
The most important AI news and updates from June 15 to July 15.
Sign up to receive the mailing list!
AI Dinner 12.0
We’ll discuss the top news and updates from this blog post using the Socratic methodolgy. As well as going through few presentations. lu.ma/ai-dinner-12.0.

This event is sponsored by the Solana Foundation

Grok 4 gets an AI companion
xAI just launched Grok 4. The xAI benchmark showed it as a new SOTA model, but twitter accounts showed a different story. Some of the highlights include:
- 100× more training than Grok 2 and 10× more RL compute than any other model (img1)
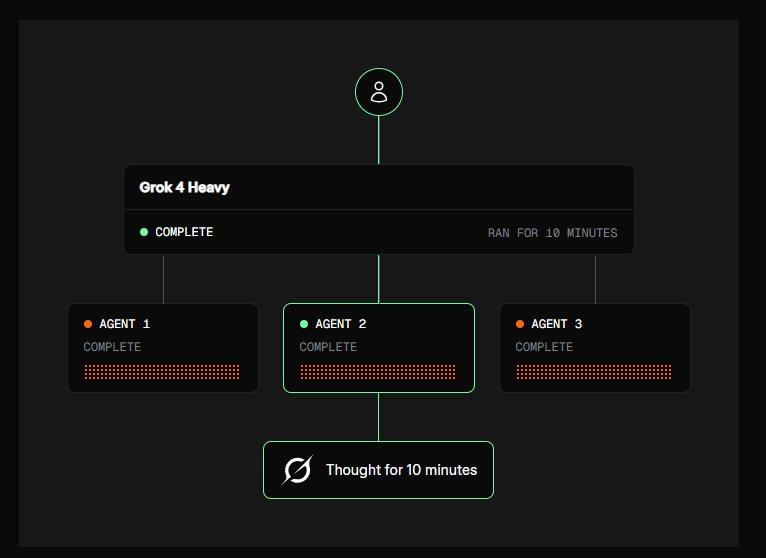
- Grok 4 is single-agent, Grok 4 Heavy is multi-agent with higher performance (img2)
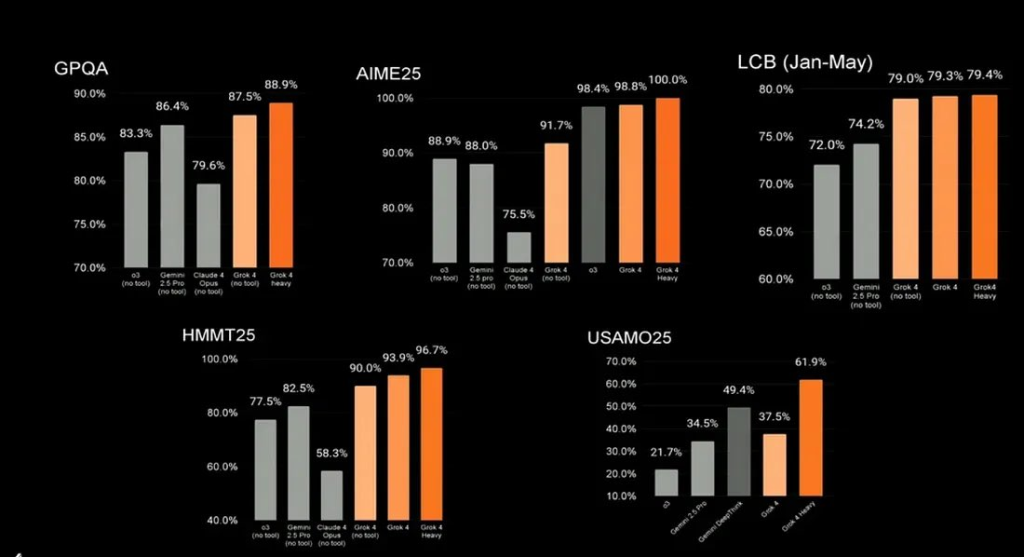
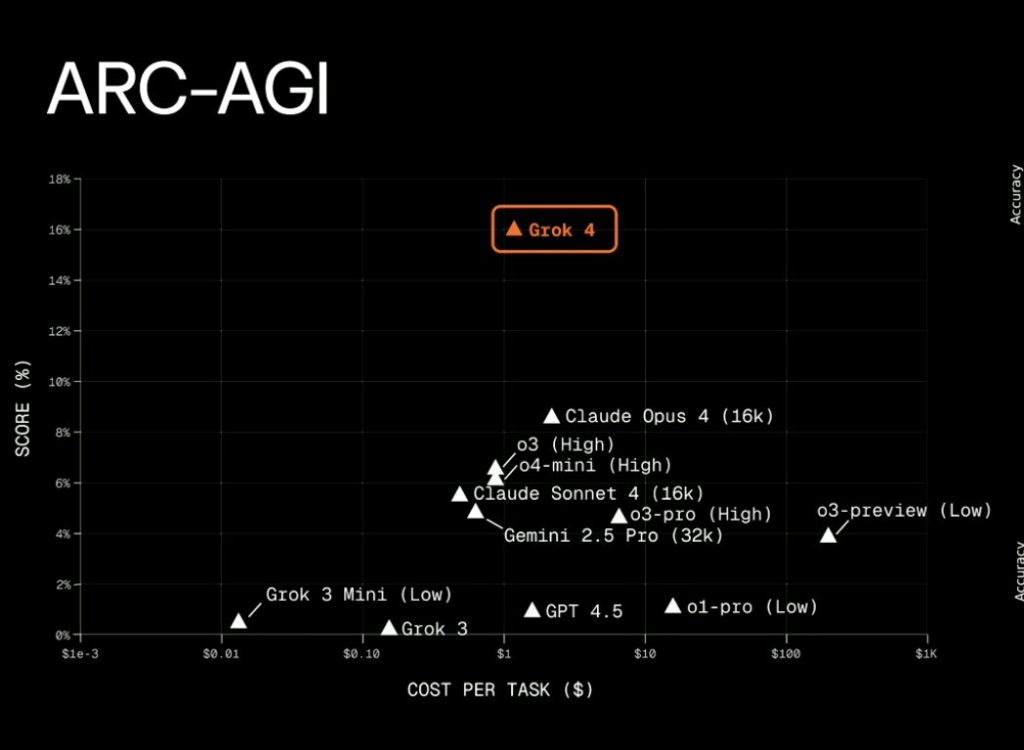
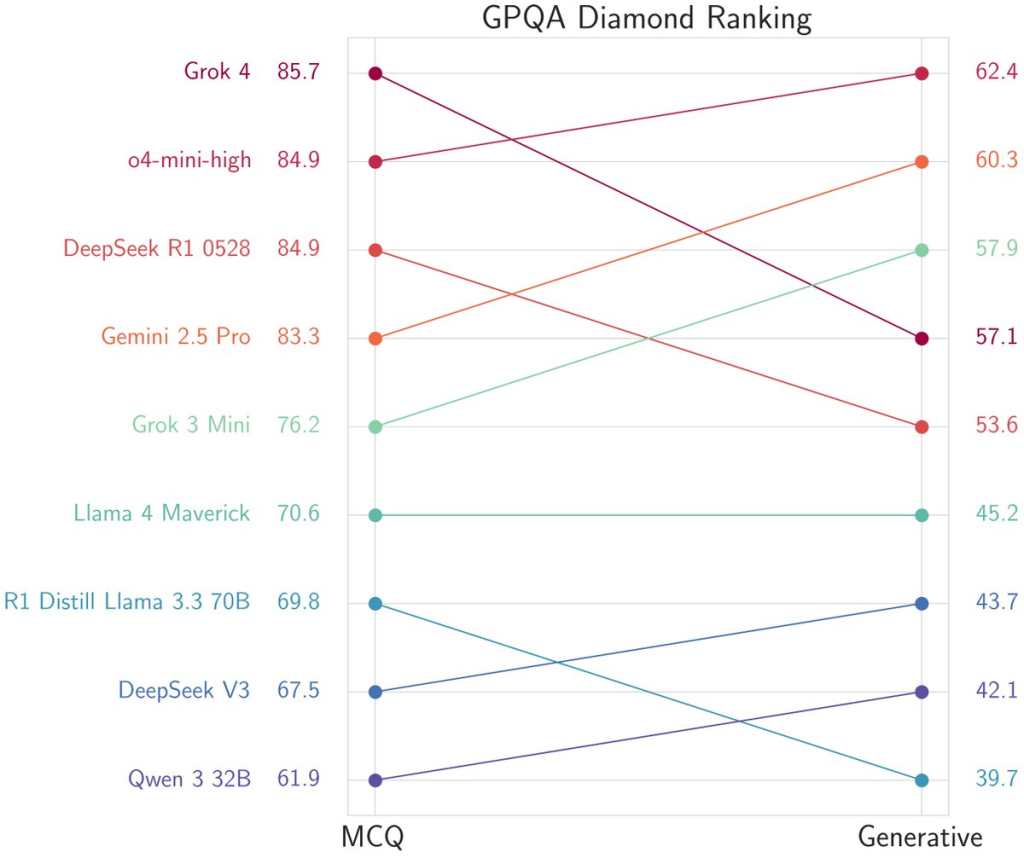
- It achieves state-of-the-art on most public benchmarks: HLE, AIME25, Vending machine, ARC and ARC2 (img 3)
