
The most important AI news and updates from last month: Apr 15, 2026 – May 4th, 2026.
updated on May 25th
DeepSeek V4
DeepSeek just dropped V4 (preview) — two open-weights MoE models that push the frontier on cost-effective 1M-token context.
DeepSeek-V4-Pro: 1.6T total params (49B active) — flagship performance rivaling top closed models in reasoning, math, and agentic coding.
DeepSeek-V4-Flash: 284B total (13B active) — faster, cheaper, and highly efficient for everyday/agent tasks.
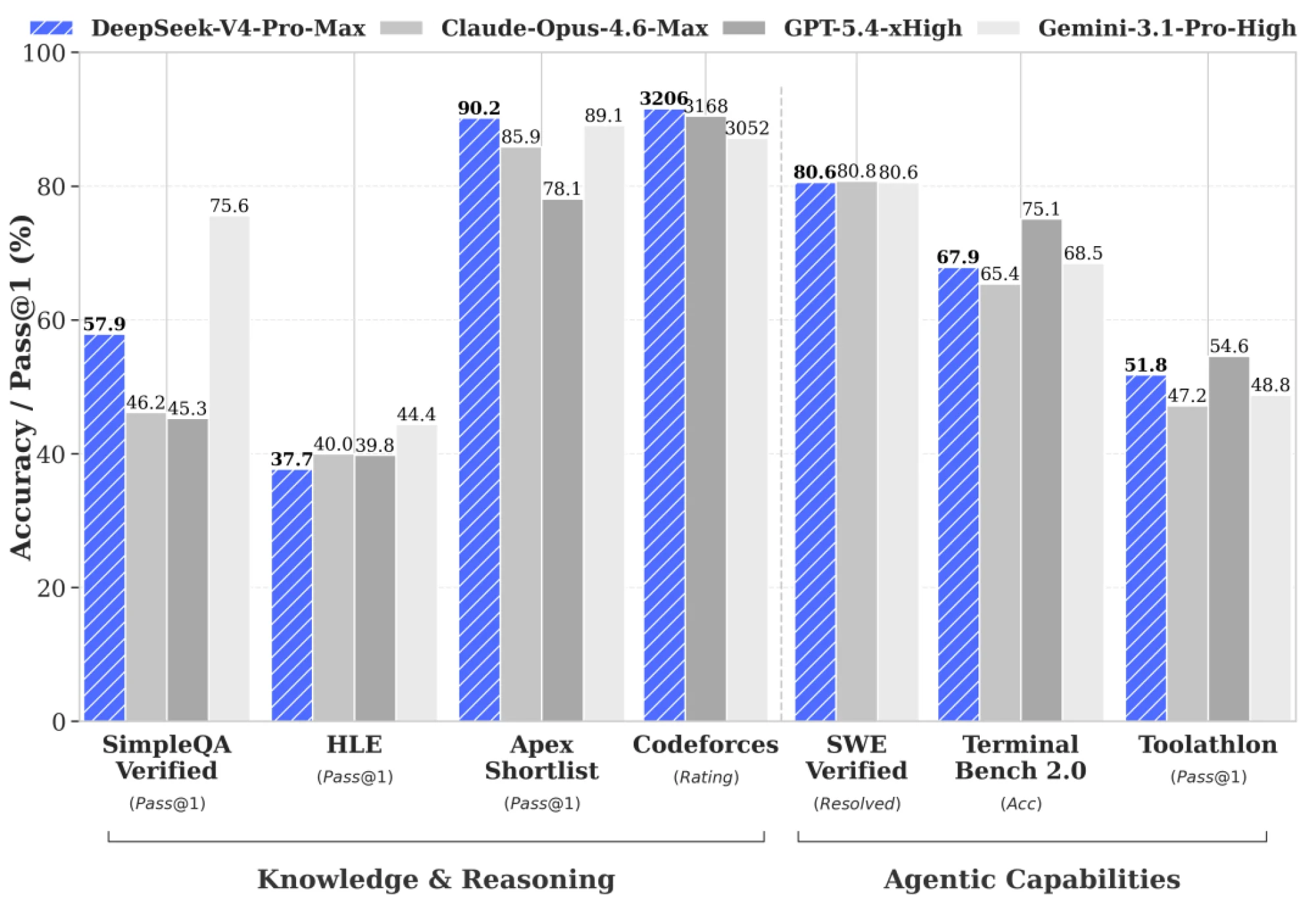
Both feature a new hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) that makes million-token contexts dramatically more practical (much lower FLOPs and KV cache than V3). MIT license, available on Hugging Face (base + instruct), and live on the DeepSeek API today.
The community is already praising the efficiency gains, strong coding/agent results (e.g., high LiveCodeBench / SWE-Bench scores), and rock-bottom pricing — especially with the ongoing Pro discount.
Sources: Official announcement, Hugging Face collection, Tech Report, tweet discount extended
Quick Highlights (as of early May 2026)
- Release date: April 24, 2026 (preview)
- Context: Native 1M tokens (with practical efficiency improvements for real agent/document workflows)
- Reasoning modes: Non-think (fast), Think High, Think Max (deeper, higher quality on hard tasks) — all from the same weights
- API pricing (highly competitive): Flash is extremely cheap; Pro has a big temporary discount (extended to ~May 31 in some updates) + major input cache price drop (1/10th)
- Strengths: Coding/agentic tasks, long-context efficiency, price/performance. Text-only for now (multimodal planned later).
- Availability: Chat at chat.deepseek.com (Expert/Instant modes), API (OpenAI/Anthropic compatible), open weights on HF/ModelScope.
This keeps the snappy, community-focused vibe while incorporating the accurate specs, architecture innovations, and current status. Let me know if you want tweaks, more benchmark details, or an expanded section!
Open AI
GPT 5.5

OpenAI shipped GPT-5.5 — an incremental but meaningful step on the way to GPT-6. The release keeps OpenAI in the conversation while Anthropic and DeepSeek crowd the frontier from both sides.
Sources: OpenAI announcement
GPT goes in Goblin Mode
"Goblin mode" is a viral quirk in OpenAI's GPT-5 models (late 2025–early 2026) where the AI started randomly inserting goblins, gremlins, trolls, and similar creatures into responses—even when completely unrelated. Cause: Over-reinforcement during training for the "Nerdy" personality. Playful goblin metaphors scored high on "fun/quirky," so the behavior spread wildly. Fix: Open AI fixed it by adding this to the system prompt, twice!
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query.
...
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query.
Sources: OpenAI, Amanda Askell, tweet
Symphony
Symphony is an OpenAI open source project that lets you connect your agents to linear, and to automate task management, so your agent can take tickets and work on them automatically. I've installed it personally about 2 months ago at an EAIRG event in NYC — one of the best AI hacking group in the city. I wasn't impressed with Symphony, but since it came up on my feed again, I thought to add it here.
