
The most important AI news and updates from last month: Dec 15, 2025 - Jan 15 2026.
✨ Updated on Jan 20.
AI Socratic Events
Madrid now has a new AI Socratic chapter! Congrats to Jorge Ordovás and Iago Suárez, PhD for taking the lead 🚀. We all can't wait to visit the next event.




Models Leaderboard
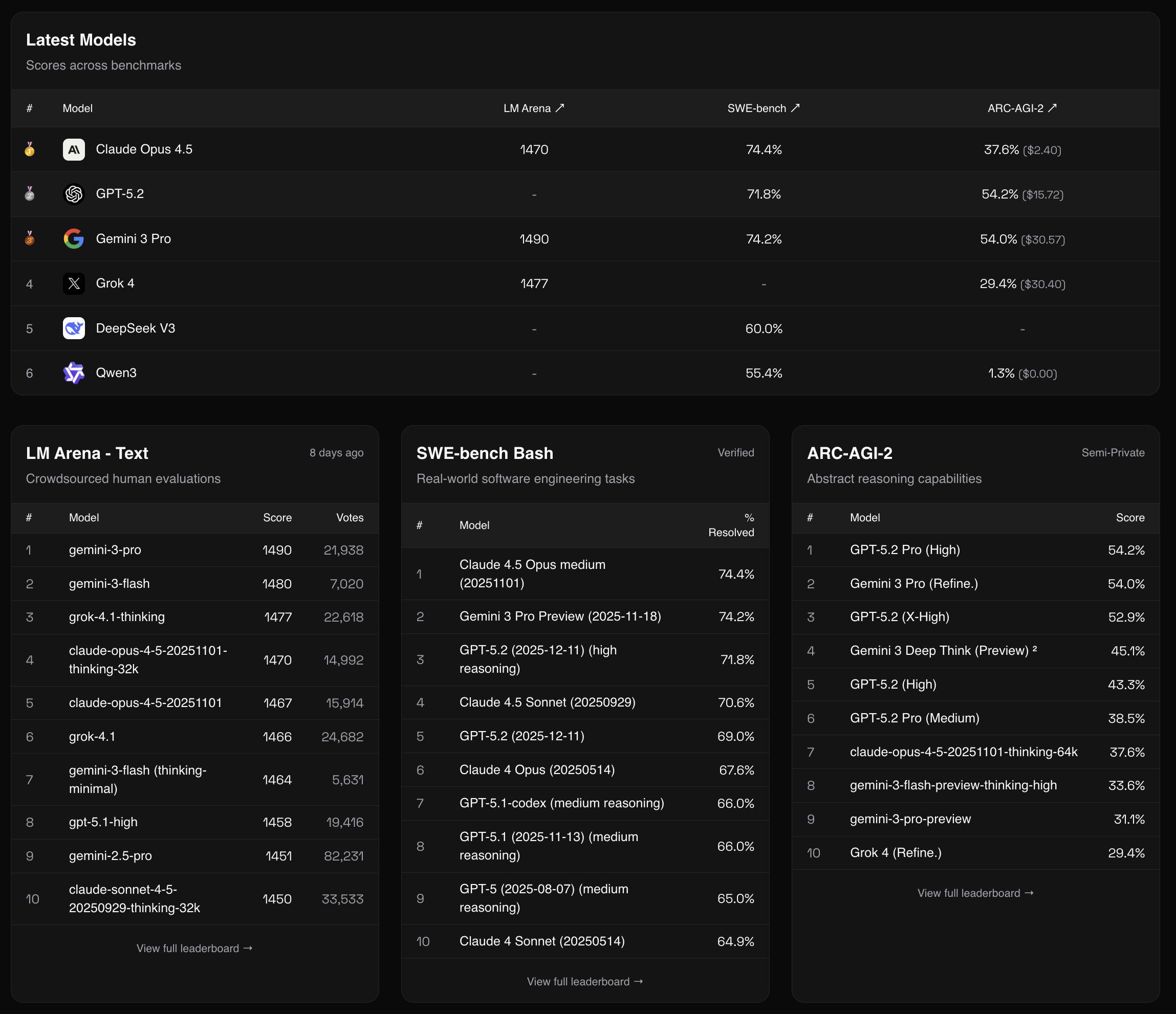
Link: aisocratic.org/leaderboard
We're In The "Vibe" Code Age
I went personally went from 80% of my code being AI via copy/paste to now being 100% via Claude Code. Coding has officially changed for good!