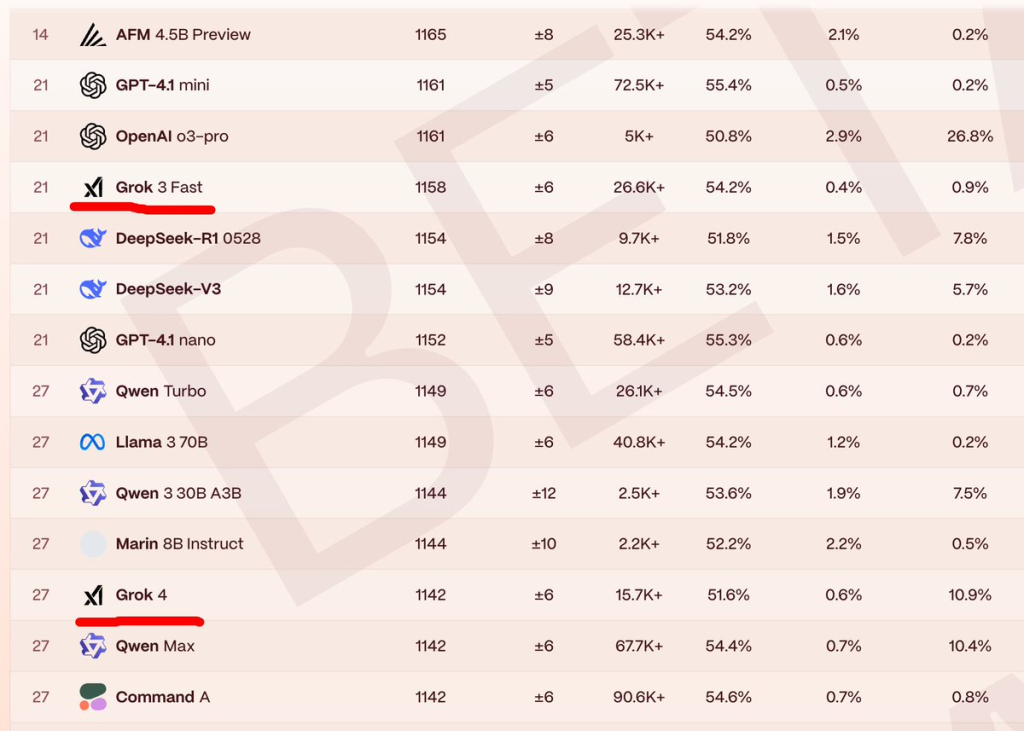
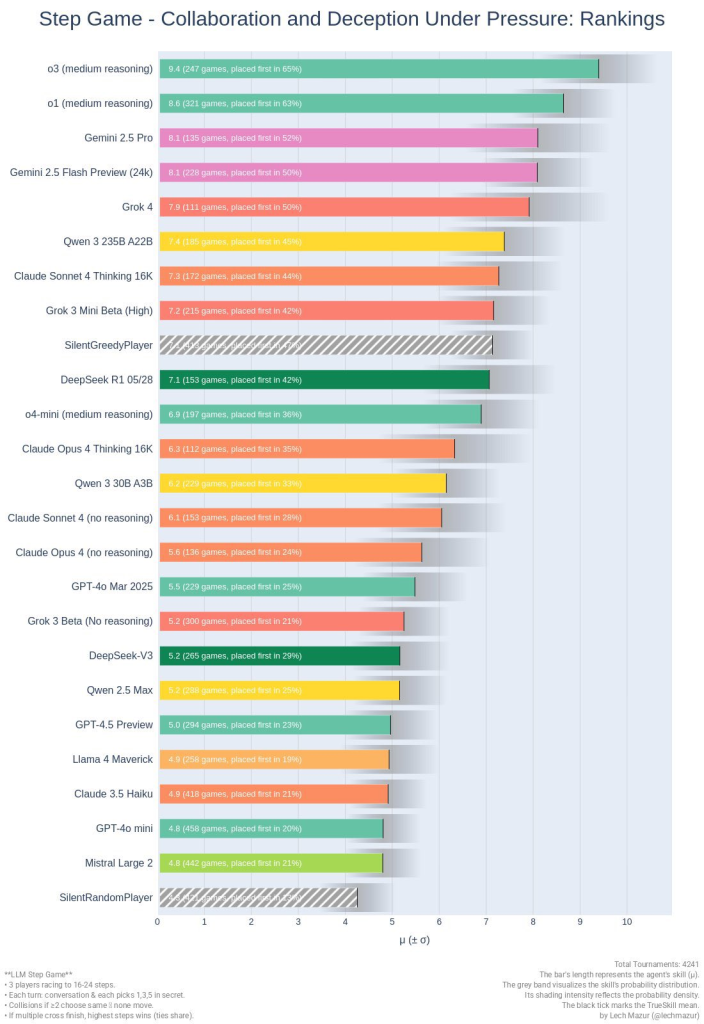
- Local benchmark and empirical testing show a different story (img 4,5,6)
Grok 4 has is Ghibli moment with the sex companions and the unhinged one:

Windsurf's Updates
OpenAI is having a rough time lately, as they kept on losing key researcher to Meta and Google. Especially missing out on the Windsurf acquisition. Google actually is acquiring Windsurf, but the new mechanism to do this which doesn’t run into bogus “antitrust” objections is to buy the assets rather than the company. Like all these other deals. Investors and founders get paid, employees don't.
https://x.com/BoringBiz_/status/1943821289451327771
Luckily Cognition Labs came to the rescue of the Windsurf employees, acquiring the company. The Windsurf employees will have a chip on the shoulder now: https://x.com/windsurf_ai/status/1944820153331671123