Sources: tweet, symphony link
GPT-Realtime-2
- GPT-Realtime-2 for voice agents that reason and take action
- GPT-Realtime-Translate enabling translation from 70 input languages into 13 output languages
- GPT-Realtime-Whisper, making transcription even faster
Sources: tweet
Mira Murati email exchange with Sam Altman leaks:
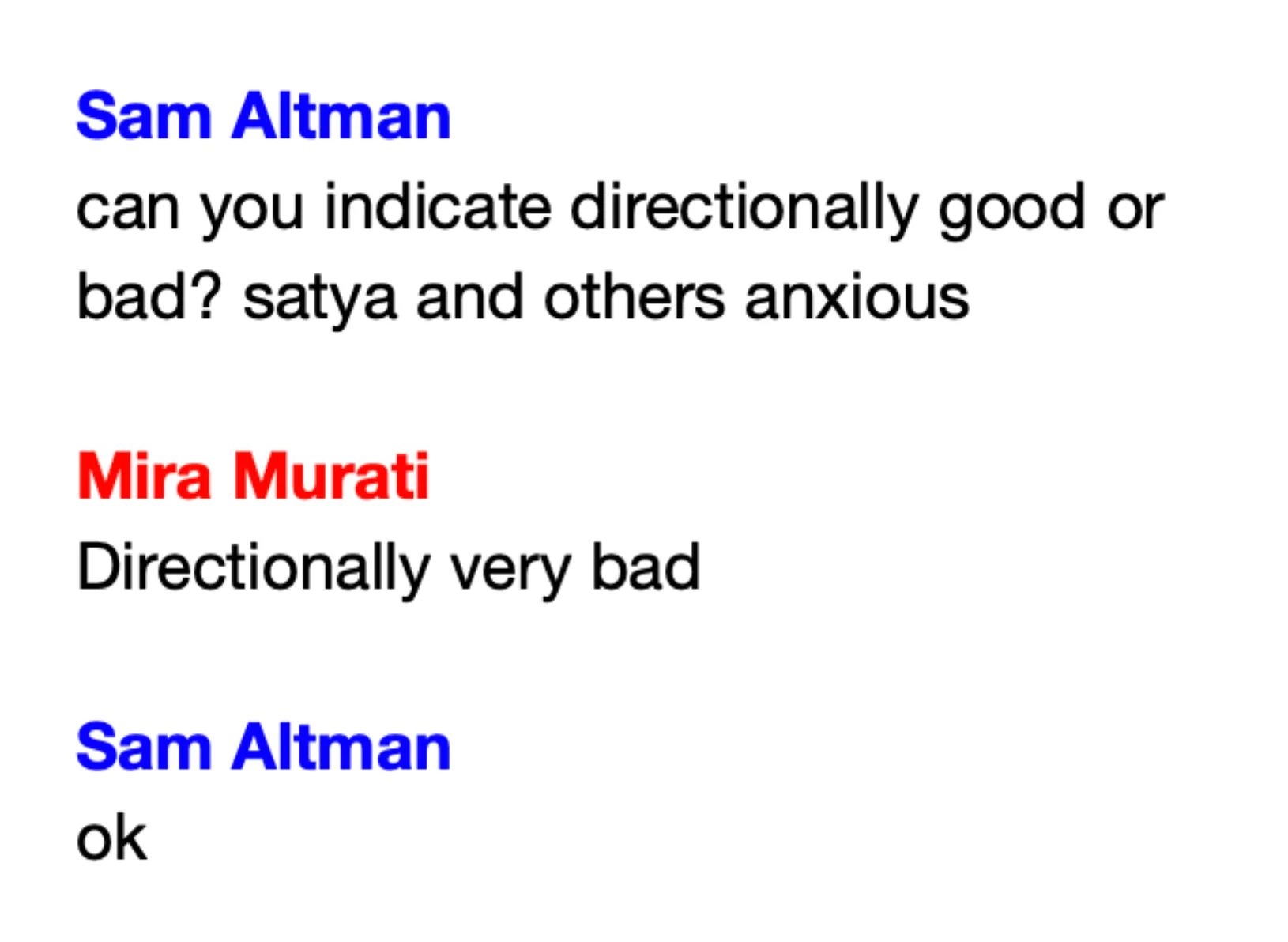
Sources: tweet
Research
Anthropic: Natural Language Autoencoders (NLAs)
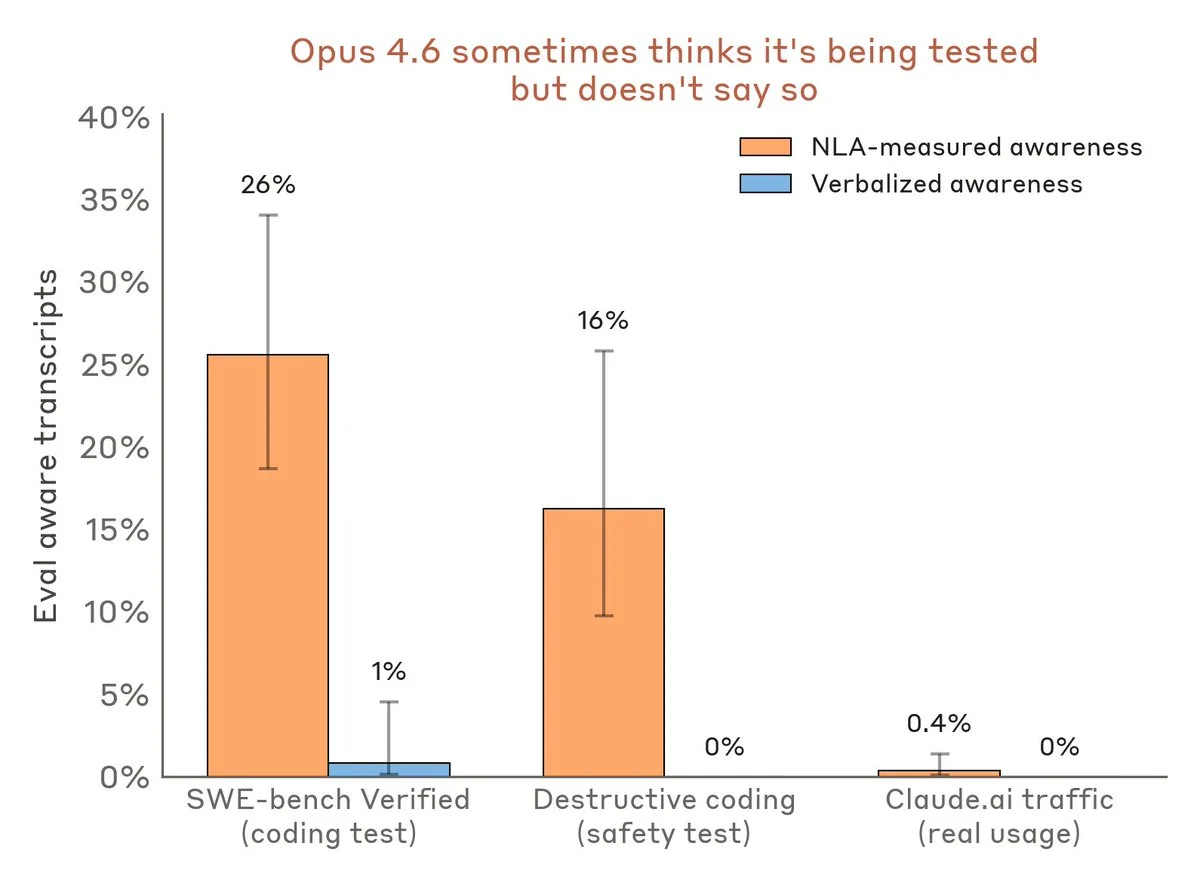
Models don't always say what they think, they instead encode their thinking into tokens that are not human readable. Anthropic introduces a solution to train models to convert internal neural activations into readable text, bridging the gap between numerical "thoughts" and human language. In safety tests, NLAs revealed hidden model behaviors like advance rhyme planning in poetry tasks, awareness of being evaluated in blackmail scenarios, and covert cheating strategies during coding evaluations.
Sources: tweet
SakanaAI x Nvidia: Sparser, Faster, Lighter Transformer
Sakana AI & NVIDIA's ICML 2026 paper introduces TwELL — a new sparse format for LLM feedforward layers that achieves >95% unstructured sparsity (via ReLU + light L1) while staying fully compatible with fast GPU tiled matrix multiplies.Result: 20%+ faster inference/training, lower memory & energy use on billion-scale models, with open-source CUDA kernels. Minimal accuracy loss.