If you recall Dario Amodei mentioned AI covering 90% of coding by end of 2026, turns out we reached 100%. Claude Code was released in May 2025, as a side project, with last month Anthropic released Opus 4.5, it's now arguably the most productive software ever made. OpenAI AGI definition is about an AI that "outperform humans in most economically valuable work", are we there already?
80% of Americans have no idea what Anthropic is (stats from Aug 2025)

Engineers prefer Claude over Cursor because of its simplicity. So Is Claude code going to replace Cursor?

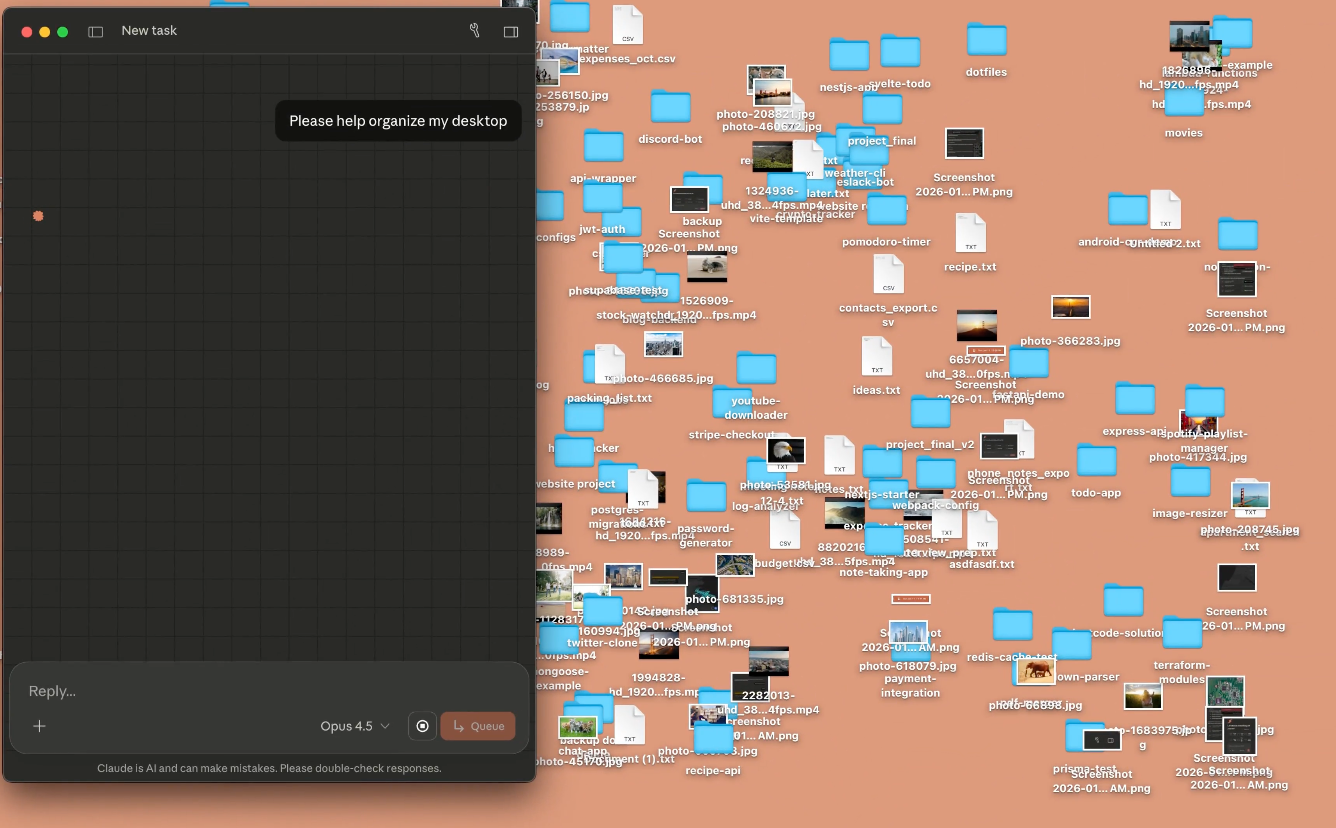
Claude Cowork lets you complete non-technical tasks much like how developers use Claude Code. Pretty much is Claude connected to your file system.
Chrome Extension
Claude just added a Chrome extension and I argue is the most productive tools ever. Not only your CLI gets eyes, it also can automate workflows that don't have an API.