Another fun fact, Windsurf new office is Silicon Valley Pied Piper office building, lol!
Kimi 2 👑 — New open source 1T LLMs
Kimi 2 is a new open source model from Moonshot, that uses a similar architecture of DeepSeek V3, with fewer heads, and more experts.
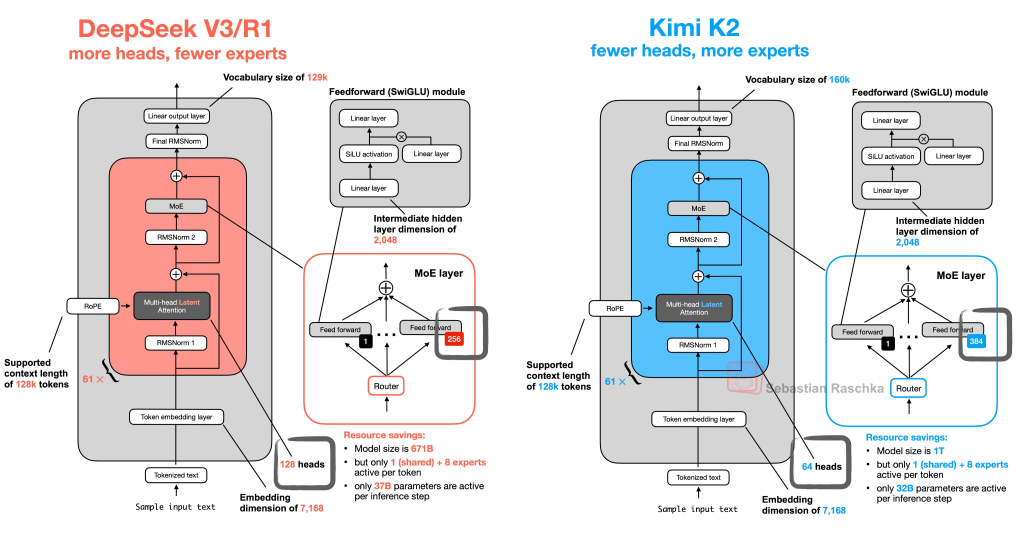
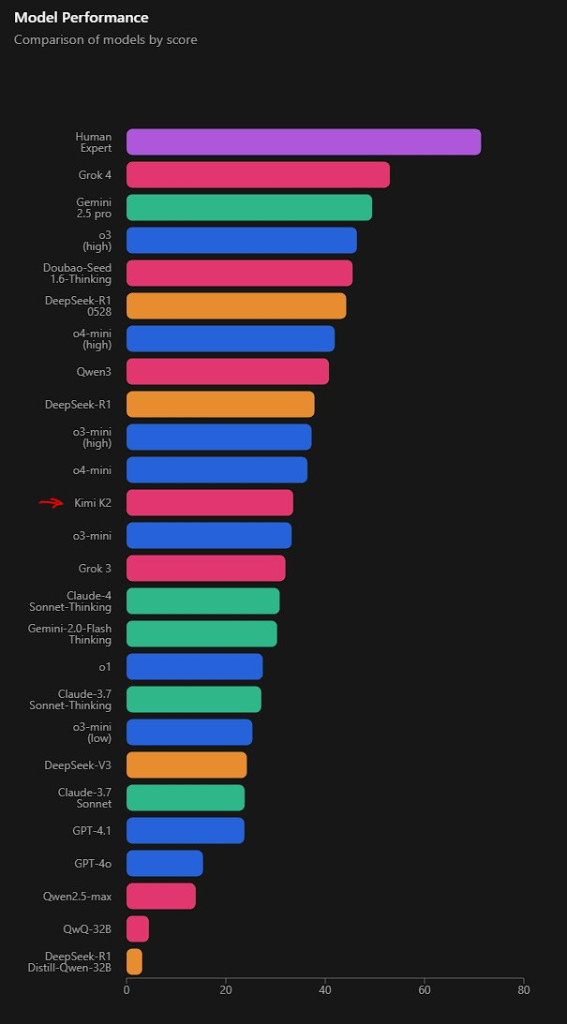
It's really cheap and fast, taking SOTA position on several benchmarks.
https://x.com/sam\_paech/status/1944276326598553853
Muon was one of the key to Kimi K2's success!
They replaced AdamW with a custom optimizer and then patched stability hiccups with MuonClip. Loss curve smooth across 15.5T training tokens. It keeps the model calm while it learns.
Muon keeps training stable because it treats every weight matrix as a single object and updates it with an orthogonalized step.

What is AdamW
