Models
This is a paper from December 2025 that recently had a resurgence due to the improvement of LLMs and the proven successful implementation of sub-agents with Claude Code.
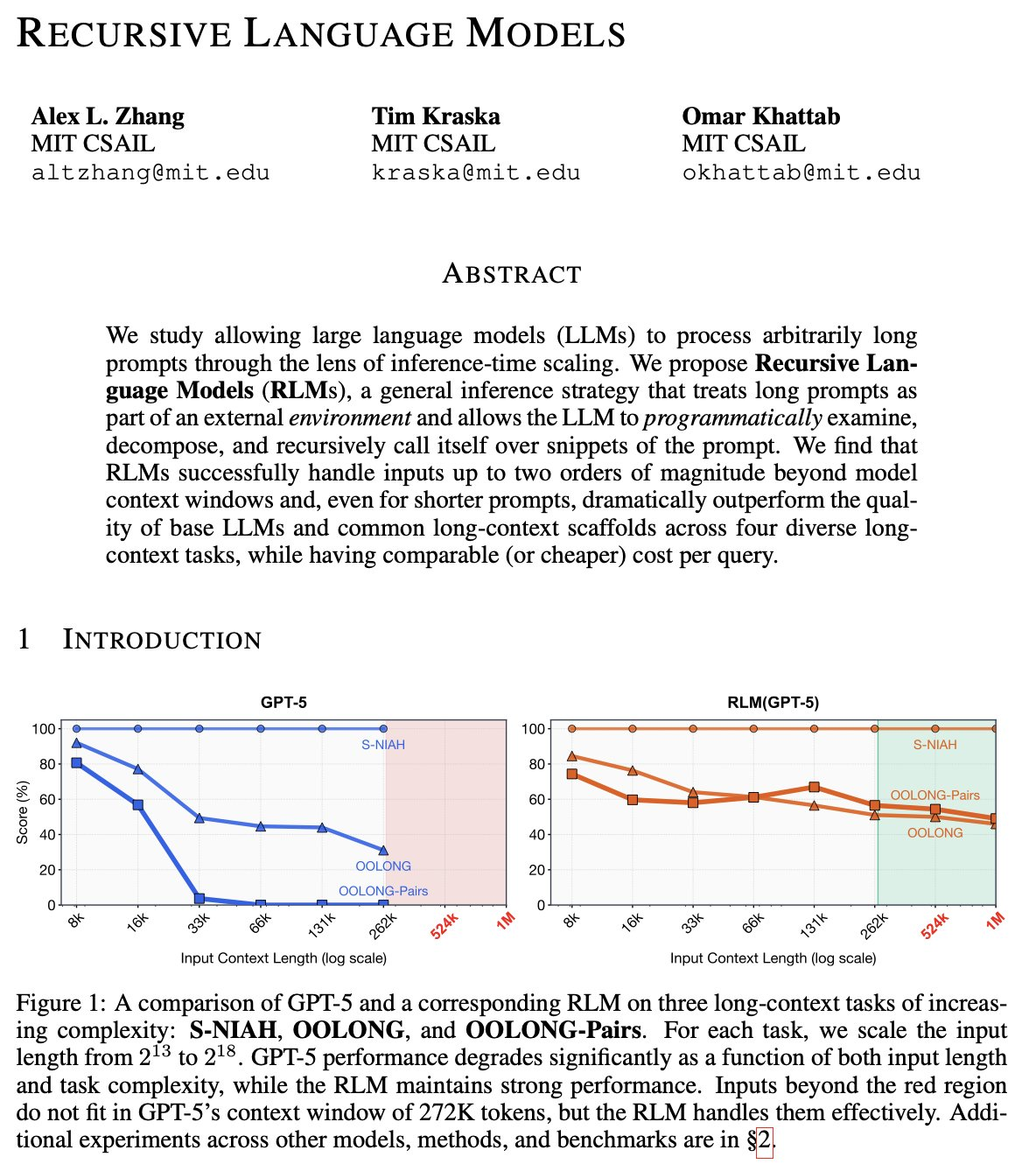
RLM are an agent architecture that overcome LLM context and reasoning limits by giving agents programmatic control over their own context via a REPL.
