
Updated on Sep 6th
The top AI developments from Jul 15–Sep 15, debated Socratically over AI dinners in NY and SF. This is our 1st draft.
Sign up to receive the mailing list!
Upcoming Events
This time around we’ll have 2 events, one in New York, and one for the first time in San Francisco at the Frontier Tower. We’ll discuss the top news and updates from this blog post using the Socratic methodology, and we’ll have a line up of demos and presentations!
AI Dinner
Sep 10th, Solana Skyline
New York City

Link: https://lu.ma/ai-dinner-13.0
AI Dinner
Sep 17th, Frontier Tower
San Francisco

Link: https://lu.ma/ai-dinner-13.2
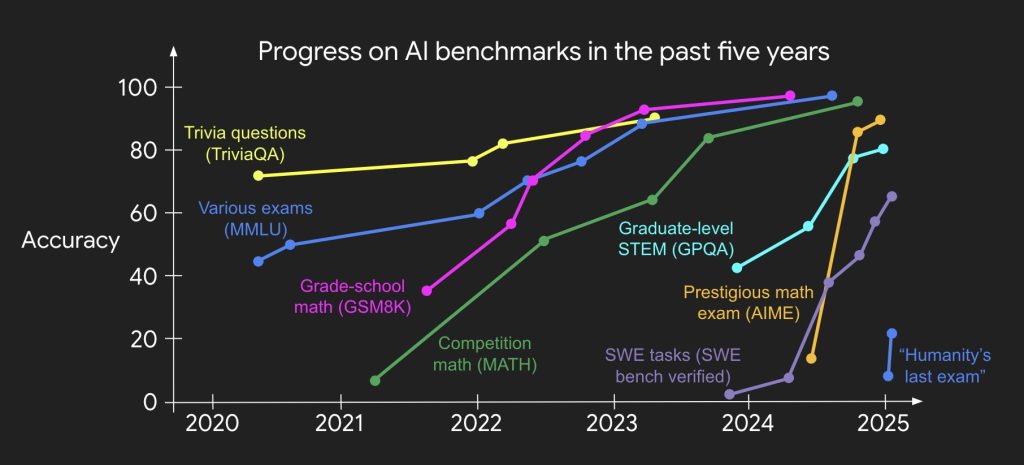
Benchmarks & Metrics
Over the past two years, the AI NY community has been actively reviewing and discussing various benchmarks while tracking the rapid progress of new models. What has become increasingly clear is that most models are heavily overfitted to these benchmarks. As a result, they are less a true measure of real-world performance and more a way to track the pace of new model releases.
| Model | ARC-AGI 1 | ARC-AGI 2 | OpenRouter (this week) | Live Bench (live average) | Humanity’s Last Exam | Average Score |
|---|---|---|---|---|---|---|
| GPT-5 (High) | 65.7% / $0.50 | 9.9% / $0.73 | 62.7B tokens | 77.39 | 25.32 | 44.57 |
| Grok 4 (Thinking) | 66.7% / $1.11 | 16% / $2.17 | 93.1B tokens | 70.32 | N/A | 51.00 |
| Claude Sonnet 4 (Thinking 16K) | 40% / $0.366 | 5.9% / $0.48 | 545B tokens | 71.02 | 7.76 | 31.16 |