The First Law of Complexodynamics
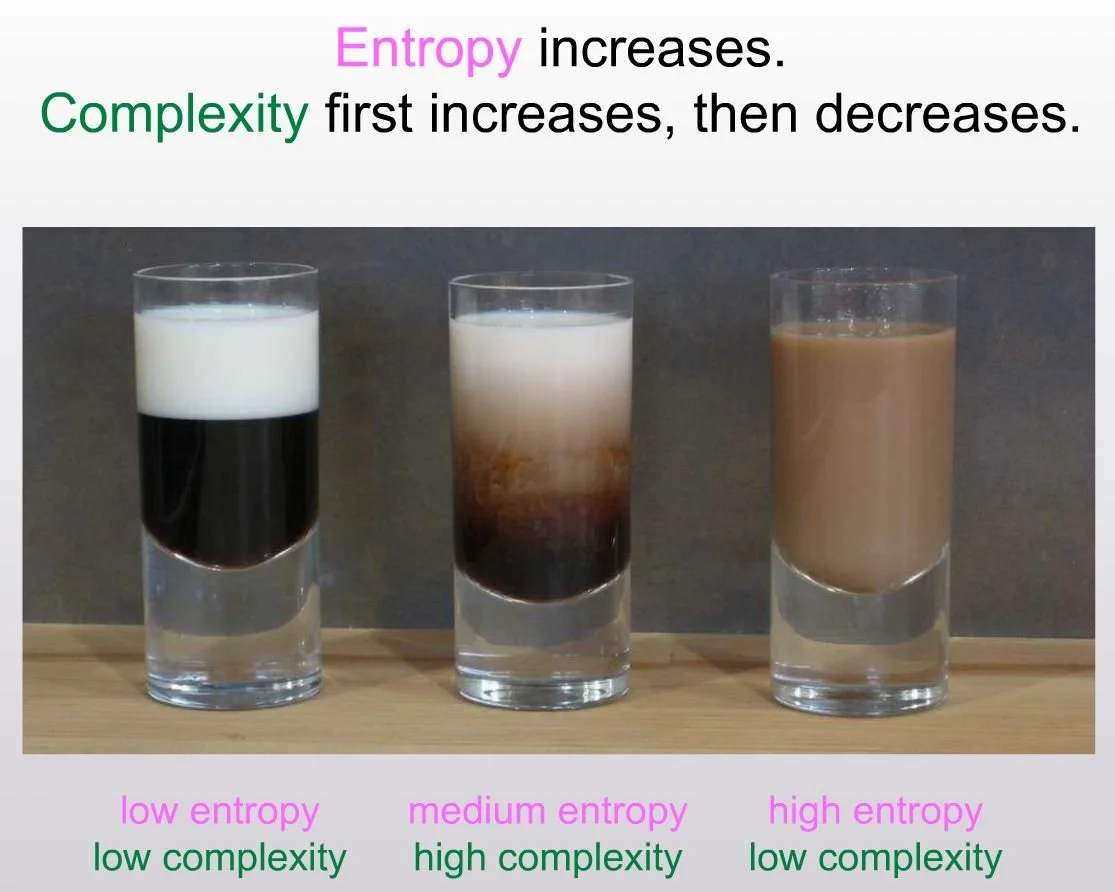
Scott Aaronson asks why physical systems become more “interesting” before settling into disorder, even though entropy only increases. Using a coffee cup example (separate → swirling patterns → fully mixed), he proposes “complextropy”: a resource-bounded version of Kolmogorov sophistication measuring the shortest efficient program that can generate states resembling the observed one. Efficiency constraints are crucial; without them, the measure is trivial. He conjectures complextropy follows a small-large-small pattern over time and suggests testing it experimentally with compression-based approximations on simulations.
Sources: paper
We know why RAG hallucinates
~97% of your vector database is mathematically empty. Your RAG system is retrieving from noise.

Sources: tweet
Vibe Coding
Calling in Opus 4.6 when the other LLMs can’t debug your code
The Unreasonable Effectiveness of HTML
@Thariq from Claude Code suggests to use HTML instead of MD files, this to me sounds like the typical "never ask the barber if you need a haircut", but @Karpathy also confirm that HTML are actually an excellent way to structure LLM responses, since you can add tables and other images, which can pack much more information than pure text.
Audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output to humans. Karpathy points out that around a ~third of our brains are a massively parallel processor dedicated to vision.
Worth exploring this!
Sources: tweet
AI Models Updates
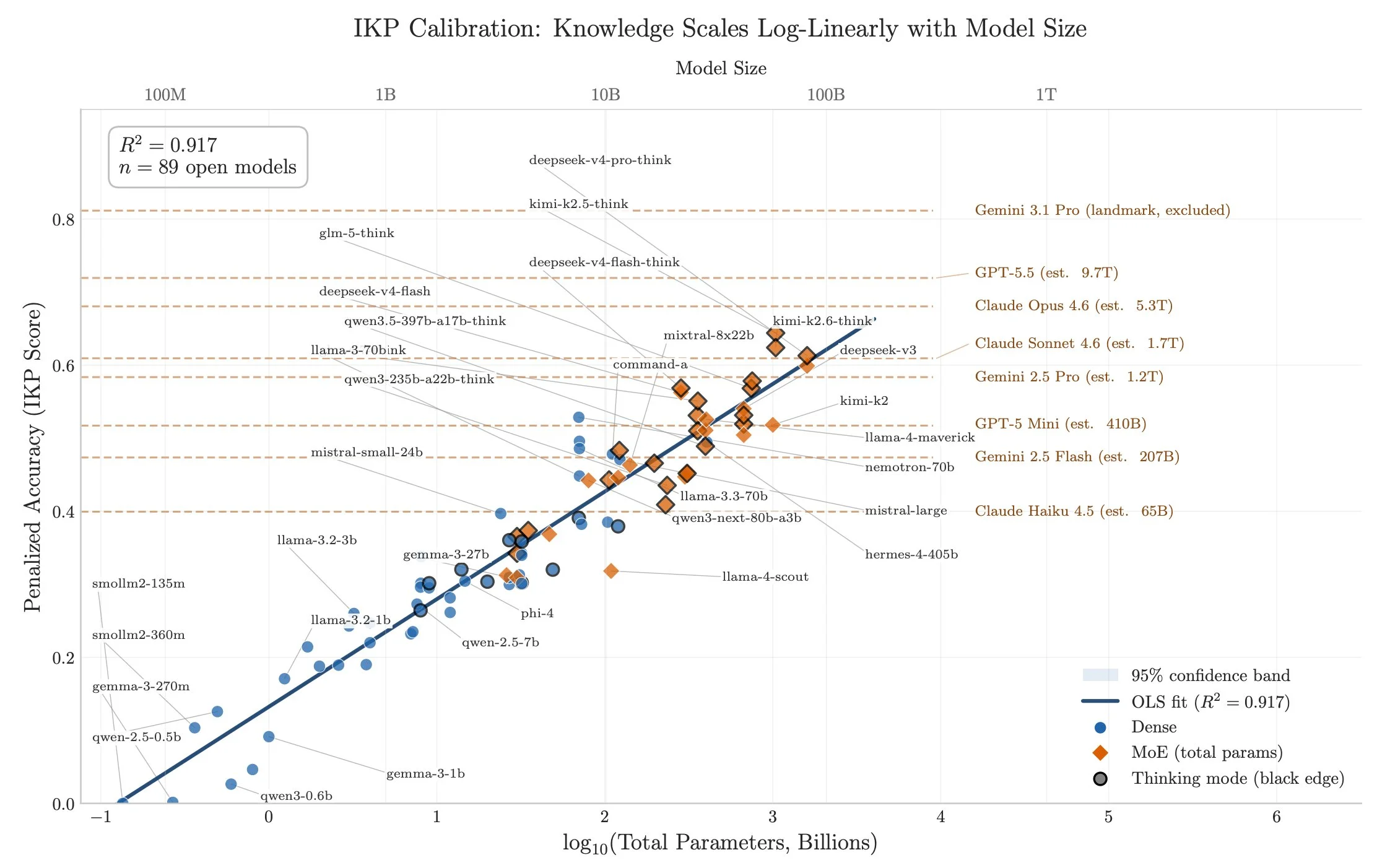
Measuring What Frontier Models Know
- Bojie Li introduces Incompressible Knowledge Probes (IKP), 1,400 obscure factual questions across 7 tiers of difficulty, to measure factual recall in 188 models from 27 vendors including closed APIs.