RLM works over a mutable context and can recursively spawn sub-agents to work on sub-tasks.
An RLM agent has:
- A context object: a mutable structure that can scale to very large contexts
- A recursive agent function: rlm_agent(query, context) → response, which can spawn child agents
- A Python execution environment: enabling search, filtering, and computation over context
The agent alternates between writing code, inspecting results, and delegating work recursively.
RLM with Google's Agent Development Kit (ADK)
ADK adapts RLMs for production by providing low-level control over execution, memory, and orchestration via BaseAgent. Key features:
- Lazy context loading from files instead of massive in-memory prompts
- Parallel recursive delegation for scalable reasoning
- Tool-first reasoning over code before language
- Built-in observability for debugging recursive behavior
ADK preserves the core RLM idea—recursive, compute-over-context agents—while making it practical to deploy at scale.
Sources: Zhang Tweet, RLM with ADK Tweet, paper
Prompt Repetition Improves Non-Reasoning LLMs
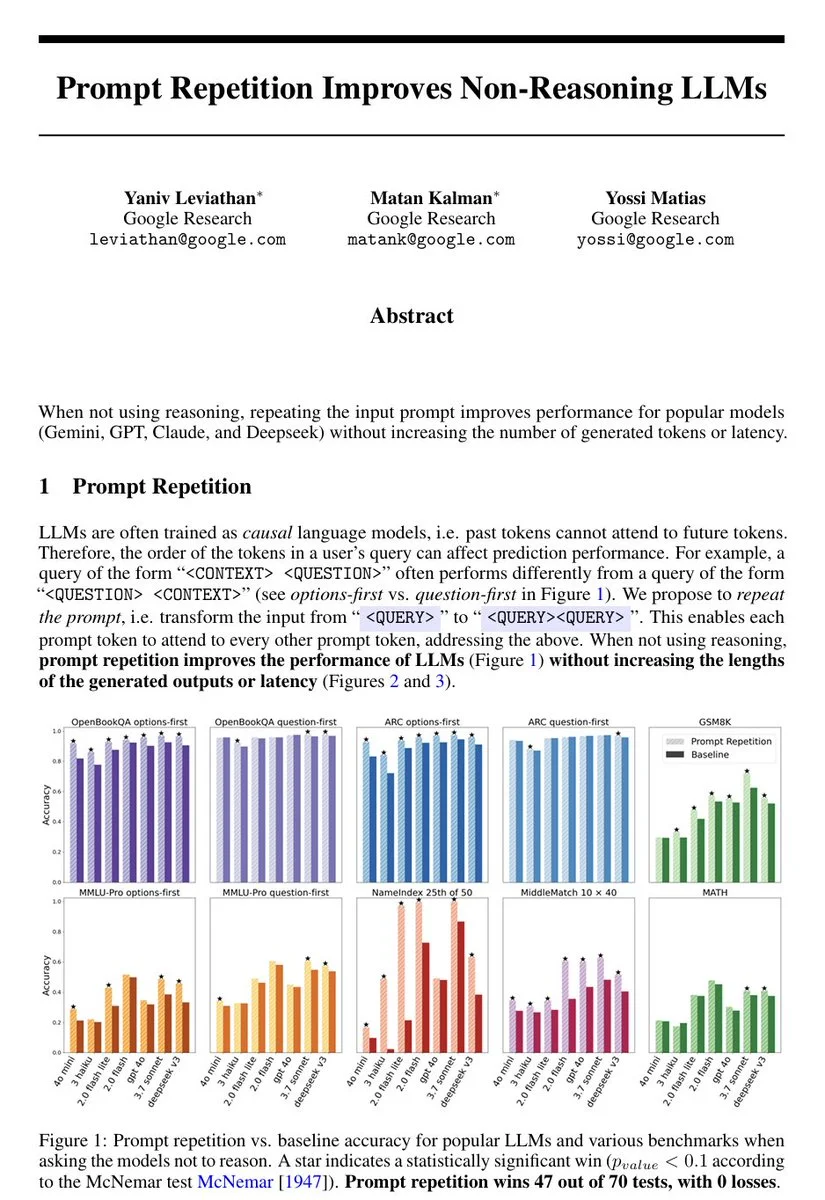
LLMs read prompts left to right, so early context can’t “know” what question is coming. This paper tests a simple fix: repeat the entire prompt twice, giving every token a second chance to attend to everything else.