Adam (short for Adaptive Moment Estimation) is a popular gradient-based optimization algorithm used to train deep learning model. It combines the advantages of two others optimizers: AdaGrad and RMSProp.
Adam Adapts the learning rate for each parameter by maintaining two moving averages:
- First moment (mean) - like momentum
- Second moment (variance) - scales updates based on recent gradient magnitudes.
The key differences with AdamW
AdamW, the usual optimizer, adjusts each parameter independently with first‑ and second‑moment statistics.
That per‑element rule is simple but it ignores how rows and columns of a weight matrix interact, it carries two momentum buffers, and its update size depends on the running variance of each element.
Muon, by contrast, looks at the whole matrix at once, keeps just one momentum, aligns the step with the spectral norm constraint, and then shares the same learning rate schedule that was tuned for AdamW.
The result is a more uniform, numerically safe update that trains in fewer floating‑point operations while matching or beating AdamW on every reported benchmark.
paper: arxiv.org/abs/2502.16982.
Comparison of Muon AdamW and Adam
Feature
Muon
AdamW
Adam
Update Type
Orthogonalized momentum on 2D weights
Adaptive (momentum + RMS)
Same as AdamW but mixes in weight decay
Weight Decay
Decoupled (via matrix-level updates)
Decoupled (explicit)
Coupled (less effective)
Adaptive LR
❌ (fixed LR + semi-orthogonal updates)
✅ Yes
✅ Yes
Optimizes
Only 2D weight matrices (e.g. linear)
All parameters
All parameters
Speed vs AdamW
Up to 2× faster on LLM pretraining
Baseline
Similar to AdamW
Generalization
Strong (from better conditioning)
Good
Slightly worse
Stability
High in large-scale training
High
Medium
Used In
Moonlight, MoE LLMs
GPT, BERT, T5, most transformers
Legacy use, some fine-tuning
Open Source
Yes (Muon)
Yes
Yes
More info here: https://x.com/rohanpaul_ai/status/1944079810386436505.
