
The most important AI news and updates from last month: Oct 15 – Nov 15.
Sign up to receive the mailing list!
🗓️ November Events
Let's start with announcing a new chapter for the AI NYC: AI Builders Milan. Roberto Stagi is taking-on the leadership to organize the AI aperitivi. We're super excited about this!
AI Aperitivo 1.0
Milano
Tuesday, November 18
AI Builders Milan is hosting the first AI Aperitivo 🍸🍷🫒🧀 bringing together Milan's top AI engineers, researchers, and founders for an evening of Socratic dialogues.
Event: AI Aperitivo 1.0


AI Dinner 15.0
New York
Wednesday, November 12
AI NYC is hosting another AI Dinner 🍲🍕🍺 , we'll discuss news and updates using this blog post to run the Socratic dialogues.
Event: AI Dinner 15.0
Hyperscalers News
Meta: Yann LeCun is out


McKinsey Survey — The State Of AI in 2025

AI use is widespread, but mostly are at early stage experimenting with AI and AI agents. High performers redesign workflows. Only 39% report financial impact (EBIT).
Link: mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Extropic — Thermodynamic Computing
Extropic just released a new type of hardware called Thermodynamic Sampling Units (TSUs). Their approach, called thermodynamic computing, flips traditional computing on its head. Instead of fighting against the random "noise" (thermal fluctuations) in electronics to force clean 0s and 1s, they embrace that noise as the core of the computation.
There's a lot of controversy around it, from the hardware design that looks like a 3d printed mesh with unnecessary symbols around it, to the obfuscated technical details.

OK let's see how it works (according Extropic writing itself).
The Hardware Foundation: Probabilistic Bits (p-bits) in CMOS Chips
- Traditional chips (CPUs/GPUs) use transistors to suppress thermal noise, locking electrons into binary states (0 or 1) for deterministic logic.
- Extropic runs CMOS circuits (standard silicon tech) in "subthreshold" mode: low voltage, low frequency, where thermal noise dominates. Electrons aren't forced into fixed states—they fluctuate naturally between high and low-energy "wells" defined by neighboring voltages.
- These fluctuations create p-bits, which act like tiny switches that probabilistically flip based on energy. Low-energy states happen more often (higher probability), mimicking natural sampling from a distribution. It's like the electrons are "voting" on the best configuration through physics alone.
The Computation Process: Annealing via Energy Minimization
- You program the chip by setting "starting conditions and constraints" (e.g., voltages that define the energy landscape for your problem, like a Sudoku puzzle or an AI model's probability graph).
- The system "anneals": Electrons interact across the network, redistributing energy until it settles into the lowest-energy state. This happens in parallel—millions of p-bits explore possibilities simultaneously via thermal jitters, drawing samples from the target distribution in essentially one "settling" step.
- Analogy from X: It's like shaking a box of bouncy balls on a hilly landscape—they all roll to the valleys (optimal solutions) at once, instead of one ball searching sequentially. @EarningsNugget This is similar to quantum annealing (e.g., D-Wave systems) but at room temperature, no exotic cooling needed.
The Software Layer: Denoising Thermodynamic Models (DTMs)
- Extropic pairs this with DTMs, an algorithmic architecture for tasks like generative AI. It includes:
- Energy-Based Models (EBMs): Encode your problem as a probabilistic graph (e.g., word probabilities in a sentence).
- THRML Library: A framework (currently simulatable on GPUs/CPUs) that maps these to the hardware. It scales to 1 million p-bits for real demos, like solving optimization puzzles.
- The chip reads analog voltages, computes biases, lets noise settle the state, measures the output, and digitizes it. No heavy numerical simulation—physics handles the sampling natively.
Comparison between regular GPU/CPU and TSU