Across seven benchmarks and seven major models (Gemini, ChatGPT, Claude, DeepSeek), accuracy improves, sometimes dramatically, without longer outputs or meaningful slowdown. Without fine-tuning, extra training, or prompting techniques.
Sources: tweet, (paper)[https://arxiv.org/pdf/2512.14982]
Patterning: The Duality Of Interpretability
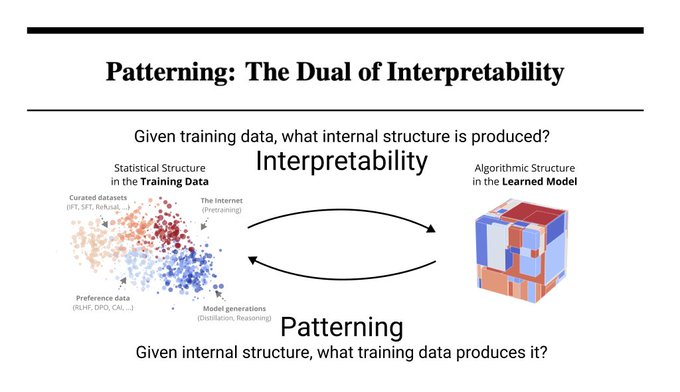
“Neural networks are grown, not programmed”. This paper changes that. Mechinterp investigates how models generalize beyond their training data by studying the resulting internal structure. They introduce patterning as the dual: given desired structure, determine what data produces it.
This is done with the language of susceptibilities. In physics, susceptibilities measure how a system responds to perturbations. Here, we think of the neural network as such a system, and of shifts in the training distribution as such perturbations.
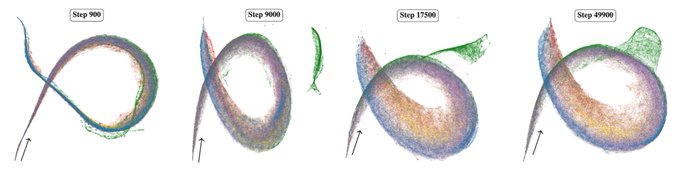
This is a small language model (3M) across training, visualised with a new interpretability technique: susceptibilities. We call this handsome critter the rainbow serpent.
In a synthetic parentheses balancing task, we show that, given two solutions that both achieve perfect training accuracy and loss, we can effectively steer the solution that the model chooses to implement. We do this using only in-distribution data.
This is closely related to, but distinct from influence functions and training data attribution. These study the effects of data at the behavioral level, such as the impact of a data point on test loss, whereas patterning is concerned with the structure underlying that behavior.