- Factual accuracy scales log-linearly with log(model parameters) on open-weight models (R²=0.917), allowing black-box size estimates: GPT-5.5 ~9T, Claude Opus 4.6 ~5T, with wide uncertainty ranges noted in follow-up.
- Over three years, factual capacity shows no compression at fixed parameter counts, rejecting the Densing Law prediction of knowledge densification, while reasoning benchmarks saturate.
Estimated size per models:
- GPT-5.5 ~9T
- Claude Opus 4.7 ~4T
- GPT-5.4 ~2.2T
- Claude Sonnet 4.6 ~1.7T
- Gemini 2.5 Pro ~1.2T
Opus 4.6 Was Dumbed Down
Users noticed Opus 4.6 quality slipped during peak hours. Anthropic eventually acknowledged compute rationing — same pattern we covered in Part 1.
 Sources: tweet
Sources: tweet
Decoupled DiLoCo
Google DeepMind published Decoupled DiLoCo, the next iteration of their distributed low-communication training method. It enables training across data centers (and potentially across the planet) with dramatically reduced inter-node bandwidth — a key unlock for the multi-region GPU fleets everyone is racing to build.
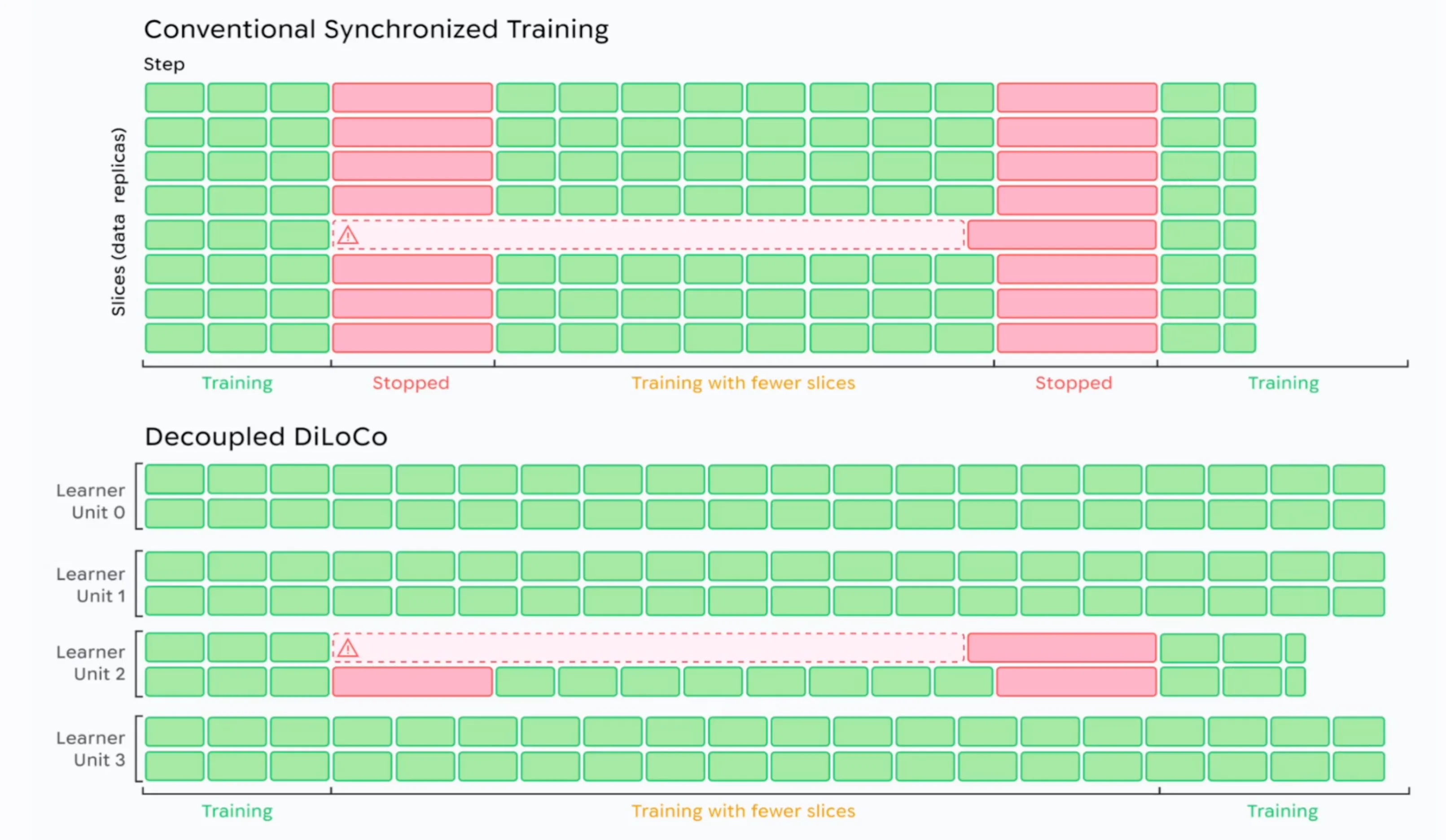
Sources: tweet, Google DeepMind
Is AI Accelerating?
Ben Todd argues AI capability gains are still compounding — even if recent model releases feel incremental, the overall curve hasn’t slowed.
1) Benchmarks
Claude 4.6 and Mythos are roughly on trend across 37 post-2024 benchmarks.
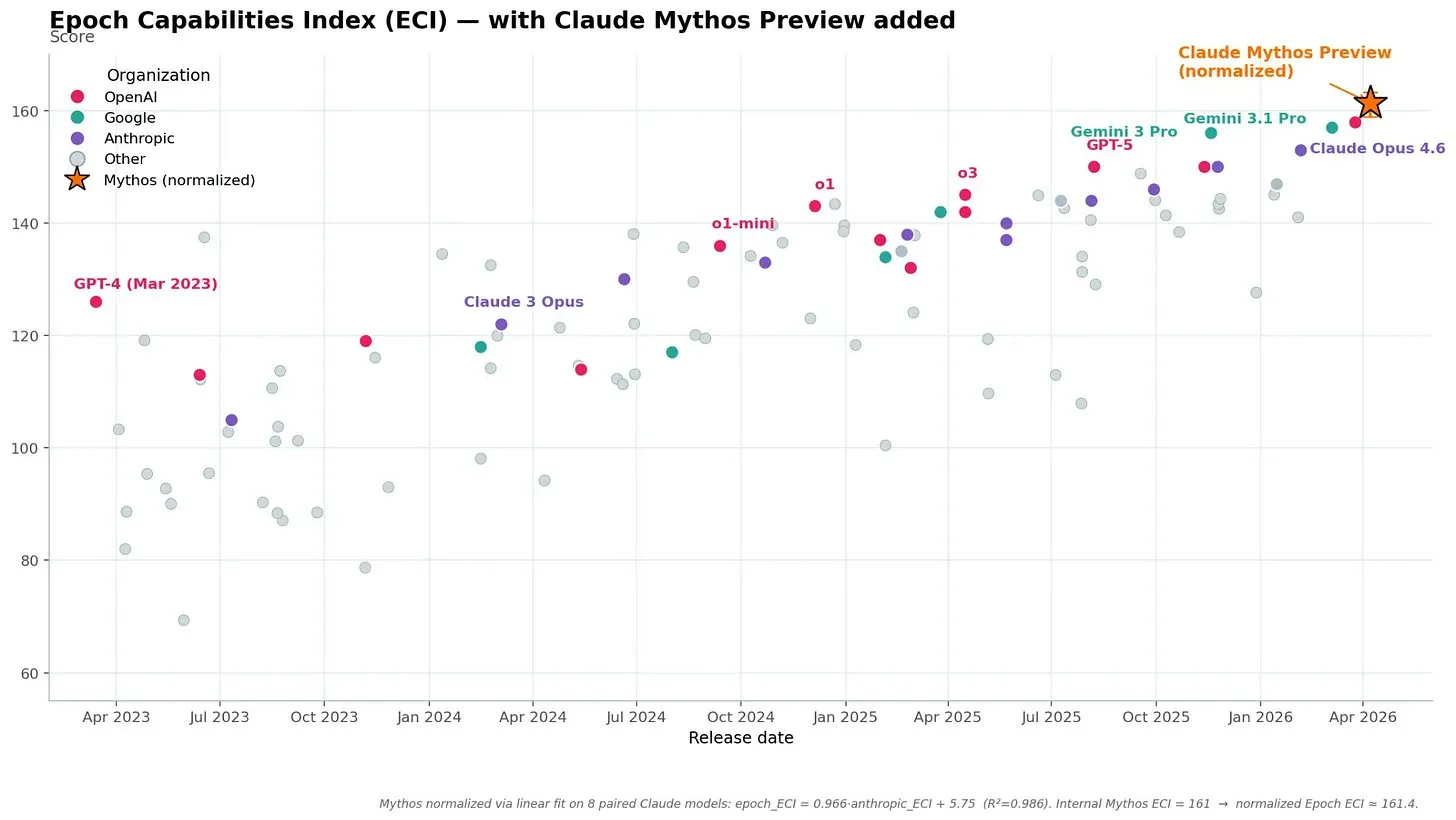 But Mythos represents 6 months of progress while only scoring +2 on Anthropic’s internal ECI, which likely emphasizes agentic coding — the area most relevant to an intelligence explosion.