THRML: (simulated) probabilistic programming language
Extropic also released a probabilistic programming language and a python library to simulate how it runs. How to run THRML by David Shapiro.
AI Browser War 🌐
In the past few months we've seen a lot of new AI browser coming up. They're all chromium copy with extra AI features. Google has yet to upgrade Chrome with AI capabilities. Let's explore the new browsers:
Dia
The Internet Company Of New York — yes that's the name — started the AI browser trend with Arc Browser, and then evolved into Dia. The main feature of Dia is the AI sidebar that lets you talk with one or multiple pages at the same time. Dia was purchased recently by Atlassian — sadly for me, because it was my browser of choice and Atlassian reputation for high quality software is not the best, if you ever used JIRA you know what I mean.
Comet
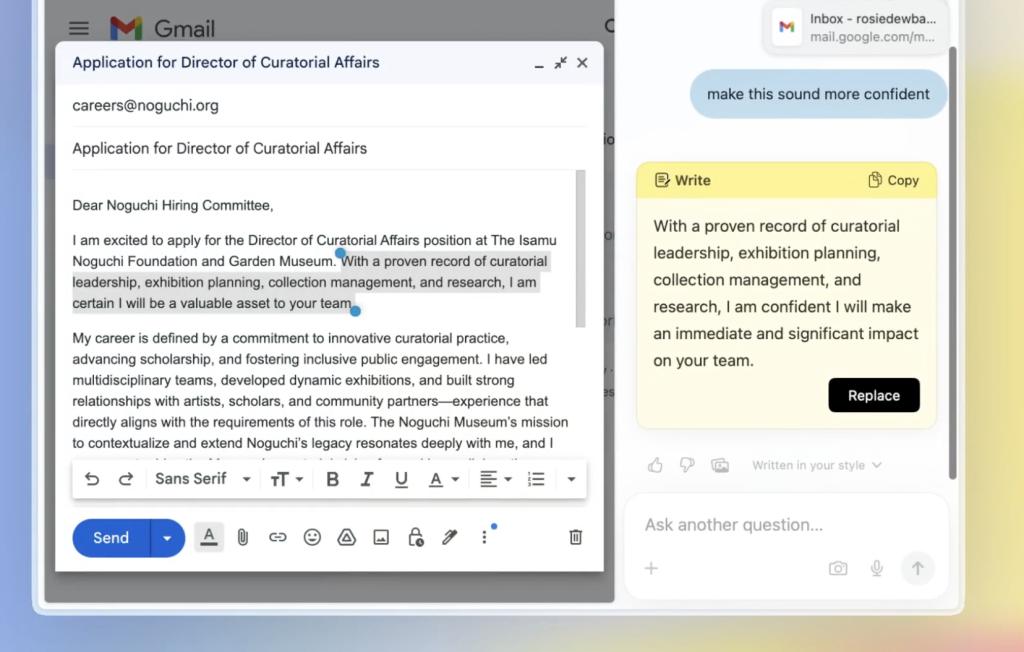
Perplexity AI is expanding from search engine into other sectors, trying to capture a piece of the pie — and if you ask me, I believe they're trying to get purchased by one of the MANGO companies. The main feature of Comet is the AI assistant that lets you automate email/calendar/shopping.
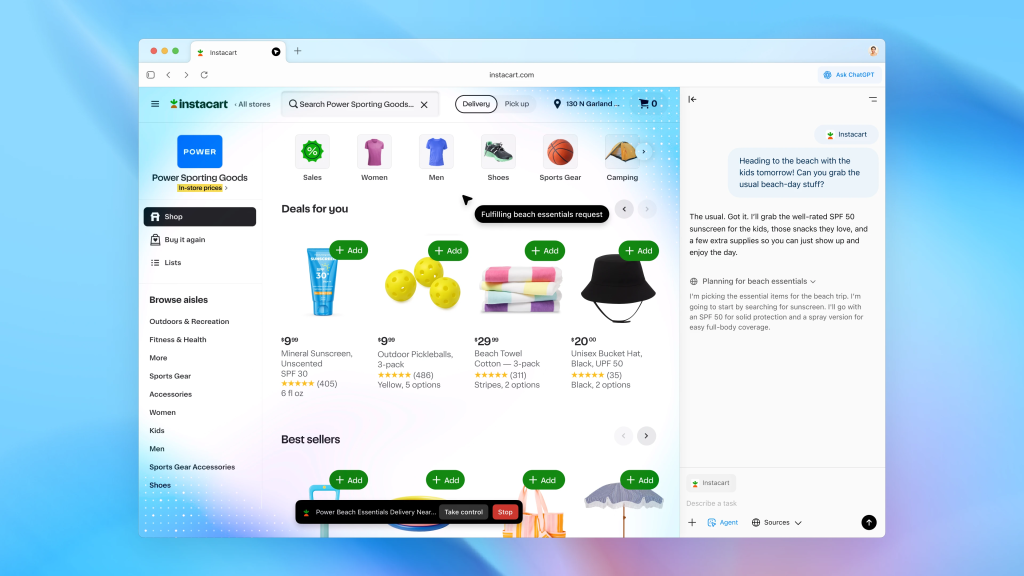
Atlas
OpenAI launched Atlas in October. It much integrates ChatGPT in every page and it allows you to run AI agent observing what it does in the browser. It looks impressive at first, I've asked to duplicate the last Luma AI dinner event: it opened Luma, signed up, went to the settings page, and somehow it got stuck in a loop. It has a button "stop" that lets you take control, so at least for now you can stop it, continue the tasks manually, and then ask it to continue the automation.
Conclusion
Whatever browser you're using today, switching won't give you a 10x improvement, at least won't give you anythig more than just installing the chatgpt extension. But it's clear that the internet "explore and click" as we know it is going to change into an intent based internet.