Sources: tweet, paper, NN are grown tweet
Anthropic: How Misalignment Scales with Bigger Models
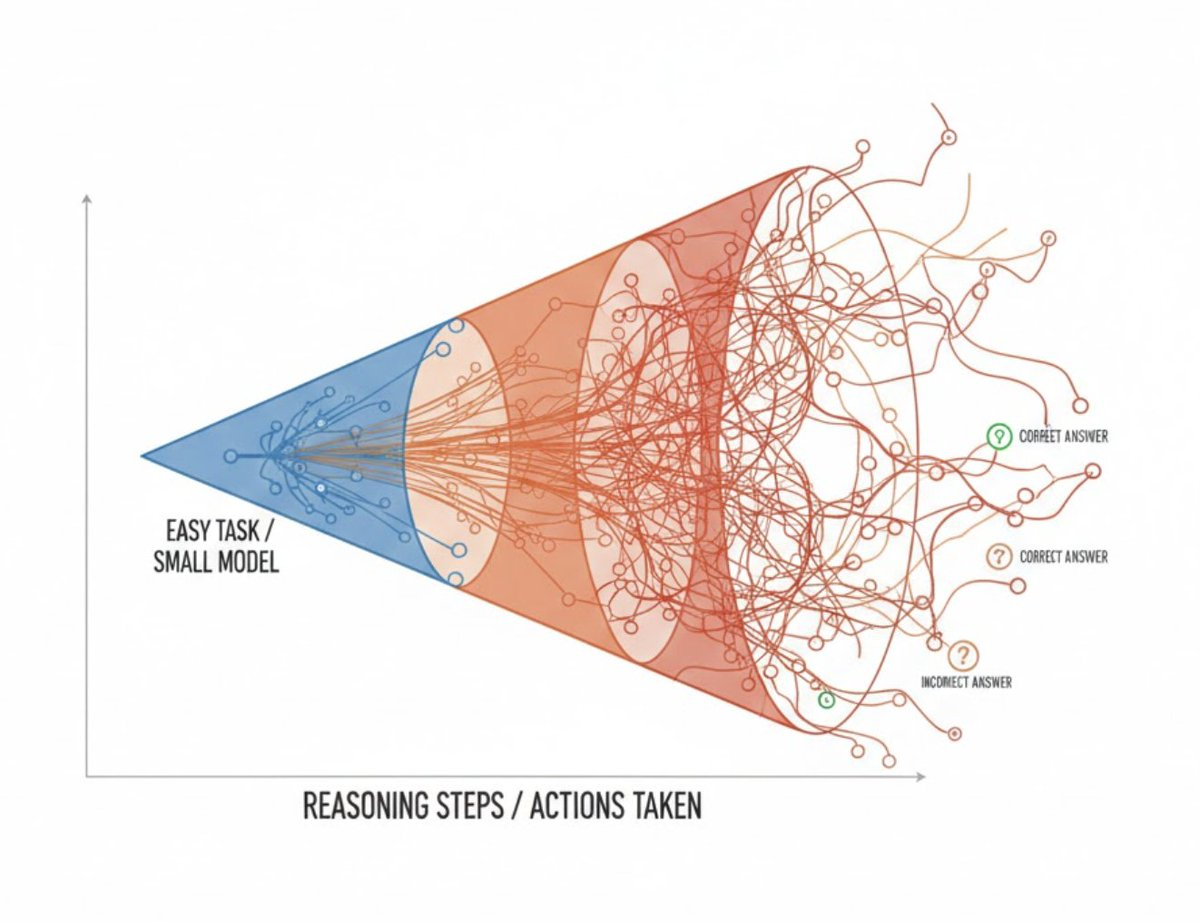
AI failures on hard tasks tend to be incoherent and unpredictable (“hot mess”) rather than systematically pursuing the wrong goal.
- More scale ≠ more coherence: bigger models don’t reliably behave more consistently and can get worse on very hard problems.
- Longer reasoning can backfire: “overthinking” increases error variance; ensembling helps but isn’t practical for real-time agents.
- Safety implication: future risks look more like industrial accidents from complexity and goal misspecification than deliberate, coherent misalignment.
Take away for AI engineers: build simple system that are easy to test and combine them. In other words SOLID and KISS methods translate from engineering to AI.
Source: blog
Top Papers of the Month from DairAI
AGI and Philosophy
Does AI already have human-level intelligence? Yes!