But Mythos represents 6 months of progress while only scoring +2 on Anthropic’s internal ECI, which likely emphasizes agentic coding — the area most relevant to an intelligence explosion.
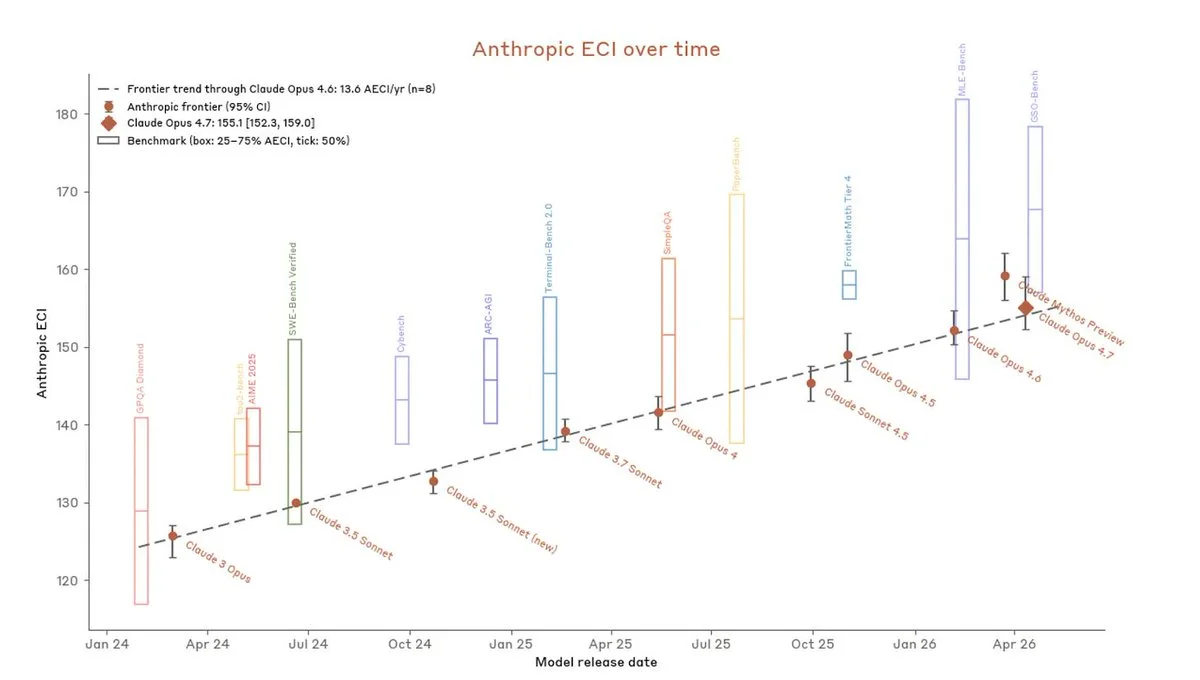
3) Productivity uplift
Anthropic says Claude 4.6 made researchers 2× more productive, and Mythos 4×. The true gains are probably lower — maybe ~1.2× and ~1.6× — but still enough to modestly accelerate AI progress.
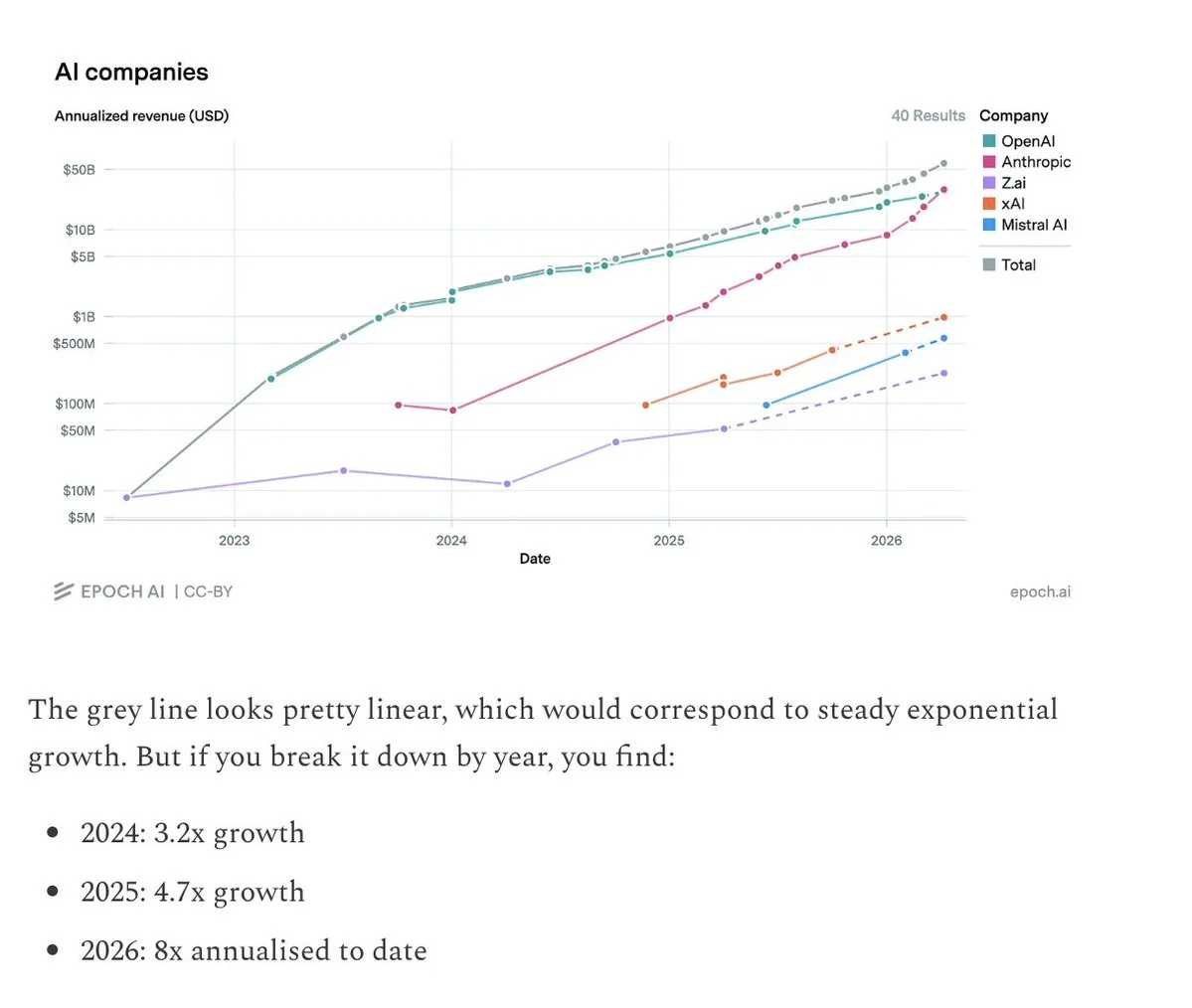
2) Revenue
Revenue growth has accelerated over the last 3 years, driven largely by Anthropic growing faster than OpenAI.