Ralph Wiggum: Infinite Loop
There's now have an official plugin marketplace. One plugin got extra attention ralph-wiggum, which pretty much is an infinite loop over a task until done:
while :; do cat PROMPT.md | claude ; done

Second Order Effects — Software Companies Are Cooked
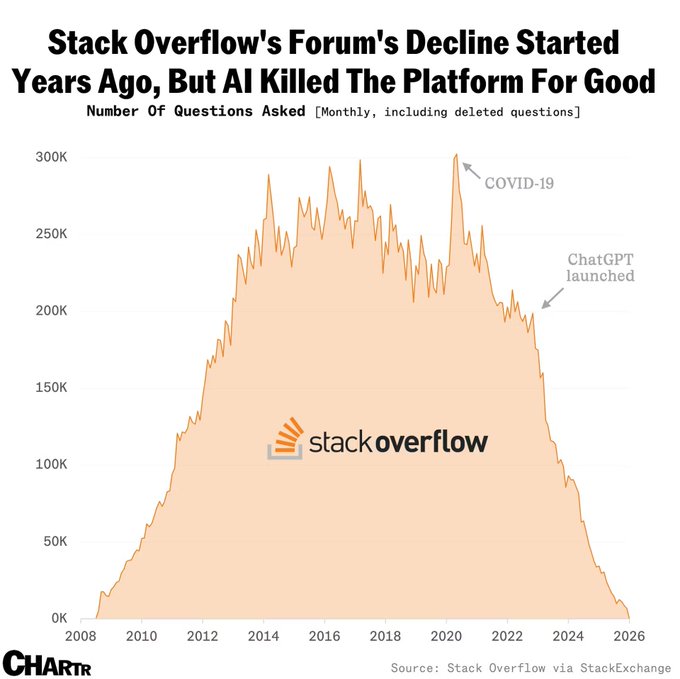
Stack Overflow has seen the number of monthly questions on its platform collapse from 300k to ~0 since launch of ChatGPT.
Tailwind just cut 75% of their team (3/4 engineers) "because of the brutal impact AI has had on our business".
... And First Order Effects — SaaS Companies Are Cooked
...
More interesting updates around Claude Code
- Claude Agent SDK tutorial by Nader Dabit, one of our favorite engineers teachers https://x.com/dabit3/status/2009131298250428923.
- iMCP, macOS app for connecting your digital life to AI via MCP, https://github.com/mattt/iMCP.
- Jonathan Ross is bullish on new AI jobs: https://x.com/realBigBrainAI/status/2012887773150343484.
- How to automate your life with claude code (for non-technical people) https://x.com/damianplayer/status/2012611857392009242.
- Claude Research mode is goated! https://x.com/yoheinakajima/status/2012329179019448507.
- How the creator of claude code actually writes software https://x.com/yoheinakajima/status/2012329179019448507?s=20
- Anthropic has an 80% talent retention rate! https://x.com/Yuchenj_UW/status/2012027217539449143
- Warcraft 2 / Starcraft control panel https://x.com/idosal1/status/2011124558976434469.
- Productivity tip for large task: let Claude interview you using AskUserQuestionTool, then execute the finalized spec in a new session https://x.com/trq212/status/2005315275026260309.
Cursor + GPT 5-2 built a browser (3M lines of code)
Concurrent agents ran uninterrupted for one week. Each agent had a role: planner, worker, judge. According Cursor blog post GPT 5.2 is better at long-running tasks than Opus 4.5. Adding more management hurts performance, lol. Turns out, scaling agents looks a lot like scaling companies https://x.com/Yuchenj_UW/status/2011863636042469866.
Deep Fakes Will Change Social Media
Forget everything you knew about video making. This type of content will become increasingly common in 2026. The difference is who understands the process and comes out in front. This is the kind of skill that will separate those who only watch AI... from those who use AI to create something that attracts attention How to render this videos: https://www.instagram.com/p/DTaNGPkEYBd. [/col]

Research & Papers
DeepSeek 🐋 > mHC: Manifold-Constrained Hyper-Connections
This is a new banger paper from DeepSeek!