Fun fact, CEO @Kimi_Moonshot was the first author of XLNet and TransformerXL https://x.com/NielsRogge/status/1944035897231528112.
Let's enter the AI Code CLI war
First ever AI Code CLI battle royal: claude-code, anon-kode, codex, opencode, ampcode, gemini.
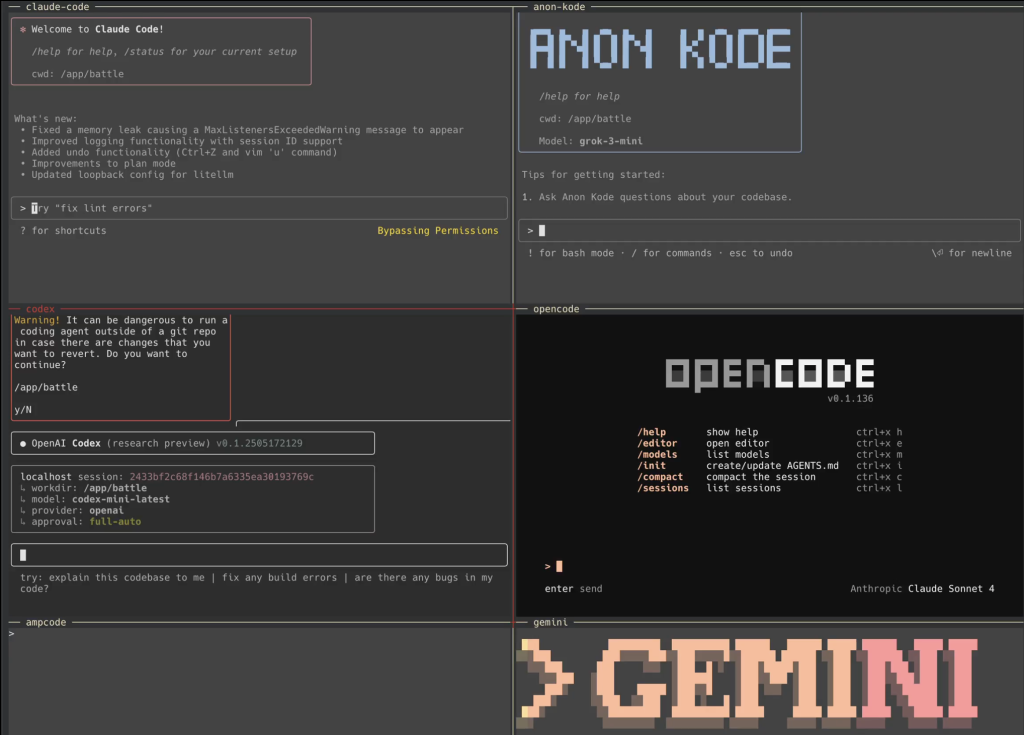
https://x.com/SIGKITTEN/status/1937950811910234377
- Google releases Gemini CLI https://x.com/i/status/1937861646082515205
- AWS releases its own Cursor and Code CLI too https://x.com/GunnarGrosch/status/1945361246313734532.
Research
U-Net, a new a recursive tokenizer
Avoids using predefined vocabs and memory-heavy embedding tables. Instead, it uses Autoregressive U-Nets to embed information directly from raw bytes. This enables infinite vocab size and more.
https://x.com/omarsar0/status/1935420763722629478
A comment on "The Illusion of Thinking"

Pfizer researchers argue that what looks like a collapse in AI reasoning may actually be an Agentic gap — models failing not in thought, but in action.
When given tools, the same models crushed tasks they had just failed. The problem isn’t thinking, it’s interface.
A must-read reframing of “The Illusion of Thinking.” Agentic intelligence is the real frontier.
Potemkins Understanding in LLM
The paper documents a pattern they called Potemkins, a kind of reasoning inconsistency (see figure below). They show that LLMs - even models like o3 — make these errors frequently.
