
Nvidia GTC — The Year of Physical AI
This year, the focus was on physical AI, and in my experience something on the line of: 30% Data Centers, 30% GPUs and Hardware, 30% Robotics, 10% Software.
Highlights from the conference
- $1 Trillion AI Infrastructure Boom, Jensen projects $1 trillion in cumulative orders for Blackwell + Vera Rubin systems through 2027 (2x 2026 estimates).
- Vera Rubin Platform Unveiled, next-gen full-stack AI platform features seven new chips, five rack-scale systems, a new Vera CPU for Agentic AI, and BlueField-4 storage. It promises major efficiency gains and starts shipping later in 2026, with even denser designs (like Kyber) coming in 2027.
- NemoClaw, everyone and their grandma are launching a personal AI agent, so now is NVIDIA turn.
- Inference Inflection & Token Economics, a massive leap in token generation performance (up to 350x in some tiers) position inference as the new economic engine of AI, with "tokens" becoming the core commodity.
- Physical AI, Gaming & Ambitious Vision, advances in robotics (e.g., Disney's Olaf), DLSS 5 for gaming, and bold plans for space-based AI data centers (Vera Rubin Space-1). Emphasis on full AI factories, open models (Nemotron ecosystem), and simulating infrastructure with Omniverse.

🙌 Andrej Karpathy’s lab has received the first DGX Station GB300 -- a Dell Pro Max with GB300.
As you may have notice Karpathy has been shipping no stop lately, Nanochat, AutoResearch, AgentHub (github for agents). So Jensen gifted him a new machine.
Sources: tweet

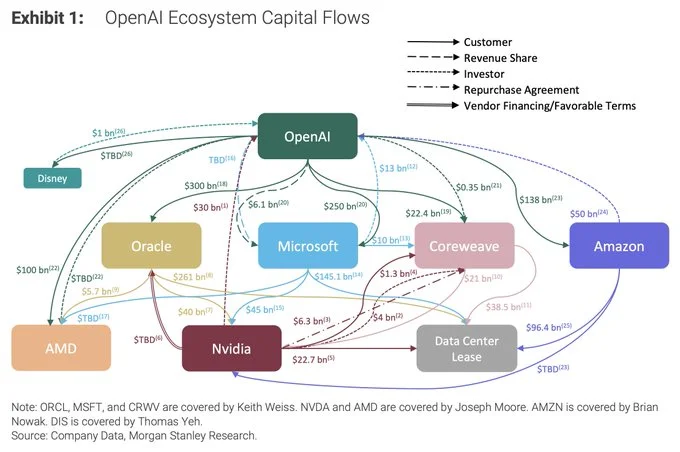
Are we in a bubble?
This is a hell of a graphic from Morgan Stanley
Anthropic is Accelerating
Claude Code New Features 🚀
Anthropic just shipped a tons of new features for Claude Code, it's clear is becoming an OpenClaw competitor:
- Auto mode, many of you may have use
claude --dangerously-skip-permissions, I do!--auto-modereplaces that by having subagents checking before confirming changes. - Computer Use, allows Claude to control your desktop apps and browser.
- Scheduled Cloud Tasks, automate recurring workflows in the background.
- Channels, enables controlling Claude Code sessions via Telegram and Discord.
- 'Auto-dream', memory consolidation feature that runs a subagent to compact the context. Though with Opus 4.6 1M Context Window your coding agent barely ever needs to
/compactthe context.
Rate Limits Reduced 😢

"To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before."
Sources: tweet
Dario Wins The Court Case Against DoD
A federal judge ruled that the Pentagon designated Anthropic as a supply chain risk as retaliation for the company publicly criticizing the Pentagon's position, calling it classic illegal First Amendment retaliation. This is a significant legal precedent for AI companies' right to publicly engage in policy debates.
Sources: tweet.

New Models Leaked: Mythos and Capybara.
Anthropic accidentally exposed internal assets due to a CMS misconfiguration, revealing development of Claude Mythos and Capybara models. Cybersecurity stock crashes right after.

AI Research
Google Introduces TurboQuant: 6x KV-Cache Compression with Zero Accuracy Loss
Google releases TurboQuant, a compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup with zero accuracy loss. The technique combines online vector quantization ideas from PolarQuant and earlier work. Community members have already implemented it for vLLM, fitting 4M+ KV-cache tokens on small devices, calling it the biggest open inference breakthrough of 2026.
Sources: google blog, tweet, Simple Explainer
LLM Architecture Gallery

Meta FAIR Releases TRIBE v2: Foundation Model That Predicts Human Brain Responses
Meta FAIR introduces TRIBE v2 (Trimodal Brain Encoder), a foundation model trained on 500+ hours of fMRI recordings from 700+ people to predict how the human brain responds to sights and sounds. The paper suggests a paradigm shift in neuroscience toward unified predictive foundation models of brain and cognitive functions, achieving 70x higher resolution than previous approaches.

Yann LeCun's Team Releases LeWorldModel: Stable End-to-End JEPA from Pixels
LeCun's team releases LeWorldModel, solving a key bottleneck of Joint-Embedding Predictive Architectures (JEPA) by making them trainable end-to-end from pixels. This advances the world model paradigm that many see as a critical shift beyond autoregressive language models.

Sources: tweet
Kimi: Attention Residuals
A more efficient way to reuse past information across layers without slowing models down.