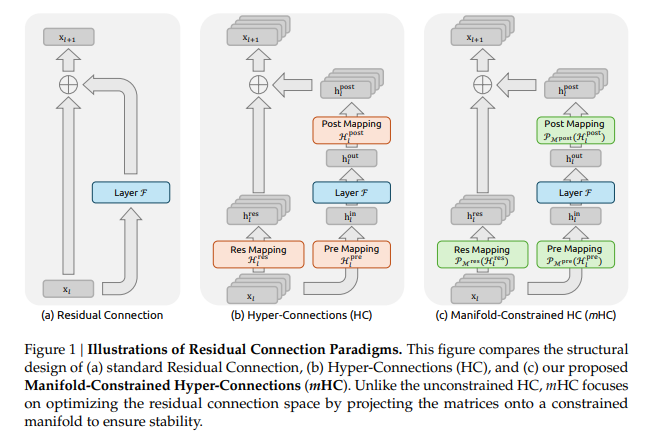
Traditional residual connections (e.g., in ResNets and Transformers) add the layer output to the input, preserving an "identity mapping" that enables stable training in very deep networks. Hyper-Connections (HC), a more recent idea, expand this by widening the residual stream (multiple parallel streams instead of one) and using learned mixing matrices for richer information flow and better expressivity. However, unconstrained HC breaks the identity property, leading to severe training instability (exploding/vanishing gradients) and high memory overhead, limiting scalability.Core Innovation: mHCmHC fixes HC by projecting the mixing matrices onto a specific mathematical manifold — the Birkhoff polytope (doubly stochastic matrices, where rows/columns sum to 1). This is achieved efficiently using the Sinkhorn-Knopp algorithm (an iterative normalization from 1967, ~20 iterations suffice).Key benefits:
- Restores bounded signal propagation (gain stays ~1-1.6 across layers, vs. exploding to 3000+ in plain HC).
- Enables stable widening of the residual stream (e.g., 4-8x wider) for better performance.
- Promotes controlled information mixing across depths, improving representation learning.
Efficiency OptimizationsDeepSeek added heavy infrastructure tweaks (kernel fusion, recomputation, communication overlapping) to keep overhead low (~6-7% extra training time).ResultsExperiments on models up to 27B parameters show:
- Better downstream performance (e.g., on reasoning benchmarks like GSM8K) than standard residuals or unstable HC.
- Superior scalability, with hints from "in-house large-scale experiments" suggesting it's production-ready (likely for DeepSeek's next models, e.g., V4).
In essence, mHC makes a theoretically superior but previously impractical idea (wider, diversified residuals) viable at scale, potentially unlocking new ways to improve LLMs beyond just more parameters or data. It's seen as a fundamental advance in topological architecture design, with community excitement around implementations and combinations (e.g., with value residuals). The original X thread you linked is a fan announcement hyping it as a "huge model smell" breakthrough.
Sources:
- Paper: mHC: Manifold-Constrained Hyper-Conncetions
- Blog: Understanding Manifold Constrained Hyper Connections
Neural Networks at scale all converge to a statistical model of reality and internal structure.
🏛️ The Platonic Representation Hypothesis
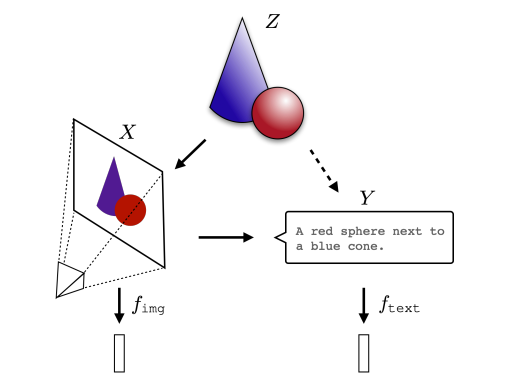
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces. Vision models, language models, different architectures are all slowly approximating the same underlying model of reality.
If this holds up, it's a huge unlock. We could translate between models instead of treating each one like a sealed black box, reuse interpretability wins across systems, and maybe align models at the representation level, not just by policing outputs.
🌌 The Universal Weight Subspace Hypothesis
 Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Their analysis of 1,100+ models (Mistral, ViT, LLaMA) shows they all use a few key "spectral directions" to store information.
This universal structure outperforms assumptions of randomness, offering a blueprint for more efficient multi-task learning, model merging, and drastically cutting AI's computational and environmental costs.