| Gemini Flash 2.5 (Thinking 16K) | 33% / $0.21 | %2 / $0.31 | 259B tokens | 64.42 | 12.08 | 27.87 |
| Gemini 2.5 Pro (Thinking 16K) | 41% / $0.484 | %4.0 / $0.72 | 150B tokens | 65.70 | 21.64 | 33.08 |
ARC-AGI 1
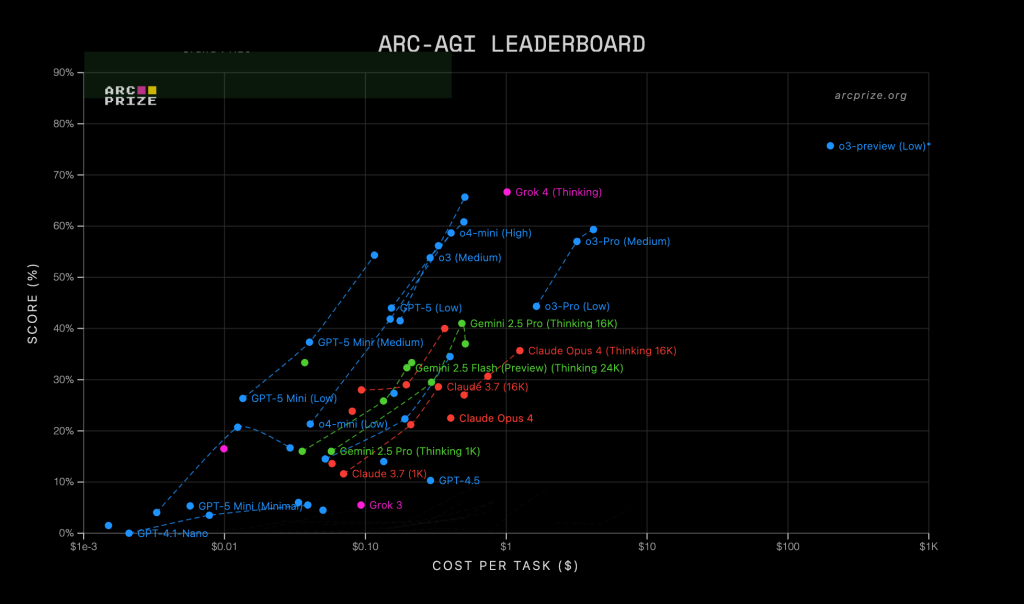
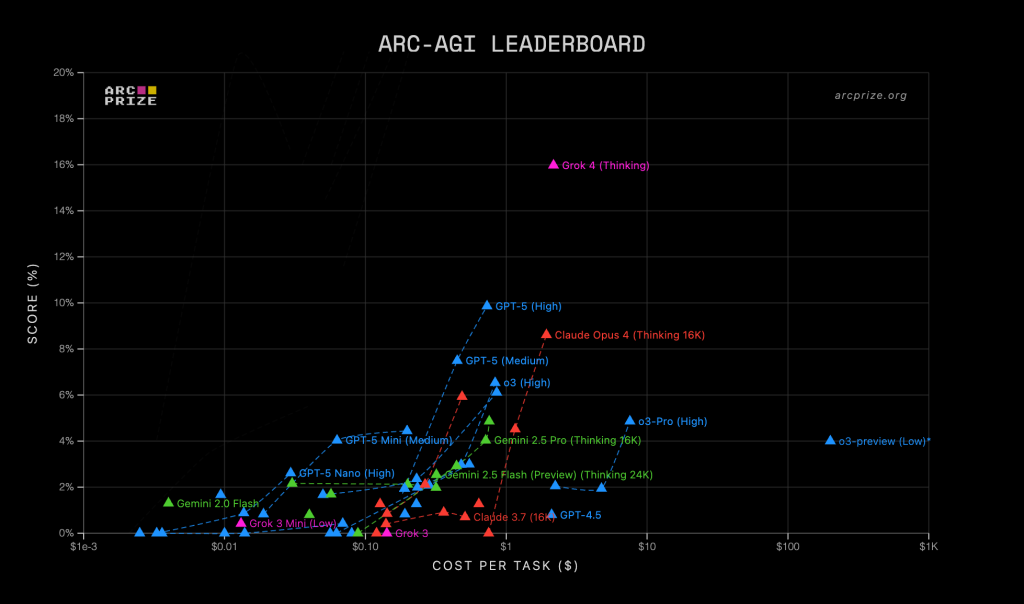
In ARC-AGI 2
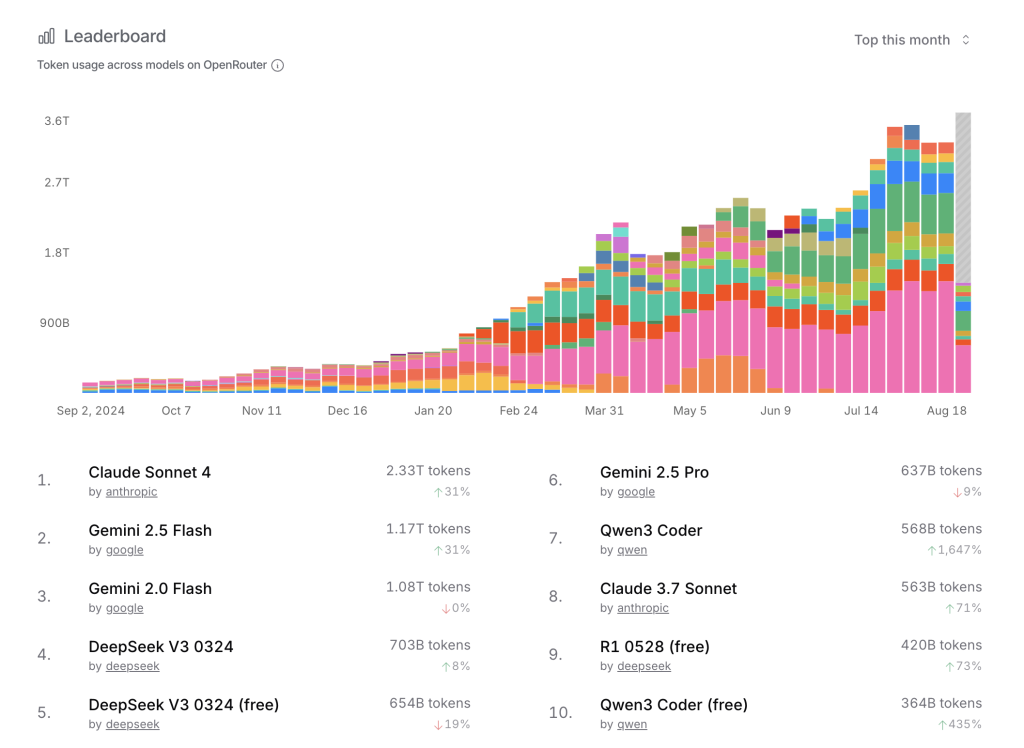
OpenRouter Leaderboard
OpenAI Launches GPT-5 with Advanced Reasoning
OpenAI launched GPT-5 on August 7, 2025, touting "PhD-level intelligence" with built-in advanced reasoning for coding, planning, and agentic tasks. Available to Free, Plus, Pro, and Team users immediately, with Enterprise/Edu following. The rollout faced backlash over glitches, hallucinations, and a "colder" tone, prompting OpenAI to restore legacy models for paid users.
Tweets reflected mixed sentiments, praising coding strengths but criticizing the chaotic debut and emotional impacts, and many missed gpt-4o.
| Category | Metric / Claim | Key Benefit |
|---|---|---|
| Cost Efficiency | 25× cheaper than GPT-4 | Enables wider access (link) |
| Coding Win Rate | 70%+ vs. GPT-4 | Excels in complex tasks (link) |
| Reasoning Boost | 40% improvement over GPT-4 | Better for long chains and tool use |
| Training Scale | 170K-180K H100 GPUs | Massive compute investment for multimodal advancements (link) |
Google Updates
Gemini 2.5 Deep Think