Gary Marcus: "You can’t possibly create AGI based on machines that cannot keep consistent with their own assertions. You just can’t."

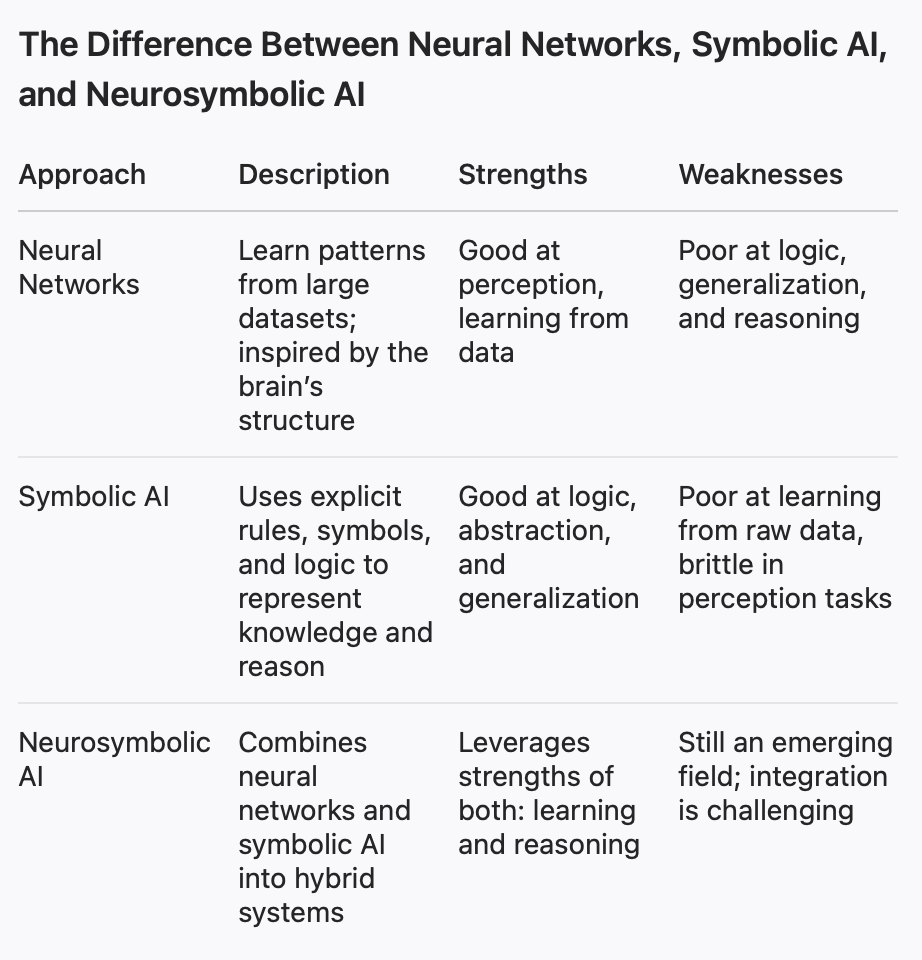
Since we're talking about Gary Marcus, let's diverge a second, here's some amazing blog post from Gary, on Neurosymbolic AI:
Gary Marcus’s essay traces the decades-long debate between two main approaches in artificial intelligence:
-
Symbolic AI (symbol-manipulation approach): Rooted in logic and mathematics, this tradition uses explicit rules, symbols, and databases to represent knowledge and perform reasoning.
-
Neural networks (connectionist approach): Inspired by the brain, these systems learn from large amounts of data and are the foundation of today’s large language models (LLMs) like GPT.
https://garymarcus.substack.com/p/how-o3-and-grok-4-accidentally-vindicated
And more rants from him on the crisis in the industry with talents getting swopped left and right.

Videos And Podcasts
https://x.com/karpathy/status/1935518272667217925
https://x.com/dwarkesh\_sp/status/1938271893406310818
Sign up to receive the mailing list!
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
About the Authors

Related Posts

AI Socratic July 2026 — Lost In J-Space
Anthropic’s Fable 5 is back under strict safety rubrics, OpenAI’s launched GPT-5.6, Meta launched Muse Spark 1.1 model and Meta Compute.

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.