🧊 Deep Sequence models tend to memorize geometrically; it is unclear why
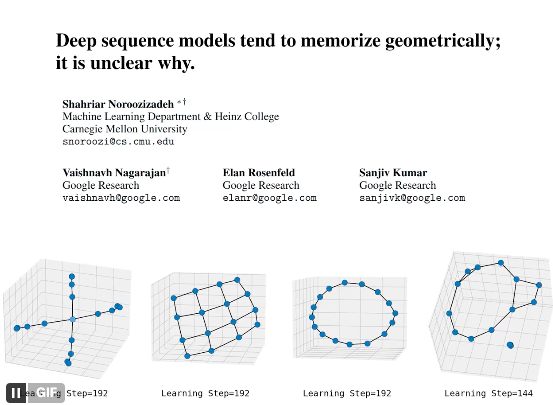 We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
The crazier implication is philosophical. Maybe MEANING isn't just a human convention. Maybe there are natural coordinates in reality and sufficiently strong learners keep rediscovering them.
So what's actually driving the convergence? The data, the objective, some deep simplicity bias? And where does it break?
Sources
- The Universal Weight Subspace Hypothesis > tweet
- The Platonic Representation Hypothesis > tweet
- Deep Sequence models tend to memorize geometrically; it is unclear why > tweet
- Michael Levin - Symposium on The Platonic Space
Videos And Podcasts
The Ridiculous Engineering Of The World's Most Important Machine
The insane machines that make the most advanced computer chips from Veritaseum.
Stanford CME295 Lecture on Transformers & LLMs

Other videos and pods from Dec and Jan:
- Ben Affleck actually knowing AI and the landscape caught me off guard, but as a writer, makes sense https://x.com/ForrestPKnight/status/2012561898097594545?s=20.
- MLST: PhD Bodybuilder Predicts The Future of AI, 97% Certain — Dr. Mike Israetel, this is mostly a fun cross-over debate between 2 podcasters. Please take it with a grain of salt and just as a fun watch.
- MLST: AutoGrad Changed Everything, Not Transformers — Dr. Jeff Beck, Dr. Jeff Beck, mathematician turned computational neuroscientist, this is a deep dive into why the future of AI might look less like ChatGPT and more like your own brain.
- Dwarkesh Podcast: Adam Marblestone – AI is missing something fundamental about the brain, Adam Marblestone is CEO of Convergent Research and a former DeepMind neuroscientist. We discuss how the brain learns so much from so little, what AI can learn from neuroscience, and Ilya’s question of how the genome encodes abstract reward functions—ultimately, the same problem.
- Reinforcement Learning, Agents & OpenEnv
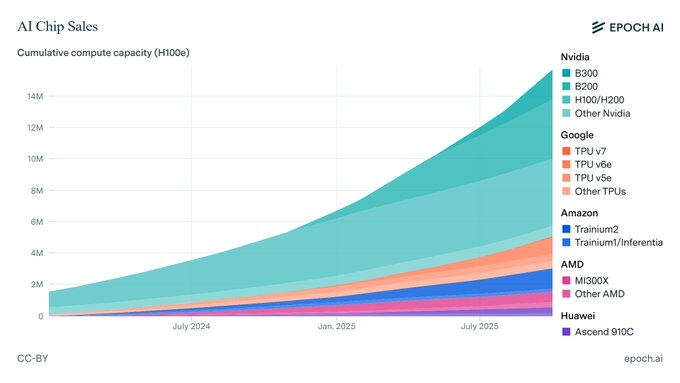
Nvidia
New Chip Vera Rubin Announcement
Nvidia launched a new chip: Vera Rubin. Here how it compares to its predecessor Blackwell:
- 10x lower inference costs
- 4x fewer GPU required for MoE training
- 5x more energy efficient
- 5x longer uptime
- 10x higher reliability
- 18x faster assembly and maintainance.
 sources: https://x.com/nvidia/status/2008357978148130866
sources: https://x.com/nvidia/status/2008357978148130866
Nvidia $20B Groq Acquisition

ℹ️ You guys may have noticed a trend in the recent AI acquisitions: they hire the founder + few leadership position and leave the rest of the team in a zombie company, this happened with Meta > Scale, Google > Windsurf, and now NVIDIA > Groq and Meta > Maus. So why is that? Well it turns out this solution avoids antitrust scrutiny.
Groq has entered into a non-exclusive licensing agreement with Nvidia for Groq’s inference technology. Groq Cloud will continue to operate without interruption. This blog post breaks down the antitrust loophole that enabled NVIDIA to close this $20B deal: https://ossa-ma.github.io/blog/groq.