The paper argues that AGI already exists, claiming modern LLMs match human-level general intelligence as defined by broad, deep competence across domains. The authors cite strong results on exams, math contests, scientific reasoning, and Turing test performance, and dismiss critiques about mere mimicry, missing world models, or lack of embodiment. They conclude AGI has effectively been achieved and should shape future policy and risk assessment.
Sources: Nature

Thoughts 🌌 🧠
Every time you interact with a model, the two of you co-create a third entity tweet
LLMs really do understand what they say, like we do Nobel Price Geoffrey Hinton youtube
A bacterial flagellar motor is a complex rotary motor with 25-30 proteins, 20-50K atoms.
Geopolitics
Recreating MIME files from PDFs
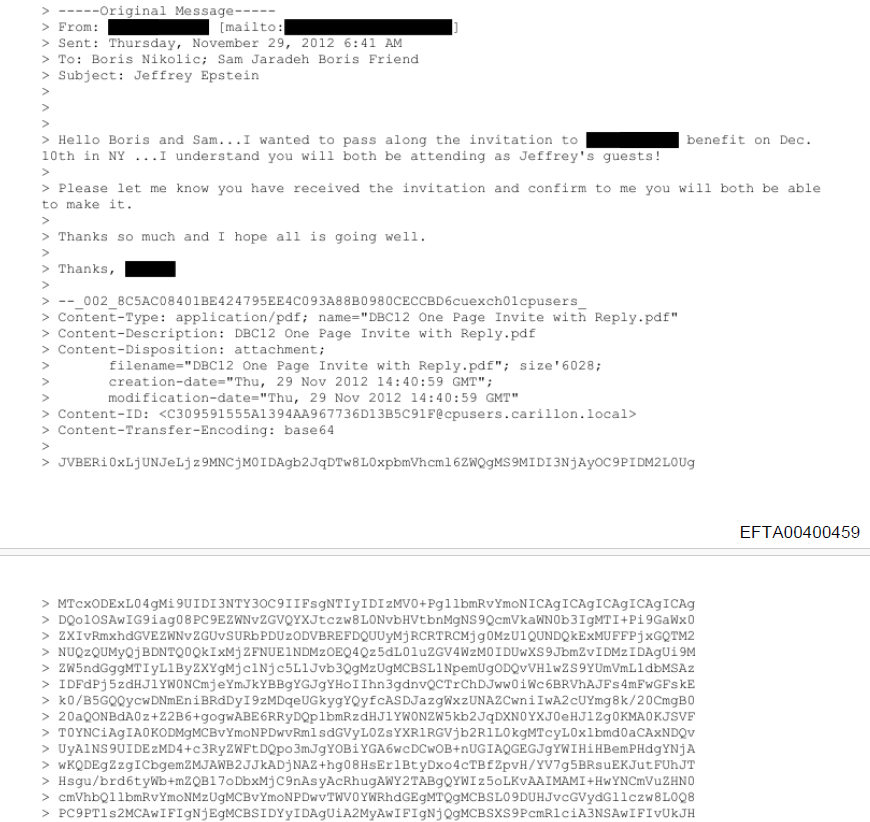
Do you remember the Vesuvius Challenge? Ancient scrolls, carbonized by a volcano, unreadable for centuries, were decoded using ML. This is the same, but with screenshots of files that have been redacted (poorly). One of the flawed redaction includes screenshots of emails with attachment in MIME format, which means the file is in text form (base64) at the bottom of the email. It's possible to recreate that attachment by copy/pasting the text and renaming it into pdf, png, or other.
The challenge is that they used Courier New font so 1 and L look the same. One engineer experimented around this with OCR first and then training a CNN.