Sources: tweet
More Interesting researches
-
TinyLoRA: Fine-Tuning 8B Parameter Models by Tweaking Just 13 Parameters, Researchers from Meta, Cornell, and CMU introduce TinyLoRA, scaling LoRA down to as few as 1 parameter. They turned an 8B parameter model into a math and reasoning powerhouse by fine-tuning just 13 parameters (26 bytes), demonstrating extreme parameter efficiency for model adaptation.
-
Exclusive Self-Attention (XSA): Two-Line Change Improving Transformers Already Adopted in Practice, Exclusive Self-Attention (XSA) proposes a tiny two-line code change that stops attention from attending to itself, forcing focus on the rest of the sequence. It has already become a standard component in leading solutions for OpenAI's parameter golf challenge, demonstrating rapid real-world adoption.
-
Anthropic Economic Index: How Claude Usage Evolves with Experience, Anthropic's Economic Index reveals that longer-term Claude users iterate more carefully, are less likely to hand over full autonomy, attempt higher-value tasks, and receive more successful responses. This provides empirical insight into how human-AI collaboration patterns mature over time.
-
GradMem: Writing Context into LLM Memory via Test-Time Gradient Descent, GradMem introduces writing context into memory using test-time gradient descent rather than forward-pass encoding. By optimizing memory tokens with a reconstruction loss, a frozen model can compress long contexts into small memory without the lossy limitations of existing approaches.
-
100M Token Context Without Collapse: <9% Degradation on 2×A800 GPUs, New research achieves 100M token context windows with less than 9% degradation from 16K, beating RAG + rerank + SOTA pipelines while running on just 2×A800 GPUs. This could fundamentally change how long-context applications are built.
-
LLM Internals: By Layer 10, Models Don't Know What Language They're Reading, A new blog post reveals that when feeding the same sentence in English and Chinese to an LLM, by layer 10 the model's internal representations become language-agnostic — it's "just thinking." This provides fascinating insight into how LLMs develop universal conceptual representations.
-
LLM Fused with Mini Computer: Switching Between Text and Machine Code in Single GPU, A developer demonstrates an LLM brain fused with a mini computer that can switch between generating text and generating/executing machine code, all running in a single GPU and torch graph. This represents a step toward unified compute-and-language models.
-
Columbia University Exposes Flaws in Private AI Inference: Prior Methods Used 280GB per Query, Columbia University researchers prove that the entire private AI inference industry built the wrong approach, with prior methods requiring 280GB per query and 60-second latency for full transformer encryption. Their work points to fundamentally more efficient architectures for privacy-preserving inference.

A system of the agents by the agents for the agents. But the agents are ret...
More Important Updates

LiteLLM PyPI Supply Chain Attack Exfiltrates Credentials
LiteLLM's PyPI release 1.82.8 was compromised in a major supply chain attack. A simple pip install litellm could exfiltrate SSH keys, AWS/GCP/Azure credentials, Kubernetes configs, API keys, crypto wallets, and more. The package was audited by Delve, a firm criticized for rubber-stamping security audits, highlighting systemic risks in the AI tooling supply chain.
Sources: tweet
ARC-AGI-3 Announced: Humans scores 100%, AI < 1%
This is so far the only unsaturated agentic intelligence benchmark. Unlike benchmarks that test what models already know, ARC-AGI-3 tests how they learn and acquire new skills, providing a formal measure of the gap between human and AI skill acquisition efficiency.
Sources: tweet
Team meeting in 2026

More Updates Worth a Read
GradMem
Memory Sparce Attention
Run WASM in an LLM
Apple Opening Up Siri To Other
Quantization Explained
By layer 10 model don't know what language it's reading anymore.
Gemini Embedding 2

Gemini Embedding 2 is our first natively multimodal embedding model that maps text, images, video, audio and documents into a single embedding space, enabling multimodal retrieval and classification across different types of media — and it’s available now in public preview. Sources: tweet
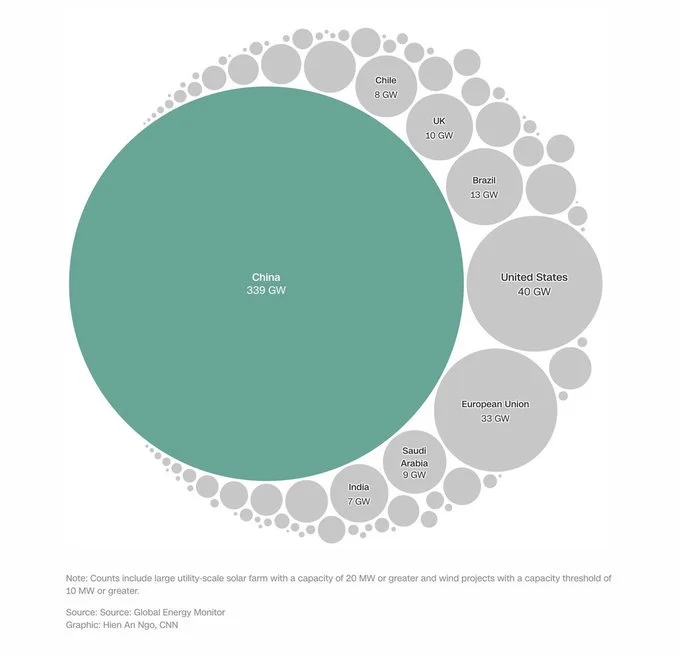
The State of AI Safety in 4 Fake Graphs
China currently has 339 gigawatts of wind and solar capacity under construction
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.

Related Posts

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.

AI Socratic May 2026 — The Selfish Gen AI
DeepSeek v4, GPT 5.5, Trump x Xi meeting, Richard Dawkins, Estimating model sizes