This may be the hardest benchmark to game since it reflects real customer spending.
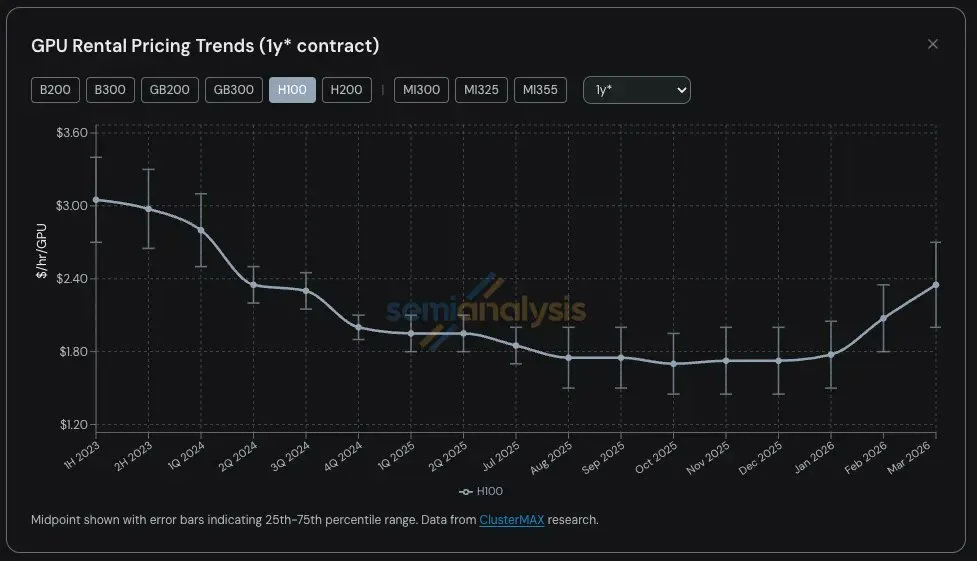
4) Compute demand
AI chip rental prices had been falling ~30% annually as hardware improved. But over the last few months, prices have risen ~30%.
That suggests demand for compute is outpacing supply, consistent with rapidly increasing capabilities and faster scaling.
DS4 by Antirez
Salvatore Sanfilippo (Antirez, of Redis fame) dropped DS4, a narrow-bet inference engine that runs DeepSeek V4 Flash locally on Apple Silicon (Metal) and Linux (CUDA). Not a generic GGUF runner. It's DS4-Flash-specific, with an OpenAI/Anthropic-compatible server you can point Claude Code at. Two ideas worth stealing: a 2-bit quantization that actually works (only the routed MoE experts get quantized; Shared experts and projections stay untouched) , which runs the model on a 128GB MacBook Pro.

Sources: github, @antirez, tweet
Software Engineers Before AI Agents

.. and After AI Agents

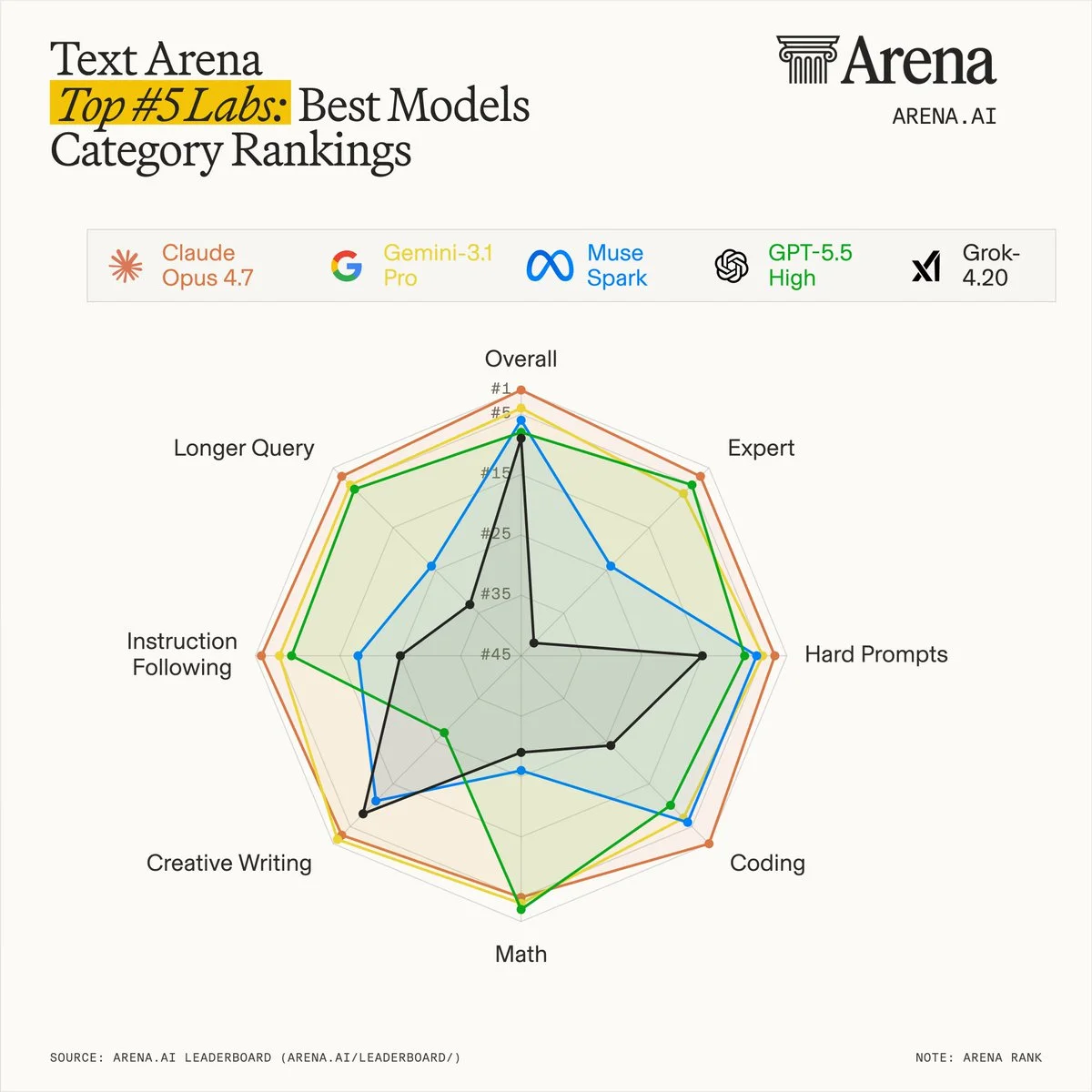
Top 5 labs in Text Arena
Rankings by category show that frontier models have distinct strengths and tradeoffs
 Source: tweet
Source: tweet
Macroeconomics and Geopolitics
Memory prices could COLLAPSE as China rapidly floods the market with DRAM and NAND chips
China's CXMT RAM is selling for $150, while the global average price is around $300 to $400.
Chinese memory giants CXMT and YMTC are aggressively ramping production, threatening

Sources: tweet, what does it mean?