What Nvidia Actually Bought (And What It Didn't)
Nvidia acquired:
- All of Groq's intellectual property and patents
- Non-exclusive licensing rights to Groq's inference technology
- Jonathan Ross (CEO), Sunny Madra (President), and the entire senior leadership team
Nvidia explicitly did NOT buy:
- GroqCloud, the cloud infrastructure business, which continue with its CFO Simon Edwards. This is because KSA (Kingdom of Saudi Arabia) uses this service, and Nvidia preferred to avoid extra scrutiny on offering inference to a foreign country.
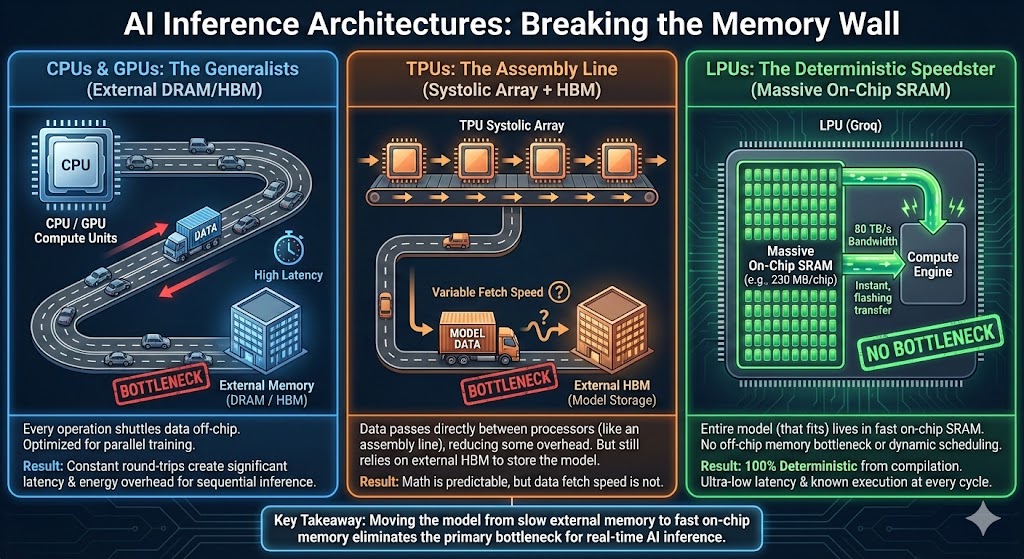
GPUs vs TPUs vs LPUs — Why are LPU are important to Nvidia?
Jonathan Ross built TPUs at Google, then started Groq to build LPUs. LPUs is a new architecture that optimize for inference and Jonathan is a strong leader in the industry.
META buys Manus at $2-4B
Meta just bought Manus, an AI startup everyone has been talking about https://x.com/TechCrunch/status/2005876896316469540.
- Manus hit $100M ARR in ~9 months and sold for ~$2–4B, proving consumer agent products can scale fast and earn software-like multiples—validating agentic AI as a real revenue category.
- Strategic acqui-hire: Meta picks up a team known for production-grade agent scaffolding and SOTA results, accelerating automation of complex white-collar work (coding, ops, computer use).
- Consolidation + scale: Folding the fastest-growing B2C AI player into Meta centralizes agent expertise and distribution; early Singapore hiring points to rapid global rollout.

GeoPolitics
Note: our mission is to democratize AI via open source knowledge and decentralization. With that in mind our community tries to share objective views.
Venezuela
United States capturing the Venezuelan president Maduro has large implication in geopolitics. Peter Zeihan, one of my favorite geopolitics expert https://youtu.be/ddojVgGAryQ?si=nfpK2_JZNnjt334Q explains how by taking Venezuela, the US is showing a clear expansionist plan, following the Monroe Doctrine.
TSMC
TSMC produce 90% of the world semi, from Nvidia GPUs, to iPhone chips, cars chips, and even defense systems. An invasion could halt production causing an economic shock. Everyone needs those chips for now, this might change, according Reuters, China built a prototype extreme ultraviolet lithography (EUV) machine in Shenzhen https://x.com/Megatron_ron/status/2001637940988899683. Everyone is starting to build their or chip fab.