| The best ChatGPT that $100 can buy.
⭐️ Andrej Karpathy, our AI legend, just dropped nanochat, a complete, end-to-end implementation of an LLM-based chat assistant like ChatGPT — but compact, clean, and easy to hack. The entire stack, from tokenization to web UI, is implemented in one minimal codebase with almost no external dependencies.
It’s designed to run on a single 8×H100 node, orchestrated by simple scripts like speedrun.sh, which execute the entire lifecycle — tokenization, pretraining, finetuning, evaluation, inference, and even web serving through a lightweight chat interface.
In short, Nanochat lets you train, run, and chat with your own LLM — all for about the cost of a weekend GPU rental.
⭐️ Read the this introduction doc to learn all the steps Nanochat execute with the speedrun.sh file: github.com/karpathy/nanochat/discussions/1.
Repo: github.com/karpathy/nanochat
Nanochat test: nanochat.karpathy.ai
Research
DeepSeek-OCR: Revolutionary Context Compression Through Optical 2D Mapping
DeepSeek AI has unveiled DeepSeek-OCR, a groundbreaking approach to compressing long contexts via optical 2D mapping. This innovative system demonstrates that vision-based compression can achieve remarkable efficiency in handling text-heavy documents, potentially revolutionizing how large language models (LLMs) process extensive textual information.
The DeepSeek-OCR system consists of two primary components: DeepEncoder and DeepSeek3B-MoE-A570M as the decoder. Together, they achieve an impressive 97% OCR precision when compressing text at a ratio of less than 10× (meaning 10 text tokens compressed into 1 vision token). Even at an aggressive 20× compression ratio, the system maintains approximately 60% accuracy.
Karpathy questions if all LLMs input should actually be images, the advantages are:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- the tokenizer must go. It import all the ugliness of Unicode, byte encoding, and a lot of historical babbage and security jailbreak risks.
Links
- x.com/karpathy/status/1980397031542989305
- deepseek.ai/blog/deepseek-ocr-context-compression
- x.com/vllm_project/status/1980235518706401405
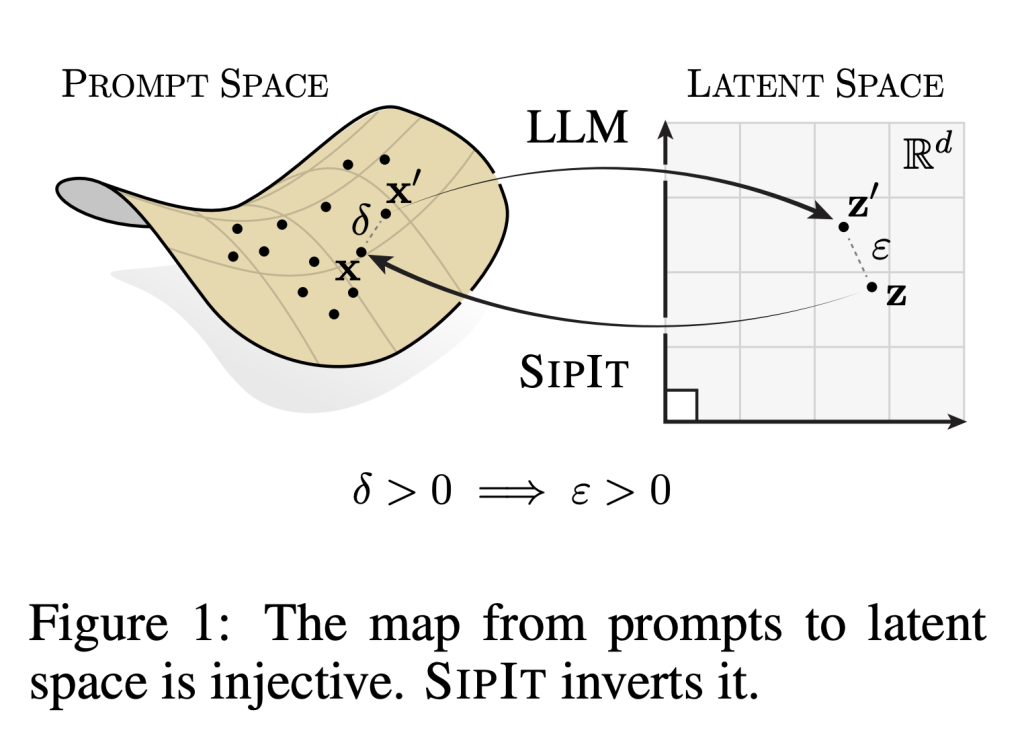
Language Models Are Injective And Hence Invertible — It's possible to find the initial prompt from an output.