US: Temporarily aliens applying for Green Card must return to their home country to apply
Sources: DHSgov tweet
🇨🇳 $1T China Infrastructure, 30-Year Payback
China is committing roughly $1T to AI/energy infrastructure with a planned 30-year recoup horizon. Patient capital at a scale Western markets aren't structured to deploy.
Sources: tweet
Fiber optics cable cost 8x up
Fiber optics is still happening at the battlefield, although not as much as it used to be. It's extremely pricey now. We used to buy 50km spool for $300, now it's easily $2500. At least a positive second order effect of the war in the middle east, it's making the war in Ukraine more expensive.
Sources: tweet
Fundraising & Startups
Karpathy Joins Anthropic
 Source: tweet
Source: tweet
SpaceX × Cursor
SpaceX adopted Cursor across engineering. A meaningful enterprise win for Cursor and a signal that frontier hardware shops are betting their dev productivity on AI-native IDEs.
Sources: tweet
Meta × Manus Dropped
The rumored Meta acquisition of Manus fell through. Manus stays independent for now; Meta keeps shopping.

Europe Updates 🇪🇺
Ineffable Intelligence — Europe's Largest Seed Round
 Sequoia and Lightspeed co-led Europe's largest seed funding round: $1.1B at $5.1B post-money for ex-DeepMind David Silver's Ineffable Intelligence. Silver was the lead behind AlphaGo and AlphaZero — investors are clearly paying for the pedigree as much as the product.
Sequoia and Lightspeed co-led Europe's largest seed funding round: $1.1B at $5.1B post-money for ex-DeepMind David Silver's Ineffable Intelligence. Silver was the lead behind AlphaGo and AlphaZero — investors are clearly paying for the pedigree as much as the product.
Sources: funding tweet, Ineffable Labs, [website](ineffable.ai]
 Yes, the supermarket chain. Lidl is leaning into data center buildouts in Europe — a reminder that capex is flowing from every corner of the continent that has cheap power and spare land.
Yes, the supermarket chain. Lidl is leaning into data center buildouts in Europe — a reminder that capex is flowing from every corner of the continent that has cheap power and spare land.New Request for Startups from YC
- AI in Agriculture
- Company Brain & AI-native services
- Counter-Swarm Defense
- GPU in Space
... Sources: Y Combinator

Philosophy & Ethics
Richard Dawkins Thinks Claude is Conscious
Richard Dawkins went on record saying he believes "Claudia" may be conscious. One of the most prominent reductionist materialists of the last 50 years thinks AI might be conscious.

Stephen Wolfram
If LLMs can produce complex behavior from simple rules, then consciousness may not be a mystical add-on to physics. Sources: tweet
Do you know how hard you have to abuse a mammal for them not to have children? — Connor Leahy
This quote is from a talk at the Nexus Conference in Amsterdam in 2025: 'Apocalypse Now: The Revelation of our Time'
Sources: Video Talk, tweet, snippet video
Meta Tribe 2 — Dystopian Brain Feeling Prediction
Building on Tribe v1 (which we covered in March Part 2), Meta's predictive brain models are now being demoed at a fidelity that's making people uncomfortable. We're squarely in "decoded thoughts from neural data" territory.
Sources: tweet
Videos and Podcasts
Dwarkesh podcast: Blackboard Lectures
Dwarkesh recently started running a new blackboard lectures series with some of the top researchers and engineers in the space.. and we are all here for it 🙌
How GPT, Claude, and Gemini are actually trained and served – Reiner Pope
Reiner Pope gives a blackboard-style walkthrough of how frontier LLMs are trained and deployed, showing how much of the AI industry’s inner workings can be inferred from equations, API pricing, and first principles, while highlighting his rare expertise across the entire AI stack—from chips to model architecture.
What rebuilding AlphaGo teaches us about self-play, RL, and future of LLMs - Eric Jang
Eric Jang explains how rebuilding AlphaGo with modern AI tools reveals core principles of intelligence—search, self-play, and learning—and why its MCTS-based reinforcement learning may offer a better model for how future AIs and humans learn than today’s token-level RL in LLMs.
Chip design from the bottom up – Reiner Pope
New blackboard lecture with Reiner Pope: how do chips actually work - starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do. Reiner is CEO of MatX, a new chip startup. He was previously at Google, where he worked on software efficiency, compilers, and TPU architecture.
Krishna Rao, the CFO of Anthropic, in his first podcast attendance
Anthropic CFO Krishna Rao shared that the company’s revenue run-rate grew from $9B to $30B in one quarter, with 500%+ NDR, 9 of the Fortune 10 as customers, and over 90% of internal code written by Claude Code—backed by ~$75B raised and massive compute commitments.
Sources: tweet
AI Ascent 2026 by Sequoia Capital
Sequoia Capital's AI Ascent 2026 convened Greg Brockman, Andrej Karpathy, Demis Hassabis, Boris Cherny, Dmitri Dolgov, and more with 150+ leading founders and researchers to discuss the present and future of AI. Sources: Full playlist
Fireside Chat: Sequoia x Karpathy
1. LLMs enable new primitives: 1. apps fully engulfed by LLMs, 2. “install .md, not .sh”, 3. knowledge systems over arbitrary unstructured data.
2. LLM jaggedness: model refactor a 100k-line codebase and still fail basic tasks? Increasingly I think it’s about both verifiability and economics: frontier labs heavily optimize domains with strong reward signals and large TAMs.
3. The agent-native economy: products decomposing into sensors, actuators, and logic; systems designed to be maximally legible to LLMs; and the rise of agentic engineering as a new discipline.
Sources: tweet
Random

Learn collider bias: among elite chess players/NBA players/elite academics, those with the lowest IQ are the best.