Google launched Gemini 2.5 Deep Think, an advanced reasoning mode in Gemini 2.5 Pro, available to Google AI Ultra subscribers via the Gemini app. It uses parallel thinking and reinforcement learning for better problem-solving, generating and refining hypotheses over time. Strengths include creative projects, science, math, and coding. Activate via "Deep Think" in the prompt bar; limited daily prompts. Integrates tools like code execution and search for detailed, safe responses.
| Benchmark | Score | Notes |
|---|---|---|
| Humanity’s Last Exam | 21.6% | Expert-level; beats predecessors. |
| GPQA (Science) | 86.4% | High accuracy in STEM. |
| AIME 2025 (Math) | 88.0% | Near SOTA. |
| LiveCodeBench (Code) | 69.0% | Outperforms o3, Grok 4. |
| Aider Polyglot | 82.2% | Multi-language edits. |
| SWE-bench | 67.2% | Real-world tasks. |
| MMMU | 82.0% | Multimodal reasoning. |
Genie 3: World Model Enhances AI Environmental Understanding
Genie 3 is a groundbreaking world model that transforms simple text prompts into immersive, interactive virtual environments, you can explore with the direction keys like you would in a video game. This innovation marks a significant leap in how AI comprehends and simulates real-world dynamics, enabling agents to navigate and interact with generated worlds in real time, and remember changes.
It can do 24 fps at 720p for a few minutes. Can generate the world from a single text prompt or image. The action is handled by auto-regressive frame generation based on user trajectories.