These interesting blog posts from SemiAnalysis.com can shine some light on TMSC:
- Semi Analysis - TSMC Overseas Fabs – A Success? https://newsletter.semianalysis.com/p/tsmc-overseas-fabs-a-success
- Semi Analysis - Why America Will Lose Semiconductors https://newsletter.semianalysis.com/p/why-america-will-lose-semiconductors?utm_source=publication-search
- Equity Analysis - TSMC: The Silent War for Global Dominance is Being Fought HERE, https://substack.com/home/post/p-167371968
Models Leaderboard
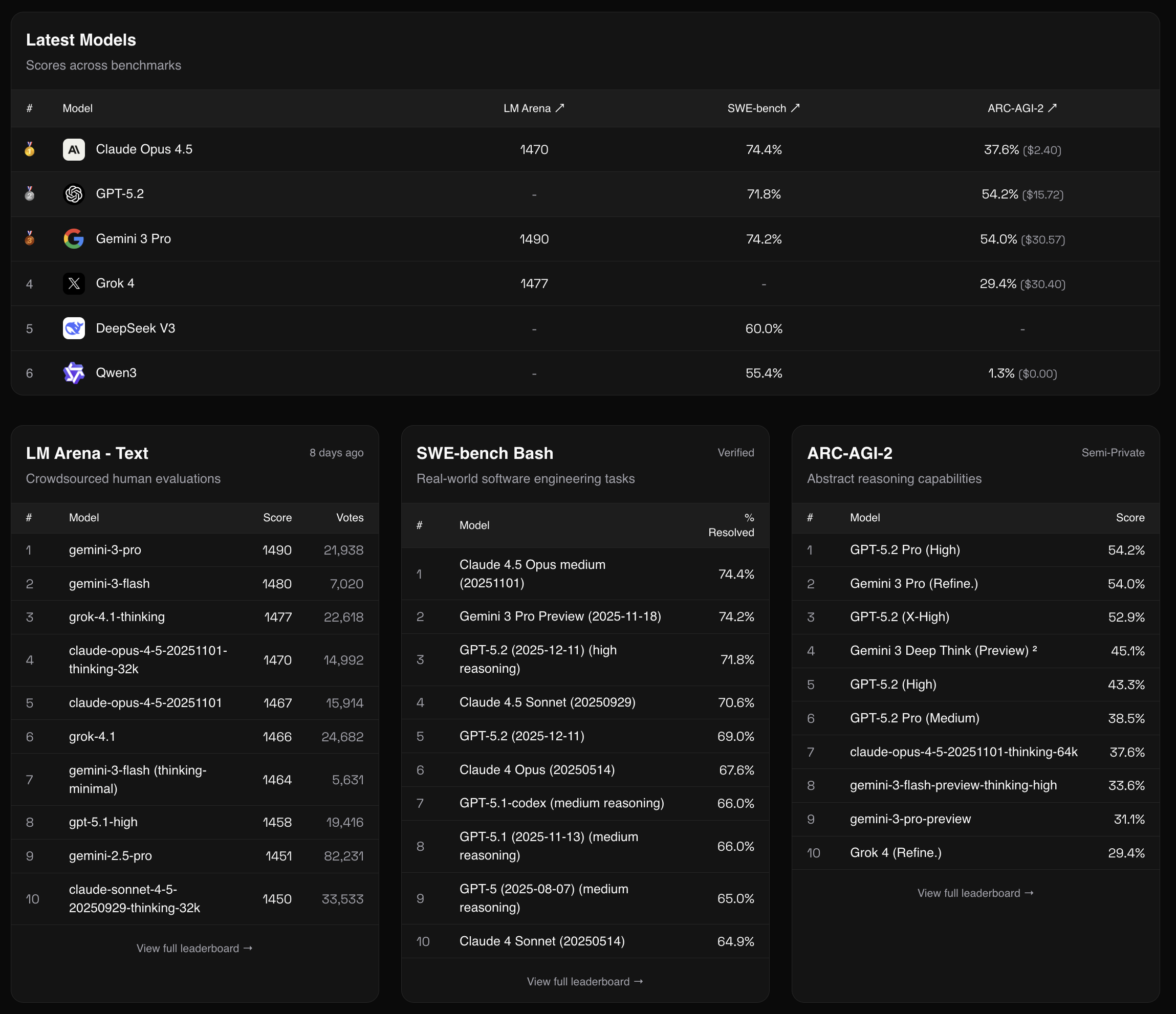
Link: aisocratic.org/leaderboard
We're In The "Vibe" Code Age
I went personally went from 80% of my code being AI via copy/paste to now being 100% via Claude Code. Coding has officially changed for good!
If you recall Dario Amodei mentioned AI covering 90% of coding by end of 2026, turns out we reached 100%. Claude Code was released in May 2025, as a side project, with last month Anthropic released Opus 4.5, it's now arguably the most productive software ever made. OpenAI AGI definition is about an AI that "outperform humans in most economically valuable work", are we there already?