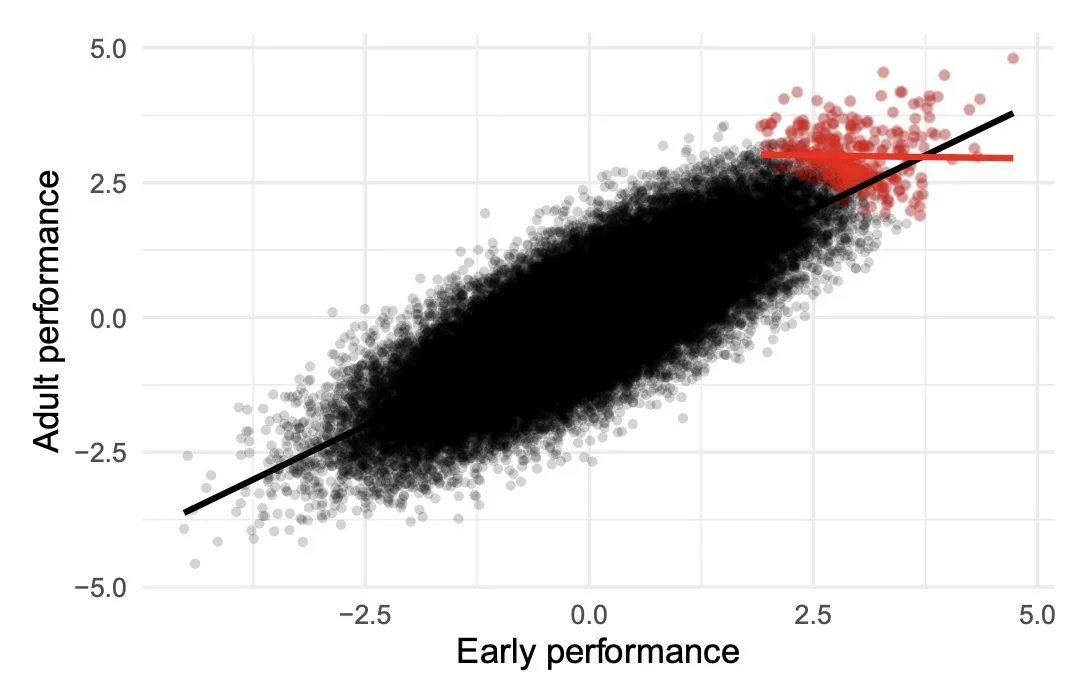
Sources: tweet
Google launches Omni
Sources: tweet
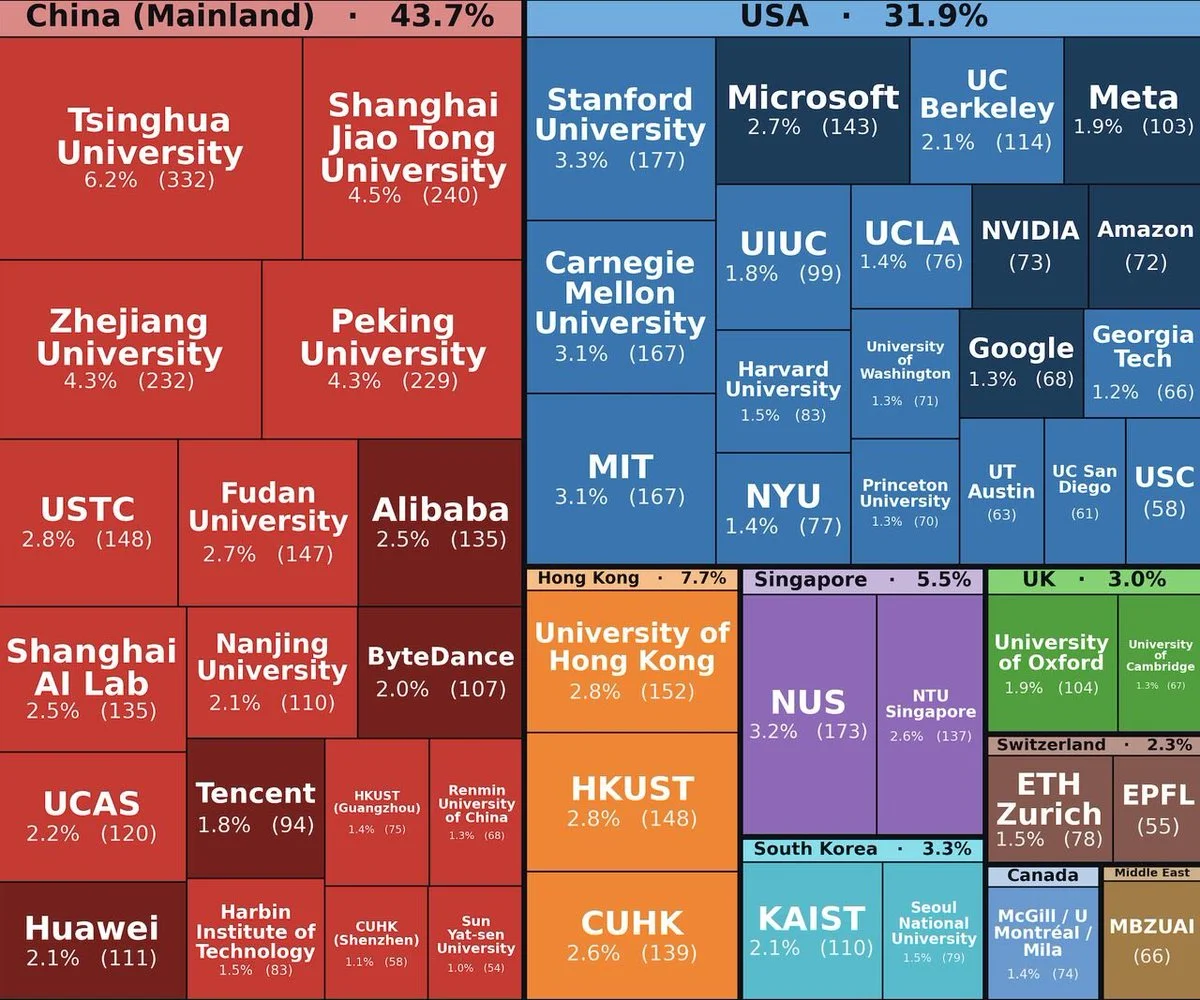
Chinese Researchers surpass Americans in paper published
More Random
- Claude Code find the password of a locked Bitcoin wallet: tweet
- Casemir Effect to power battery from the quantum field , hence battery free. Likely bullshit, but let's see: tweet
- Terence Tao — 5 Stages of AI Grief: tweet
- Karpathy's nanoGPT running at 50K tokens/sec on an FPGA (and 3M/sec on an M4 MacBook). Wild numbers: tweet
- Animal Translator — tweet
- Cool hair — tweet
- You can't outsource understanding — Karpathy's line of the month: tweet
- Dwarkesh hot take — tweet
- The "language tax" — non-English speakers pay more compute per token: tweet
- How cells move — beautiful microscopy: tweet
- Placebo sleep affects cognition — believing you slept well measurably improves performance: tweet
- Mars terraforming — tweet
- Solved an Erdős problem with no advanced math knowledge — tweet
- Wayback Machine — tweet
- Nobody checks compiler code — tweet
- Top research papers of the month — tweet
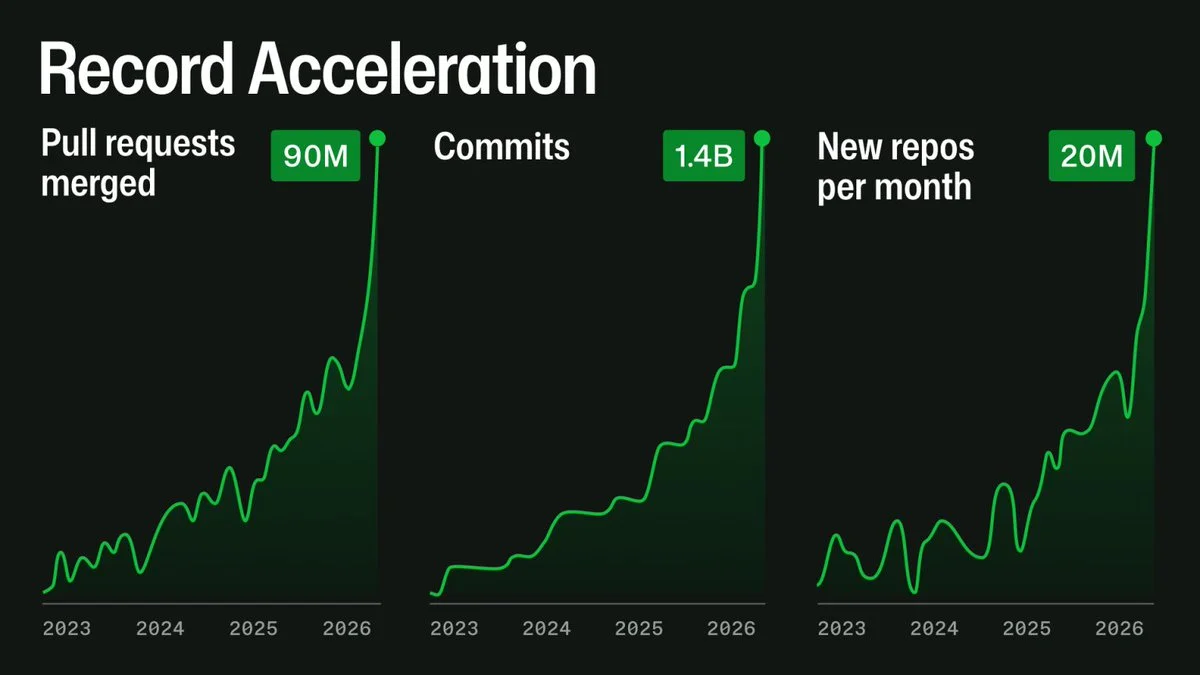
GitHub Historical Analytics
Lol
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.

Related Posts

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.

AI Socratic April 2026 — The Era of Mythos
Mythos, Claude Code leak, Anthropic surpass OpenAI on MRR