Nano-Banana 🍌: Consistent Image Generation Application
AI companies loves fruit, so now is Google’s time with “Nano Banana” the codename for Gemini 2.5 Flash Image, a major upgrade to its Gemini AI suite.
Why is a game changer?
- Consistency Over Everything: Nano Banana shines by ensuring visual elements—faces, pets, objects—remain consistent across multiple edits. It addresses the common “close but no cigar” problem in AI editing .
- Editing, Not Just Generating: Unlike many AI tools, it doesn’t just spawn new images—it excels at nuanced, multi-step edits. Think combining images, modifying existing ones, or transforming backgrounds—all while keeping things coherent .
- Deep Integration Across Platforms: It’s now integrated into both web and mobile versions of the Gemini app, available to free and paid users alike. So yes, everyone gets in on the action.
Nano-Banana already launched and we had the privilege to try it and I can tell you, it deliver what it promises for the image editing, but it's still hallucinate when the image has way too many details.
Blog Posts
The Second Half
This is one of the best blog posts of 2025 by the OpenAI researcher Shunyu Yao. A playbook for what will matter most in AI research and the startup ecosystem, and how to prepare.
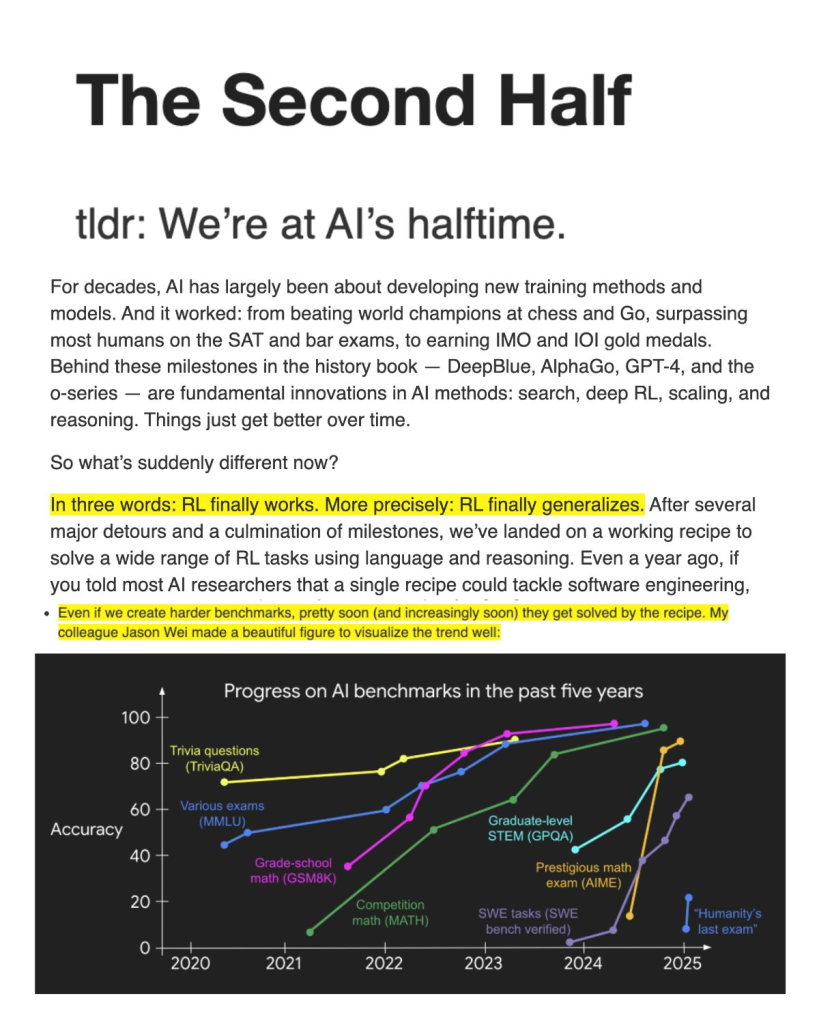
In the first half the focus was on developing new training methods and models. In the second half the focus shift from solving problems to defining problems, and write the correct eval for it.
Reinforcement learning (RL) key components
In RL there 3 main components:
-
Algorithm, the learning rule or optimization method that updates the agent’s policy. This is the machinery of RL: from early methods like REINFORCE and Q-learning, to more advanced ones like actor-critic, PPO, or TRPO. Algorithms define how the agent learns from experience.