· Claim: Decoder‑only transformer LMs are almost‑surely injective: different prompts map to unique last‑token hidden states; this holds at initialization and is preserved under gradient descent.
· Method: Prove components are real‑analytic, show collisions occur only on a measure‑zero parameter set, and that GD updates don’t move parameters into that set in finite steps.
· Evidence: Billions of collision tests on six SOTA LMs found no collisions.
· Algorithm (SipIt): Reconstructs exact input text from hidden activations by exploiting causality; sequentially matches each token’s hidden state given the known prefix; offers linear‑time guarantees.
· Failure cases: Applies to decoder‑only transformers with analytic activations and continuous initialization; quantization, weight tying, duplicated embeddings, or non‑analytic parts can break injectivity. OK there are ways to preserve "privacy" to the question.
Paper: arxiv.org/abs/2510.15511
LLM as a Judge — We’re stepping into a new era where AI doesn’t just predict behavior. It understands preference.

Instead of simulating clicks and scrolls, researchers let LLMs reason which playlist, feed, or product lineup you’d actually prefer.
And it worked. Across Amazon, Spotify, MovieLens, and MIND datasets, they found:
- LLMs can rank full slates (not just single items) with strong coherence
- Logical consistency directly predicts preference accuracy
- Pretrained models generalize no fine-tuning required
link: x.com/alxnderhughes/status/1988202281314251008
Does RL improve LLM reasoning?

This paper got top score at NeurIPS 2025. It aims at answering: does RL make LLM better reasoners?
The authors study Reinforcement Learning with Verifiable Rewards (RLVR) and find that while it improves accuracy for small k, it doesn’t create new reasoning patterns — meaning the base model still determines the upper limit of reasoning ability.
Interestingly, it’s distillation, not RL, that shows genuine signs of emergent reasoning 😮.
link: x.com/jiqizhixin/status/1987710546674856051
web: limit-of-rlvr.github.io
Continuos Autoregressive LLM

Tencent + Tsinghua just dropped a paper called Continuous Autoregressive Language Models (CALM) and it basically kills the “next-token” paradigm every LLM is built on.
Instead of predicting one token at a time, CALM predicts continuous vectors that represent multiple tokens at once.
Meaning: the model doesn’t think “word by word”… it thinks in ideas per step.
→ 4× fewer prediction steps (each vector = ~4 tokens)
→ 44% less training compute
→ No discrete vocabulary pure continuous reasoning
→ New metric (BrierLM) replaces perplexity entirely
link: x.com/rryssf_/status/1985646517689208919
Learning
Perplexity in NLP measures how well a language model predicts text; lower means better.

Videos
https://www.youtube.com/watch?v=iO03t21xhdk&feature=youtu.be&themeRefresh=1
https://www.youtube.com/watch?v=29gkDpR2orc&t=890s
MLST — AI benchmarks are broken! [Prof Melanie Mitchell]
I really love this part of the MLST interview in which Prof Mitchell says the key LLM question is: what kind of “understanding,” if any, is really going on?
- They don’t and can’t truly “understand” — it’s just word statistics.
- They do form rich, concept-like mental models.
- Or their huge correlations amount to a new, non-human kind of understanding.
https://youtu.be/fS-NN6VRzT8?si=0SJl24g9cIW1IVwm
In search of Nothing | David Deutsch, Lee Smolin, Amanda Gefter
https://www.youtube.com/watch?v=rMSEqJ\_4EBk
MLST — Google Researcher Shows Life "Emerges from Code"
Blaise Agüera y Arcas explores some mind-bending ideas about what intelligence and life really are—and why they might be more similar than we think
Hyperscalers News
Meta: Yann LeCun is out


McKinsey Survey — The State Of AI in 2025

AI use is widespread, but mostly are at early stage experimenting with AI and AI agents. High performers redesign workflows. Only 39% report financial impact (EBIT).
Link: mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
About the Authors

Related Posts

AI Socratic July 2026 — Lost In J-Space
Anthropic’s Fable 5 is back under strict safety rubrics, OpenAI’s launched GPT-5.6, Meta launched Muse Spark 1.1 model and Meta Compute.

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.