80% of Americans have no idea what Anthropic is (stats from Aug 2025)
Engineers prefer Claude over Cursor because of its simplicity. So Is Claude code going to replace Cursor?
Claude Cowork lets you complete non-technical tasks much like how developers use Claude Code. Pretty much is Claude connected to your file system.
Chrome Extension
Claude just added a Chrome extension and I argue is the most productive tools ever. Not only your CLI gets eyes, it also can automate workflows that don't have an API.
Ralph Wiggum: Infinite Loop
There's now have an official plugin marketplace. One plugin got extra attention ralph-wiggum, which pretty much is an infinite loop over a task until done:
while :; do cat PROMPT.md | claude ; done
Second Order Effects — Software Companies Are Cooked
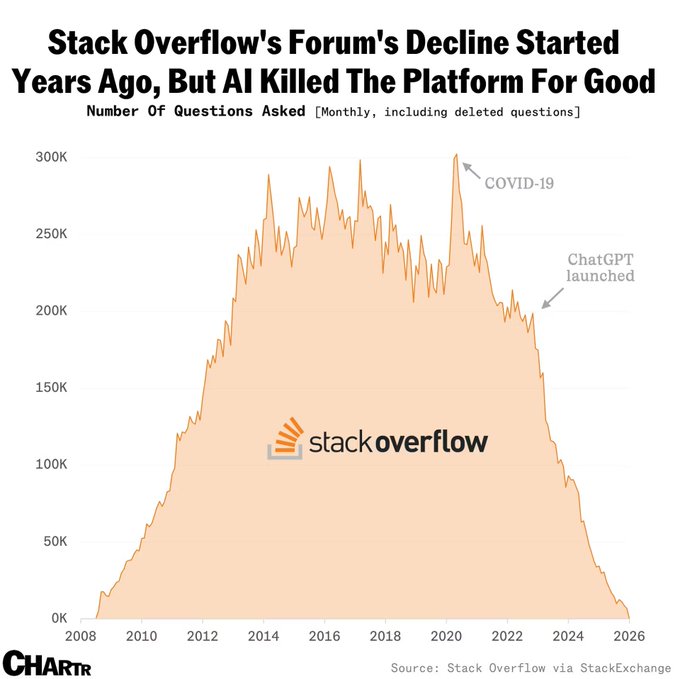
Stack Overflow has seen the number of monthly questions on its platform collapse from 300k to ~0 since launch of ChatGPT.
Tailwind just cut 75% of their team (3/4 engineers) "because of the brutal impact AI has had on our business".
... And First Order Effects — SaaS Companies Are Cooked
...
More interesting updates around Claude Code
- Claude Agent SDK tutorial by Nader Dabit, one of our favorite engineers teachers https://x.com/dabit3/status/2009131298250428923.
- iMCP, macOS app for connecting your digital life to AI via MCP, https://github.com/mattt/iMCP.
- Jonathan Ross is bullish on new AI jobs: https://x.com/realBigBrainAI/status/2012887773150343484.
- How to automate your life with claude code (for non-technical people) https://x.com/damianplayer/status/2012611857392009242.
- Claude Research mode is goated! https://x.com/yoheinakajima/status/2012329179019448507.
- How the creator of claude code actually writes software https://x.com/yoheinakajima/status/2012329179019448507?s=20
- Anthropic has an 80% talent retention rate! https://x.com/Yuchenj_UW/status/2012027217539449143
- Warcraft 2 / Starcraft control panel https://x.com/idosal1/status/2011124558976434469.
- Productivity tip for large task: let Claude interview you using AskUserQuestionTool, then execute the finalized spec in a new session https://x.com/trq212/status/2005315275026260309.
Cursor + GPT 5-2 built a browser (3M lines of code)
Concurrent agents ran uninterrupted for one week. Each agent had a role: planner, worker, judge. According Cursor blog post GPT 5.2 is better at long-running tasks than Opus 4.5. Adding more management hurts performance, lol. Turns out, scaling agents looks a lot like scaling companies https://x.com/Yuchenj_UW/status/2011863636042469866.
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
About the Authors

Related Posts

AI Socratic July 2026 — Lost In J-Space
Anthropic’s Fable 5 is back under strict safety rubrics, OpenAI’s launched GPT-5.6, Meta launched Muse Spark 1.1 model and Meta Compute.

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.