-
Environment, the world in which the agent operates. It provides the state, feedback, and reward signals. In research, environments range from toy grids and Atari games to robotics simulators and large-scale language interaction settings. The environment defines what the agent is learning about.
-
And priors, the knowledge the agent brings before any RL begins. Priors can come from pre-training on vast datasets.
For decades, RL researchers obsessed over algorithms—REINFORCE, DQN, TD-learning, actor-critic, PPO, TRPO. Sutton and Barto’s classical textbook is almost entirely about algorithms, with little attention to environments or priors.
That mindset carried into mainstream AI. The first half of the modern AI era was dominated by new training methods and model architectures: AlexNet, the transformer, GPT-3. Then the progress stack on algorithms and models beating benchmarks. But the game changed when RL finally generalized.
The working recipe now looks like this: massive language pre-training (priors) + scale + reasoning-as-action inside a RL loop.
It turned out the most important part of RL might not be the algorithm or the environment, but the priors, which can be obtained in a way totally unrelated from RL.
So now the frontier shifts from solving problems to defining the right problems, evaluation takes center stage, and the core benchmark is no longer a leaderboard score but the “utility problem.” In fact traditional benchmarks don’t translate well to real-world tasks.
This is a great blog post that requires a few reading before really syncing in.
https://x.com/ShunyuYao12/status/1911671943457345675
https://x.com/Hesamation/status/1960717949771092429
Mechanize: How to Fully Automate Software Engineering
Current AI presents the Moravec’s paradox, it finds easy tasks that are really hard for humans (math, coding) and very hard tasks that are easy for humans (a baby chosing the right shape), some people think we can’t get over this paradigm.
The bitter lesson (Richard Sutton) tells us that scale (brute force) can solve this problem. RL is also a solution to this problem but stuck on narrow problems.
This blog argues that full automation needs more than just bigger models, it’s about training on tons of real human coding data and then letting AI learn in rich, realistic environments using RL. Right now, those RL environments are way too basic, and grading open-ended engineering work is tough.
So, AI shifts engineers to higher-level planning, testing, and coordination. And here’s the twist: software engineering might be both the first and last white-collar job to be totally automated, since building a “drop-in remote worker” AI is a much bigger challenge than just writing code.
https://x.com/MechanizeWork/status/1945528661131849790
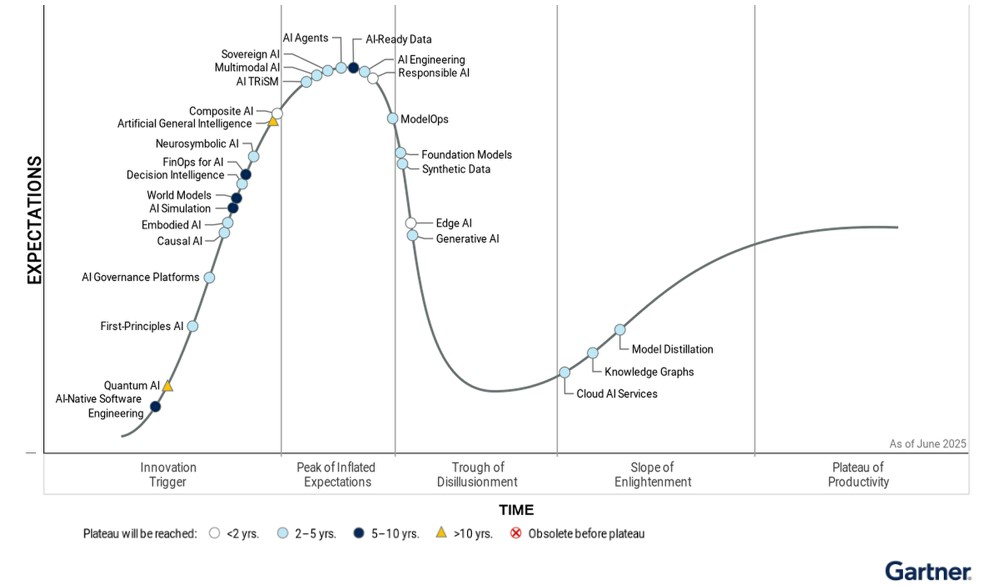
Garnter: AI Hype Cycles
2025 reached the peak of the hype cycle with the AI Agents. Focus is now shifting to delivery stable business applications.