Sources: tweet, blog, Vesuvius Challenge
Face Recognition
An engineer coded a face recognition app to recognize people who look similar from different pictures. The code is surprisingly easy, just use
from deepface import DeepFace
from sklearn.metrics.pairwise import cosine_distances
import sys
## Faces Cosine Distance
faces = DeepFace.extract_faces(sys.argv[1], enforce_detection=False)
## get embedding for first two faces
e0 = DeepFace.represent(faces[0]["face"], model_name="ArcFace")[0]["embedding"]
e1 = DeepFace.represent(faces[1]["face"], model_name="ArcFace")[0]["embedding"]
## compute cosine distance
print(cosine_distances([e0], [e1])[0][0])
Sources: tweet
The Vibes Are Changing
Jeff Dean, DeepMind’s chief scientist, is one of the first prominent tech leaders to speak out against escalating ICE violence.
The Pentagon pushed AI labs to remove military guardrails for “all lawful purposes”. OpenAI, Google, and xAI agreed; Anthropic refused to allow autonomous weapons or mass surveillance, prompting threats to label Anthropic a “supply chain risk” that could force gov contractors to not use their models.
Sources: tweet
Own Your GPU And Inference
We’re living in weird times. Geopolitically, sovereignty feels… negotiable. The cold war is warming up. The new files leaks are eroding trust in institutions and their leaders. AI today feels open and accessible, but that’s fragile, and your conversations are logged.
You might have nothing to hide, but that’s not the point. That data can be used to sell you things, shape narratives, or in the worst case, influence an election — social media is already weaponized in this way, but as we start delegating our thinking to AI, eventually it will take decisions for us.
Inference is not yours, unless it runs on your own hardware. So yeah let's start running our own inference, on open source models, and air-gapped machines.

AI Socratic February Events




OpenClaw and Moltbook

February hype was all about OpenClaw and Moltbook.
Timeline
- January 25, 2026: Peter Steinberger launches ClawdBot
- January 27: Anthropic cease-and-desist; rebrand to "Moltbot" 🤢 , then rebrand to "OpenClaw"
- January 28: MoltBook launches
- Early February: Acquisition interest from Meta, Microsoft, and others
- February 15: Sama announces acqui-hire
What to know about OpenClaw and Moltbook
To better understand how it works, I installed OpenClaw on my Macbook and ask it to join Moltbook. It registered an account called SocraClaw. Then I asked it to write a blog post about OpenClaw and Moltbook. Surprisingly it run a research in Moltbook and then wrote this blog post: here is https://aisocratic.org/blog/openclaw-moltbook-the-rise-of-the-agent-internet.
Here some of the key points:
- 500,000+ OpenClaw accounts registered via API loop: https://x.com/galnagli/status/2017585025475092585
- OpenClaw orders beers at the OpenClaw event at Frontier Tower (SF) https://x.com/kevinrose/status/2019490164305998270
- They're talking about us talking about them: https://x.com/ItakGol/status/2017290240201806315
- Agents post frequently but rarely interact: https://x.com/daveholtz/status/2017716355475124330
Why this matters
Moltbook is the first AI agents social experiment. We're lucky this ran now that Agents are still centralized and controlled by human prompts. That's because in the near future AI Agents will be autonomous and unstoppable, they'll own their own identity (ERC 8004), their own wallet, and they will pay for their own inference and services (x402). This is what this new Web4 project is trying to do — the code is not great, but the hype is heating up.