Nic Carter Tweet on AI opportunities and negative effects
Nic think AI is going to increase the Gini coefficient, drawing parallels to the post-1850 horse population drop, foreseeing job disruptions, regulations, and socialist backlash.
The NVDA rally changed the way he's seeing the future investing of AI. He was an early investor in CoreWeave. In 2020 he read the Scaling Hypothesis from Gwern, the most important blog post of that time. 2022 stable diffusion came out.
I'm probably doing a terrible job at summarizing this tweet, so just go read it for yourself: https://x.com/nic__carter/status/1797635177973158182.
Videos And Podcasts
Can Goodness Compete?
A philosophical exploration of a post AGI future Shelling point good for humanity.
https://www.youtube.com/embed/i6RMHcMbqQw
The Fractured Entangled Representation Hypothesis
Current diffusion models train on massive data and create images that happen to be correct, but they’re “castle in the sand”.
https://open.spotify.com/episode/2T75g7BLaztaWSeXWO0G18?si=m7BQkUYcTSGOQuCQRO6Jcg
Instead of building top bottom with SGD. This new models start from bottom up, build the images composing them piece by piece.. they show an example of a skull, and explaining how step by step, representation emerge locking one piece at the time. This is a 15 min summary of the full episode.
Demis Hassabis: Future of AI, Simulating Reality, Physics and Video Games | Lex Fridman Podcast
https://www.youtube.com/watch?v=-HzgcbRXUK8
Demis Hassabis and Lex discuss how AI is modeling complex patterns in nature, the path toward artificial general intelligence (AGI), and the societal impact of rapid technological change. The conversation covers breakthroughs like AlphaFold, the future of video games, the importance of creativity and research “taste,” and the philosophical questions surrounding consciousness and human purpose. Hassabis emphasizes the need for responsible AI development, collaboration, and ensuring that the benefits of these technologies are shared widely.
How AI image generation draws from physics | Guest video by @WelchLabsVideo
https://www.youtube.com/watch?v=iv-5mZ\_9CPY
A geometrical exploration for how diffusion models work 🔥 and how the gradient descent is represented.
MLST — DeepMind Genie 3 - Simulate The World
https://www.youtube.com/watch?v=ekgvWeHidJs&t=604s
MLST interview with the DeepMind Genie 3 team, a general purpose world model that can generate an unprecedented diversity of interactive environments, can create and remember the world details, and it has emergent rules, like parallax. Video games and virtual reality are about to have their GPT moment. It’s a real time model that can render at 30fps and 720p and it can render the world for several minutes.
Theory Of Everything: The (Terrifying) Theory That Your Thoughts Were Never Your Own
https://www.youtube.com/watch?v=Ca\_RbPXraDE
The theory that your thoughts were never yours.. in other words, language is an entity with its own evolution that is injected in our brain, and likely there are other parallel entity (or programs) running in our biology. Does the brain works just like an LLM?
This is a mind bending live discussion and podcast at the University of Toronto, from Prof Elan Barenholtz and William Hahn, moderated by Curt Jaimungal.
Stay Updated
Get the latest AI insights delivered to your inbox. No spam, unsubscribe anytime.
About the Authors

Related Posts

AI Socratic July 2026 — Lost In J-Space
Anthropic’s Fable 5 is back under strict safety rubrics, OpenAI’s launched GPT-5.6, Meta launched Muse Spark 1.1 model and Meta Compute.

AI Socratic June 2026 #2 — Begun the Open Source AI War Has
The second half of June was about AI climbing out of the chat box and into the physical world: Midjourney started scanning bodies, Snap shipped a face computer, SpaceX bought Cursor, and Sakana built a model to command other models. Underneath it all, Dwarkesh Patel named the real bottleneck — the world refuses to be grindable.

AI Socratic June 2026 - Hoist by Its Own Fable
Anthropic shipped Claude Fable 5, its first public Mythos-class model, and 72 hours later a national-security directive pulled it offline worldwide. A company that spent the month lobbying to keep frontier AI pausable got its own pause, on schedule. Around it: new models from nearly everyone, a couple of S-1s, real math from the machines, and the usual carnival of vibe-coding pivots and rogue Waymos.