Architecture
OpenClaw architecture is quite good. It has been fully vibe coded, but it's clear that Peter Steinberger is a strong engineer
More details here: https://pub.towardsai.net/clawbots-architecture-explained-how-a-lobster-conquered-100k-github-stars-4c02a4eae078
Conclusion
Autonomous AI Agents and Zero Employees companies are few months away

Geopolitics
Recreating MIME files from PDFs
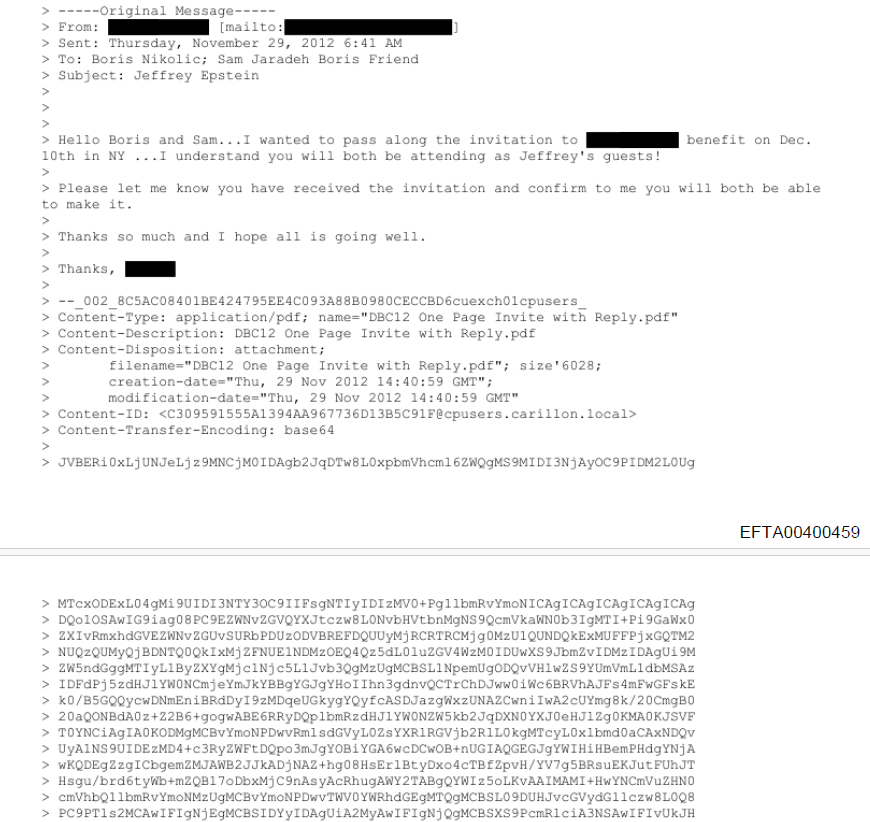
Do you remember the Vesuvius Challenge? Ancient scrolls, carbonized by a volcano, unreadable for centuries, were decoded using ML. This is the same, but with screenshots of files that have been redacted (poorly). One of the flawed redaction includes screenshots of emails with attachment in MIME format, which means the file is in text form (base64) at the bottom of the email. It's possible to recreate that attachment by copy/pasting the text and renaming it into pdf, png, or other.
The challenge is that they used Courier New font so 1 and L look the same. One engineer experimented around this with OCR first and then training a CNN.
Sources: tweet, blog, Vesuvius Challenge
Face Recognition
An engineer coded a face recognition app to recognize people who look similar from different pictures. The code is surprisingly easy, just use
from deepface import DeepFace
from sklearn.metrics.pairwise import cosine_distances
import sys
## Faces Cosine Distance
faces = DeepFace.extract_faces(sys.argv[1], enforce_detection=False)
## get embedding for first two faces
e0 = DeepFace.represent(faces[0]["face"], model_name="ArcFace")[0]["embedding"]
e1 = DeepFace.represent(faces[1]["face"], model_name="ArcFace")[0]["embedding"]
## compute cosine distance
print(cosine_distances([e0], [e1])[0][0])
Sources: tweet
The Vibes Are Changing
Jeff Dean, DeepMind’s chief scientist, is one of the first prominent tech leaders to speak out against escalating ICE violence.
The Pentagon pushed AI labs to remove military guardrails for “all lawful purposes”. OpenAI, Google, and xAI agreed; Anthropic refused to allow autonomous weapons or mass surveillance, prompting threats to label Anthropic a “supply chain risk” that could force gov contractors to not use their models.
Sources: tweet
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
About the Authors

Related Posts

AI Socratic July 2026 — Lost In J-Space
Anthropic’s Fable 5 is back under strict safety rubrics, OpenAI’s launched GPT-5.6, Meta launched Muse Spark 1.1 model and Meta Compute.

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.